 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnrewarded Exploration in Large Language Models Reveals Latent Learning from Psychology
Jan 30, 2026Latent learning, classically theorized by Tolman, shows that biological agents (e.g., rats) can acquire internal representations of their environment without rewards, enabling rapid adaptation once rewards are introduced. In contrast, from a cognitive science perspective, reward learning remains overly dependent on external feedback, limiting flexibility and generalization. Although recent advances in the reasoning capabilities of large language models (LLMs), such as OpenAI-o1 and DeepSeek-R1, mark a significant breakthrough, these models still rely primarily on reward-centric reinforcement learning paradigms. Whether and how the well-established phenomenon of latent learning in psychology can inform or emerge within LLMs' training remains largely unexplored. In this work, we present novel findings from our experiments that LLMs also exhibit the latent learning dynamics. During an initial phase of unrewarded exploration, LLMs display modest performance improvements, as this phase allows LLMs to organize task-relevant knowledge without being constrained by reward-driven biases, and performance is further enhanced once rewards are introduced. LLMs post-trained under this two-stage exploration regime ultimately achieve higher competence than those post-trained with reward-based reinforcement learning throughout. Beyond these empirical observations, we also provide theoretical analyses for our experiments explaining why unrewarded exploration yields performance gains, offering a mechanistic account of these dynamics. Specifically, we conducted extensive experiments across multiple model families and diverse task domains to establish the existence of the latent learning dynamics in LLMs.
OmegaUse: Building a General-Purpose GUI Agent for Autonomous Task Execution
Jan 28, 2026Graphical User Interface (GUI) agents show great potential for enabling foundation models to complete real-world tasks, revolutionizing human-computer interaction and improving human productivity. In this report, we present OmegaUse, a general-purpose GUI agent model for autonomous task execution on both mobile and desktop platforms, supporting computer-use and phone-use scenarios. Building an effective GUI agent model relies on two factors: (1) high-quality data and (2) effective training methods. To address these, we introduce a carefully engineered data-construction pipeline and a decoupled training paradigm. For data construction, we leverage rigorously curated open-source datasets and introduce a novel automated synthesis framework that integrates bottom-up autonomous exploration with top-down taxonomy-guided generation to create high-fidelity synthetic data. For training, to better leverage these data, we adopt a two-stage strategy: Supervised Fine-Tuning (SFT) to establish fundamental interaction syntax, followed by Group Relative Policy Optimization (GRPO) to improve spatial grounding and sequential planning. To balance computational efficiency with agentic reasoning capacity, OmegaUse is built on a Mixture-of-Experts (MoE) backbone. To evaluate cross-terminal capabilities in an offline setting, we introduce OS-Nav, a benchmark suite spanning multiple operating systems: ChiM-Nav, targeting Chinese Android mobile environments, and Ubu-Nav, focusing on routine desktop interactions on Ubuntu. Extensive experiments show that OmegaUse is highly competitive across established GUI benchmarks, achieving a state-of-the-art (SOTA) score of 96.3% on ScreenSpot-V2 and a leading 79.1% step success rate on AndroidControl. OmegaUse also performs strongly on OS-Nav, reaching 74.24% step success on ChiM-Nav and 55.9% average success on Ubu-Nav.
TimeFound: A Foundation Model for Time Series Forecasting
Mar 06, 2025



We present TimeFound, an encoder-decoder transformer-based time series foundation model for out-of-the-box zero-shot forecasting. To handle time series data from various domains, TimeFound employs a multi-resolution patching strategy to capture complex temporal patterns at multiple scales. We pre-train our model with two sizes (200M and 710M parameters) on a large time-series corpus comprising both real-world and synthetic datasets. Over a collection of unseen datasets across diverse domains and forecasting horizons, our empirical evaluations suggest that TimeFound can achieve superior or competitive zero-shot forecasting performance, compared to state-of-the-art time series foundation models.
SDWPF: A Dataset for Spatial Dynamic Wind Power Forecasting Challenge at KDD Cup 2022
Aug 08, 2022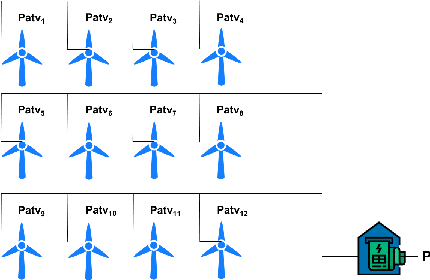


The variability of wind power supply can present substantial challenges to incorporating wind power into a grid system. Thus, Wind Power Forecasting (WPF) has been widely recognized as one of the most critical issues in wind power integration and operation. There has been an explosion of studies on wind power forecasting problems in the past decades. Nevertheless, how to well handle the WPF problem is still challenging, since high prediction accuracy is always demanded to ensure grid stability and security of supply. We present a unique Spatial Dynamic Wind Power Forecasting dataset: SDWPF, which includes the spatial distribution of wind turbines, as well as the dynamic context factors. Whereas, most of the existing datasets have only a small number of wind turbines without knowing the locations and context information of wind turbines at a fine-grained time scale. By contrast, SDWPF provides the wind power data of 134 wind turbines from a wind farm over half a year with their relative positions and internal statuses. We use this dataset to launch the Baidu KDD Cup 2022 to examine the limit of current WPF solutions. The dataset is released at https://aistudio.baidu.com/aistudio/competition/detail/152/0/datasets.