 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLarge-scale Knowledge Distillation with Elastic Heterogeneous Computing Resources
Paper and Code
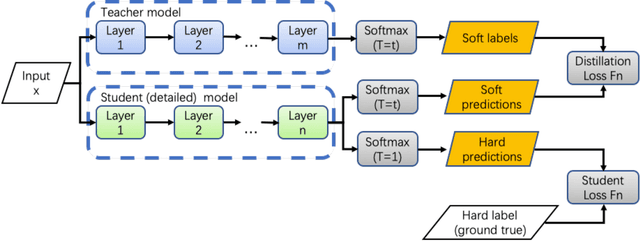

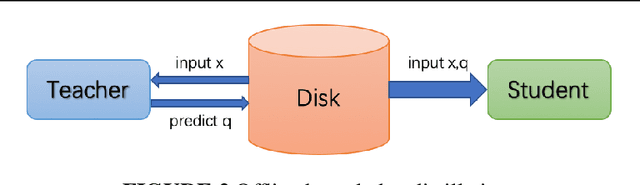
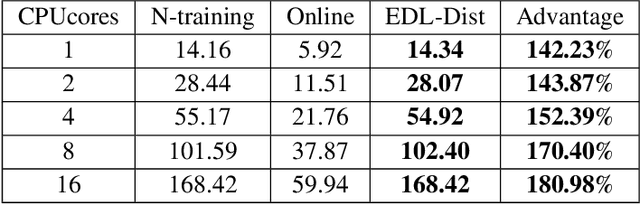
Although more layers and more parameters generally improve the accuracy of the models, such big models generally have high computational complexity and require big memory, which exceed the capacity of small devices for inference and incurs long training time. In addition, it is difficult to afford long training time and inference time of big models even in high performance servers, as well. As an efficient approach to compress a large deep model (a teacher model) to a compact model (a student model), knowledge distillation emerges as a promising approach to deal with the big models. Existing knowledge distillation methods cannot exploit the elastic available computing resources and correspond to low efficiency. In this paper, we propose an Elastic Deep Learning framework for knowledge Distillation, i.e., EDL-Dist. The advantages of EDL-Dist are three-fold. First, the inference and the training process is separated. Second, elastic available computing resources can be utilized to improve the efficiency. Third, fault-tolerance of the training and inference processes is supported. We take extensive experimentation to show that the throughput of EDL-Dist is up to 3.125 times faster than the baseline method (online knowledge distillation) while the accuracy is similar or higher.