 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaptive Data Flywheel: Applying MAPE Control Loops to AI Agent Improvement
Oct 30, 2025Enterprise AI agents must continuously adapt to maintain accuracy, reduce latency, and remain aligned with user needs. We present a practical implementation of a data flywheel in NVInfo AI, NVIDIA's Mixture-of-Experts (MoE) Knowledge Assistant serving over 30,000 employees. By operationalizing a MAPE-driven data flywheel, we built a closed-loop system that systematically addresses failures in retrieval-augmented generation (RAG) pipelines and enables continuous learning. Over a 3-month post-deployment period, we monitored feedback and collected 495 negative samples. Analysis revealed two major failure modes: routing errors (5.25\%) and query rephrasal errors (3.2\%). Using NVIDIA NeMo microservices, we implemented targeted improvements through fine-tuning. For routing, we replaced a Llama 3.1 70B model with a fine-tuned 8B variant, achieving 96\% accuracy, a 10x reduction in model size, and 70\% latency improvement. For query rephrasal, fine-tuning yielded a 3.7\% gain in accuracy and a 40\% latency reduction. Our approach demonstrates how human-in-the-loop (HITL) feedback, when structured within a data flywheel, transforms enterprise AI agents into self-improving systems. Key learnings include approaches to ensure agent robustness despite limited user feedback, navigating privacy constraints, and executing staged rollouts in production. This work offers a repeatable blueprint for building robust, adaptive enterprise AI agents capable of learning from real-world usage at scale.
Sparse Reconstruction of Optical Doppler Tomography Based on State Space Model
Apr 26, 2024



Optical Doppler Tomography (ODT) is a blood flow imaging technique popularly used in bioengineering applications. The fundamental unit of ODT is the 1D frequency response along the A-line (depth), named raw A-scan. A 2D ODT image (B-scan) is obtained by first sensing raw A-scans along the B-line (width), and then constructing the B-scan from these raw A-scans via magnitude-phase analysis and post-processing. To obtain a high-resolution B-scan with a precise flow map, densely sampled A-scans are required in current methods, causing both computational and storage burdens. To address this issue, in this paper we propose a novel sparse reconstruction framework with four main sequential steps: 1) early magnitude-phase fusion that encourages rich interaction of the complementary information in magnitude and phase, 2) State Space Model (SSM)-based representation learning, inspired by recent successes in Mamba and VMamba, to naturally capture both the intra-A-scan sequential information and between-A-scan interactions, 3) an Inception-based Feedforward Network module (IncFFN) to further boost the SSM-module, and 4) a B-line Pixel Shuffle (BPS) layer to effectively reconstruct the final results. In the experiments on real-world animal data, our method shows clear effectiveness in reconstruction accuracy. As the first application of SSM for image reconstruction tasks, we expect our work to inspire related explorations in not only efficient ODT imaging techniques but also generic image enhancement.
Federated Learning of Large Language Models with Parameter-Efficient Prompt Tuning and Adaptive Optimization
Oct 29, 2023



Federated learning (FL) is a promising paradigm to enable collaborative model training with decentralized data. However, the training process of Large Language Models (LLMs) generally incurs the update of significant parameters, which limits the applicability of FL techniques to tackle the LLMs in real scenarios. Prompt tuning can significantly reduce the number of parameters to update, but it either incurs performance degradation or low training efficiency. The straightforward utilization of prompt tuning in the FL often raises non-trivial communication costs and dramatically degrades performance. In addition, the decentralized data is generally non-Independent and Identically Distributed (non-IID), which brings client drift problems and thus poor performance. This paper proposes a Parameter-efficient prompt Tuning approach with Adaptive Optimization, i.e., FedPepTAO, to enable efficient and effective FL of LLMs. First, an efficient partial prompt tuning approach is proposed to improve performance and efficiency simultaneously. Second, a novel adaptive optimization method is developed to address the client drift problems on both the device and server sides to enhance performance further. Extensive experiments based on 10 datasets demonstrate the superb performance (up to 60.8\% in terms of accuracy) and efficiency (up to 97.59\% in terms of training time) of FedPepTAO compared with 9 baseline approaches. Our code is available at https://github.com/llm-eff/FedPepTAO.
Accelerated Federated Learning with Decoupled Adaptive Optimization
Jul 14, 2022
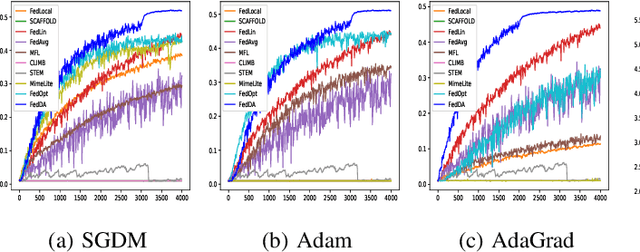
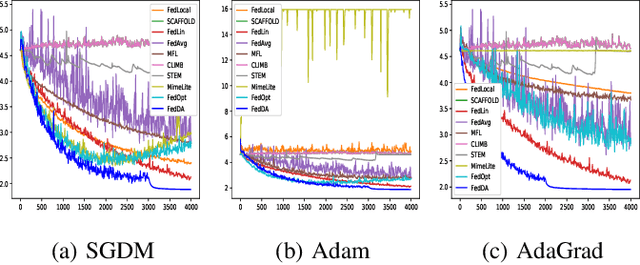
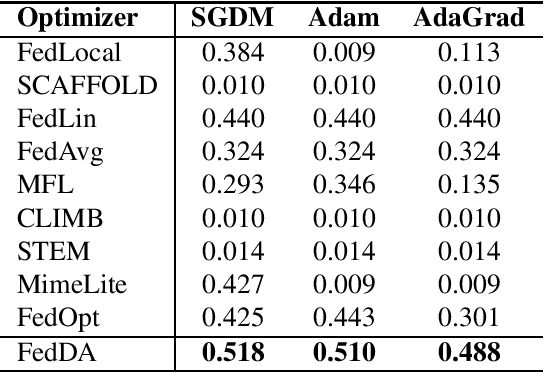
The federated learning (FL) framework enables edge clients to collaboratively learn a shared inference model while keeping privacy of training data on clients. Recently, many heuristics efforts have been made to generalize centralized adaptive optimization methods, such as SGDM, Adam, AdaGrad, etc., to federated settings for improving convergence and accuracy. However, there is still a paucity of theoretical principles on where to and how to design and utilize adaptive optimization methods in federated settings. This work aims to develop novel adaptive optimization methods for FL from the perspective of dynamics of ordinary differential equations (ODEs). First, an analytic framework is established to build a connection between federated optimization methods and decompositions of ODEs of corresponding centralized optimizers. Second, based on this analytic framework, a momentum decoupling adaptive optimization method, FedDA, is developed to fully utilize the global momentum on each local iteration and accelerate the training convergence. Last but not least, full batch gradients are utilized to mimic centralized optimization in the end of the training process to ensure the convergence and overcome the possible inconsistency caused by adaptive optimization methods.
Self-Supervised Bulk Motion Artifact Removal in Optical Coherence Tomography Angiography
Mar 27, 2022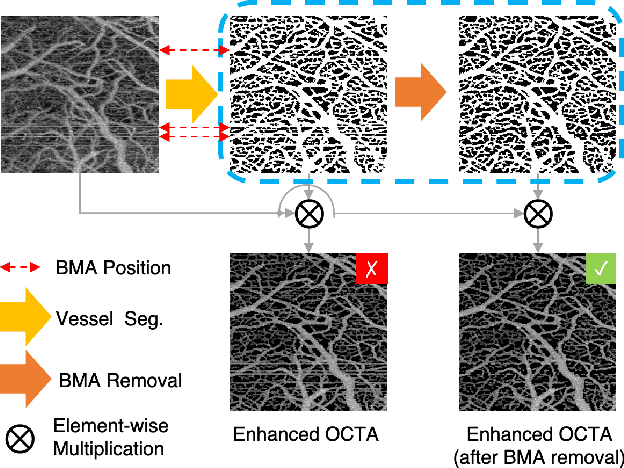
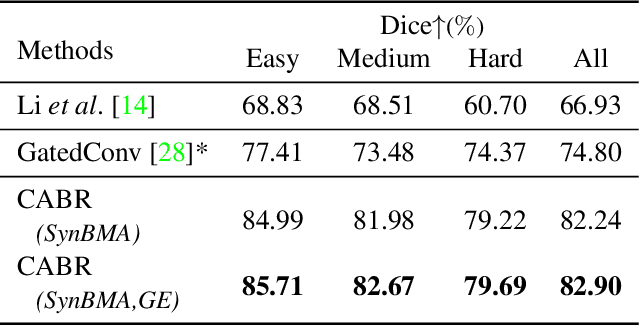
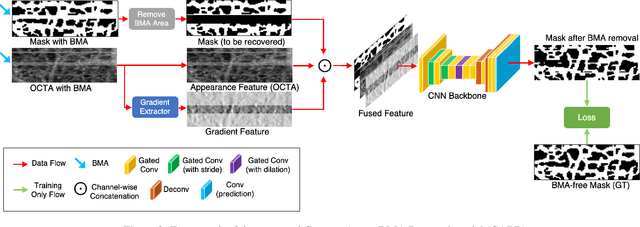
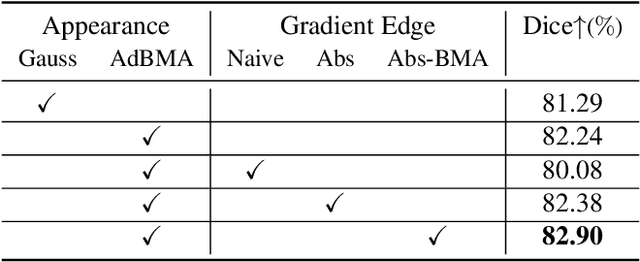
Optical coherence tomography angiography (OCTA) is an important imaging modality in many bioengineering tasks. The image quality of OCTA, however, is often degraded by Bulk Motion Artifacts (BMA), which are due to micromotion of subjects and typically appear as bright stripes surrounded by blurred areas. State-of-the-art methods usually treat BMA removal as a learning-based image inpainting problem, but require numerous training samples with nontrivial annotation. In addition, these methods discard the rich structural and appearance information carried in the BMA stripe region. To address these issues, in this paper we propose a self-supervised content-aware BMA removal model. First, the gradient-based structural information and appearance feature are extracted from the BMA area and injected into the model to capture more connectivity. Second, with easily collected defective masks, the model is trained in a self-supervised manner, in which only the clear areas are used for training while the BMA areas for inference. With the structural information and appearance feature from noisy image as references, our model can remove larger BMA and produce better visualizing result. In addition, only 2D images with defective masks are involved, hence improving the efficiency of our method. Experiments on OCTA of mouse cortex demonstrate that our model can remove most BMA with extremely large sizes and inconsistent intensities while previous methods fail.
Osteoporosis Prescreening using Panoramic Radiographs through a Deep Convolutional Neural Network with Attention Mechanism
Oct 19, 2021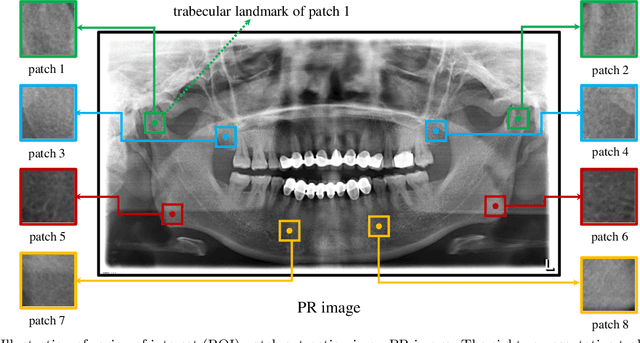
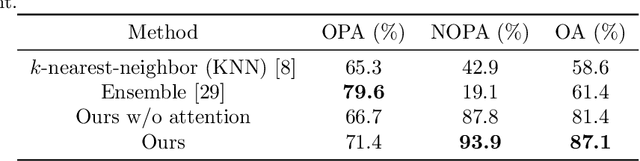
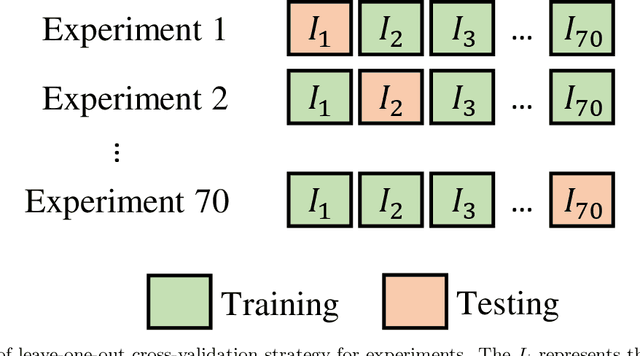
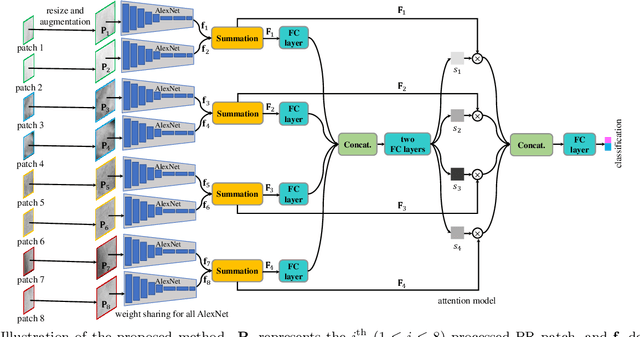
Objectives. The aim of this study was to investigate whether a deep convolutional neural network (CNN) with an attention module can detect osteoporosis on panoramic radiographs. Study Design. A dataset of 70 panoramic radiographs (PRs) from 70 different subjects of age between 49 to 60 was used, including 49 subjects with osteoporosis and 21 normal subjects. We utilized the leave-one-out cross-validation approach to generate 70 training and test splits. Specifically, for each split, one image was used for testing and the remaining 69 images were used for training. A deep convolutional neural network (CNN) using the Siamese architecture was implemented through a fine-tuning process to classify an PR image using patches extracted from eight representative trabecula bone areas (Figure 1). In order to automatically learn the importance of different PR patches, an attention module was integrated into the deep CNN. Three metrics, including osteoporosis accuracy (OPA), non-osteoporosis accuracy (NOPA) and overall accuracy (OA), were utilized for performance evaluation. Results. The proposed baseline CNN approach achieved the OPA, NOPA and OA scores of 0.667, 0.878 and 0.814, respectively. With the help of the attention module, the OPA, NOPA and OA scores were further improved to 0.714, 0.939 and 0.871, respectively. Conclusions. The proposed method obtained promising results using deep CNN with an attention module, which might be applied to osteoporosis prescreening.