 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDynamic Neural Representational Decoders for High-Resolution Semantic Segmentation
Jul 30, 2021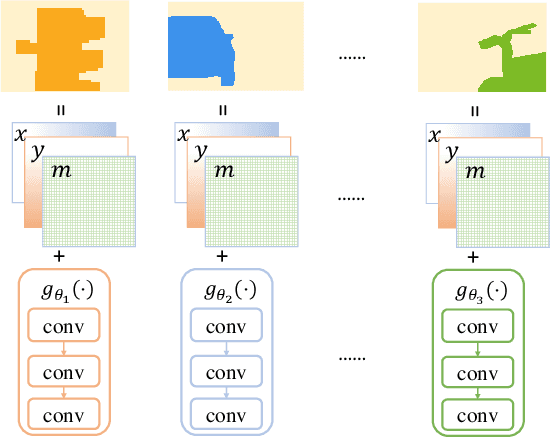

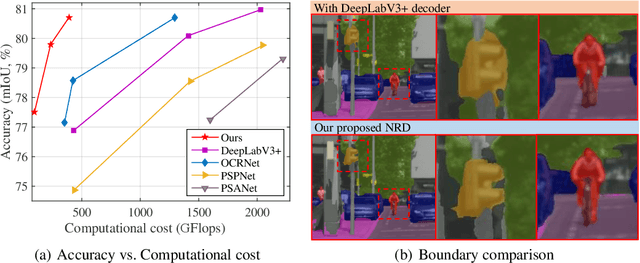

Semantic segmentation requires per-pixel prediction for a given image. Typically, the output resolution of a segmentation network is severely reduced due to the downsampling operations in the CNN backbone. Most previous methods employ upsampling decoders to recover the spatial resolution. Various decoders were designed in the literature. Here, we propose a novel decoder, termed dynamic neural representational decoder (NRD), which is simple yet significantly more efficient. As each location on the encoder's output corresponds to a local patch of the semantic labels, in this work, we represent these local patches of labels with compact neural networks. This neural representation enables our decoder to leverage the smoothness prior in the semantic label space, and thus makes our decoder more efficient. Furthermore, these neural representations are dynamically generated and conditioned on the outputs of the encoder networks. The desired semantic labels can be efficiently decoded from the neural representations, resulting in high-resolution semantic segmentation predictions. We empirically show that our proposed decoder can outperform the decoder in DeeplabV3+ with only 30% computational complexity, and achieve competitive performance with the methods using dilated encoders with only 15% computation. Experiments on the Cityscapes, ADE20K, and PASCAL Context datasets demonstrate the effectiveness and efficiency of our proposed method.
Dynamic Convolution for 3D Point Cloud Instance Segmentation
Jul 18, 2021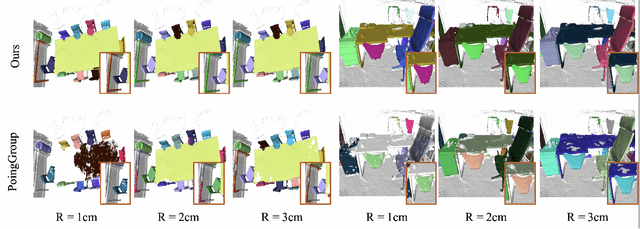
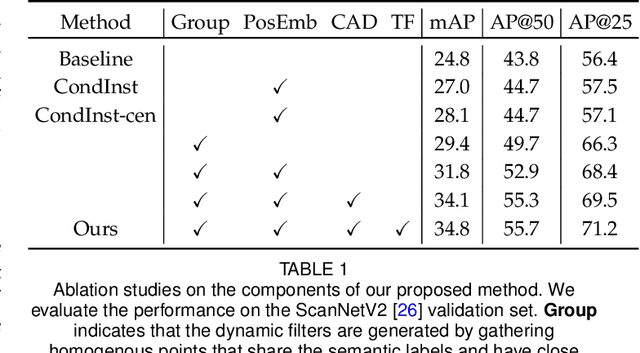

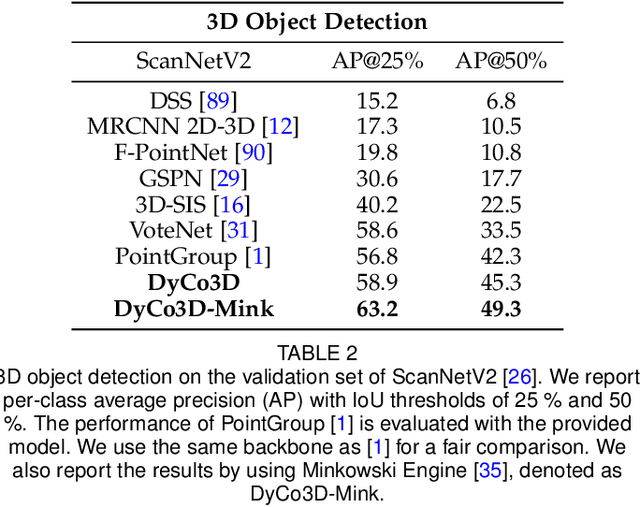
We propose an approach to instance segmentation from 3D point clouds based on dynamic convolution. This enables it to adapt, at inference, to varying feature and object scales. Doing so avoids some pitfalls of bottom up approaches, including a dependence on hyper-parameter tuning and heuristic post-processing pipelines to compensate for the inevitable variability in object sizes, even within a single scene. The representation capability of the network is greatly improved by gathering homogeneous points that have identical semantic categories and close votes for the geometric centroids. Instances are then decoded via several simple convolution layers, where the parameters are generated conditioned on the input. The proposed approach is proposal-free, and instead exploits a convolution process that adapts to the spatial and semantic characteristics of each instance. A light-weight transformer, built on the bottleneck layer, allows the model to capture long-range dependencies, with limited computational overhead. The result is a simple, efficient, and robust approach that yields strong performance on various datasets: ScanNetV2, S3DIS, and PartNet. The consistent improvements on both voxel- and point-based architectures imply the effectiveness of the proposed method. Code is available at: https://git.io/DyCo3D
SOLO: A Simple Framework for Instance Segmentation
Jun 30, 2021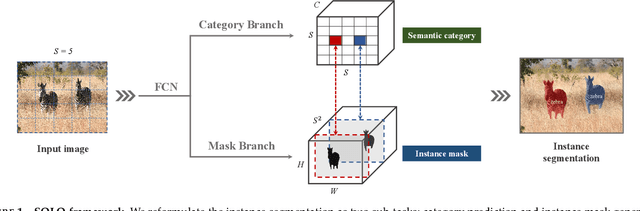
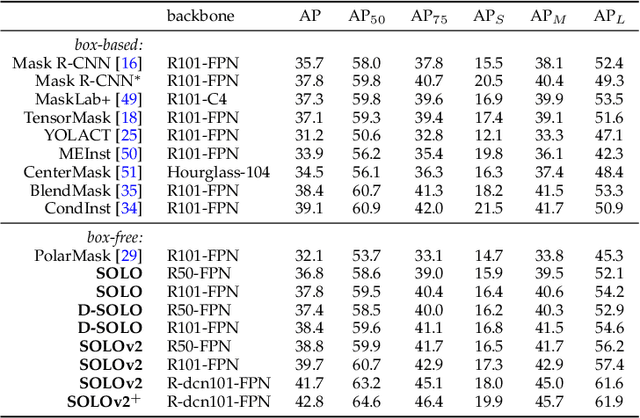
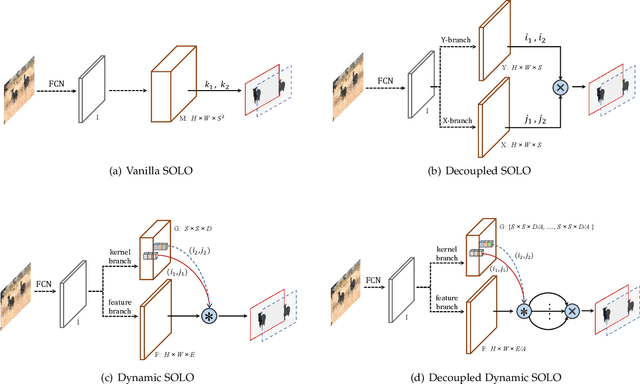

Compared to many other dense prediction tasks, e.g., semantic segmentation, it is the arbitrary number of instances that has made instance segmentation much more challenging. In order to predict a mask for each instance, mainstream approaches either follow the 'detect-then-segment' strategy (e.g., Mask R-CNN), or predict embedding vectors first then cluster pixels into individual instances. In this paper, we view the task of instance segmentation from a completely new perspective by introducing the notion of "instance categories", which assigns categories to each pixel within an instance according to the instance's location. With this notion, we propose segmenting objects by locations (SOLO), a simple, direct, and fast framework for instance segmentation with strong performance. We derive a few SOLO variants (e.g., Vanilla SOLO, Decoupled SOLO, Dynamic SOLO) following the basic principle. Our method directly maps a raw input image to the desired object categories and instance masks, eliminating the need for the grouping post-processing or the bounding box detection. Our approach achieves state-of-the-art results for instance segmentation in terms of both speed and accuracy, while being considerably simpler than the existing methods. Besides instance segmentation, our method yields state-of-the-art results in object detection (from our mask byproduct) and panoptic segmentation. We further demonstrate the flexibility and high-quality segmentation of SOLO by extending it to perform one-stage instance-level image matting. Code is available at: https://git.io/AdelaiDet
ABCNet v2: Adaptive Bezier-Curve Network for Real-time End-to-end Text Spotting
May 29, 2021
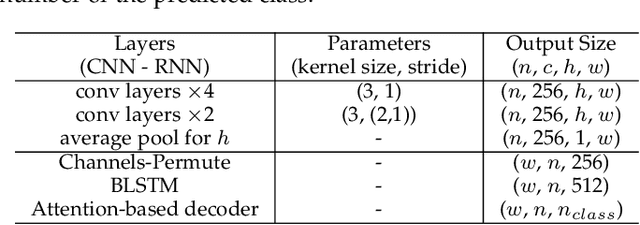


End-to-end text-spotting, which aims to integrate detection and recognition in a unified framework, has attracted increasing attention due to its simplicity of the two complimentary tasks. It remains an open problem especially when processing arbitrarily-shaped text instances. Previous methods can be roughly categorized into two groups: character-based and segmentation-based, which often require character-level annotations and/or complex post-processing due to the unstructured output. Here, we tackle end-to-end text spotting by presenting Adaptive Bezier Curve Network v2 (ABCNet v2). Our main contributions are four-fold: 1) For the first time, we adaptively fit arbitrarily-shaped text by a parameterized Bezier curve, which, compared with segmentation-based methods, can not only provide structured output but also controllable representation. 2) We design a novel BezierAlign layer for extracting accurate convolution features of a text instance of arbitrary shapes, significantly improving the precision of recognition over previous methods. 3) Different from previous methods, which often suffer from complex post-processing and sensitive hyper-parameters, our ABCNet v2 maintains a simple pipeline with the only post-processing non-maximum suppression (NMS). 4) As the performance of text recognition closely depends on feature alignment, ABCNet v2 further adopts a simple yet effective coordinate convolution to encode the position of the convolutional filters, which leads to a considerable improvement with negligible computation overhead. Comprehensive experiments conducted on various bilingual (English and Chinese) benchmark datasets demonstrate that ABCNet v2 can achieve state-of-the-art performance while maintaining very high efficiency.
FCPose: Fully Convolutional Multi-Person Pose Estimation with Dynamic Instance-Aware Convolutions
May 29, 2021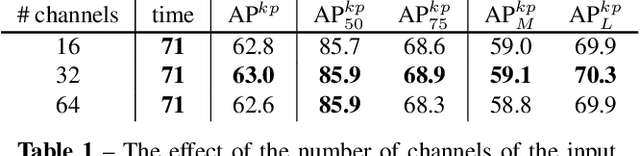
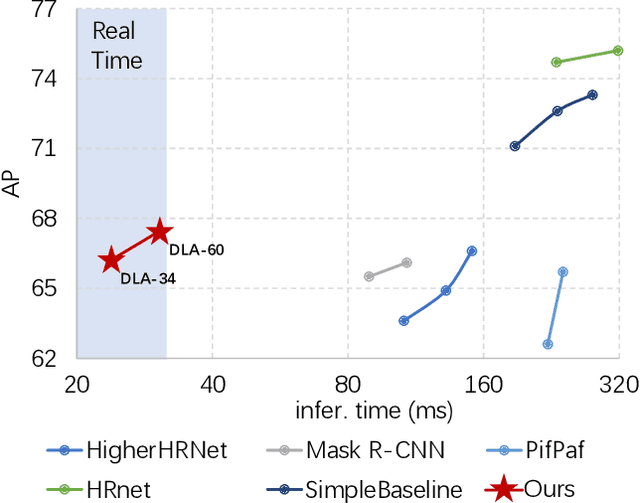
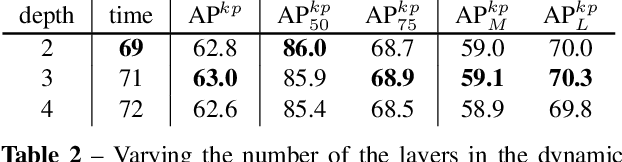
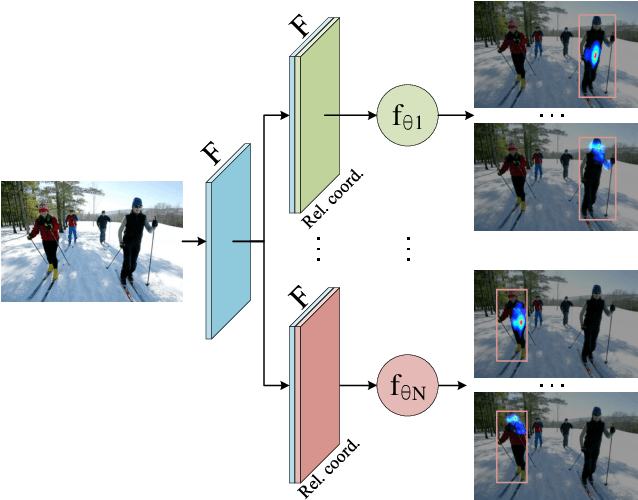
We propose a fully convolutional multi-person pose estimation framework using dynamic instance-aware convolutions, termed FCPose. Different from existing methods, which often require ROI (Region of Interest) operations and/or grouping post-processing, FCPose eliminates the ROIs and grouping post-processing with dynamic instance-aware keypoint estimation heads. The dynamic keypoint heads are conditioned on each instance (person), and can encode the instance concept in the dynamically-generated weights of their filters. Moreover, with the strong representation capacity of dynamic convolutions, the keypoint heads in FCPose are designed to be very compact, resulting in fast inference and making FCPose have almost constant inference time regardless of the number of persons in the image. For example, on the COCO dataset, a real-time version of FCPose using the DLA-34 backbone infers about 4.5x faster than Mask R-CNN (ResNet-101) (41.67 FPS vs. 9.26FPS) while achieving improved performance. FCPose also offers better speed/accuracy trade-off than other state-of-the-art methods. Our experiment results show that FCPose is a simple yet effective multi-person pose estimation framework. Code is available at: https://git.io/AdelaiDet
Unsupervised Scale-consistent Depth Learning from Video
May 25, 2021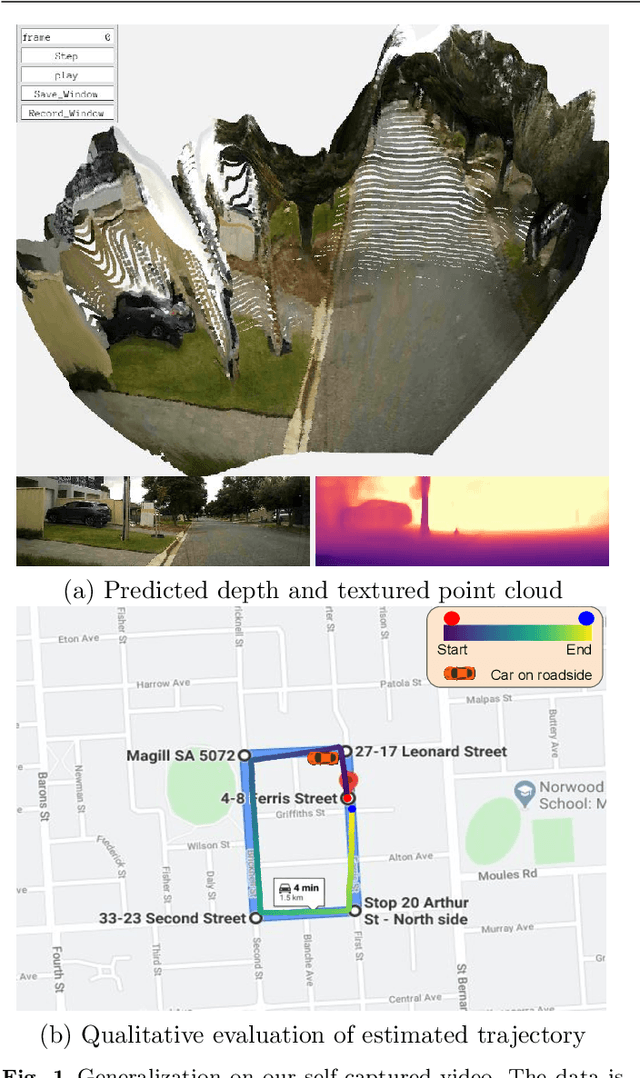
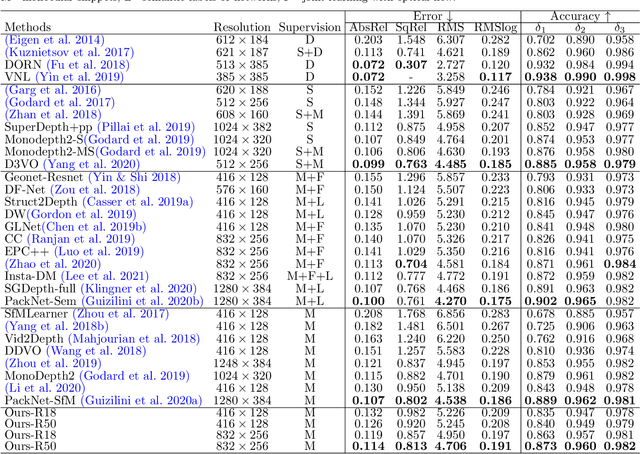
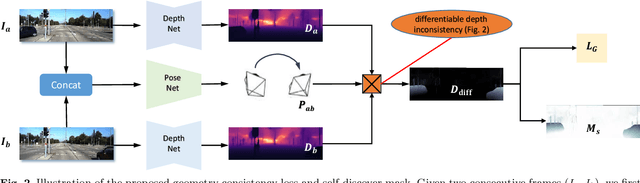
We propose a monocular depth estimator SC-Depth, which requires only unlabelled videos for training and enables the scale-consistent prediction at inference time. Our contributions include: (i) we propose a geometry consistency loss, which penalizes the inconsistency of predicted depths between adjacent views; (ii) we propose a self-discovered mask to automatically localize moving objects that violate the underlying static scene assumption and cause noisy signals during training; (iii) we demonstrate the efficacy of each component with a detailed ablation study and show high-quality depth estimation results in both KITTI and NYUv2 datasets. Moreover, thanks to the capability of scale-consistent prediction, we show that our monocular-trained deep networks are readily integrated into the ORB-SLAM2 system for more robust and accurate tracking. The proposed hybrid Pseudo-RGBD SLAM shows compelling results in KITTI, and it generalizes well to the KAIST dataset without additional training. Finally, we provide several demos for qualitative evaluation.
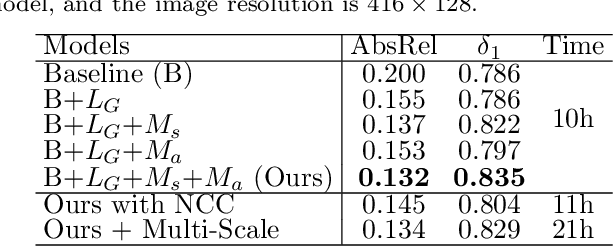
HCRF-Flow: Scene Flow from Point Clouds with Continuous High-order CRFs and Position-aware Flow Embedding
May 17, 2021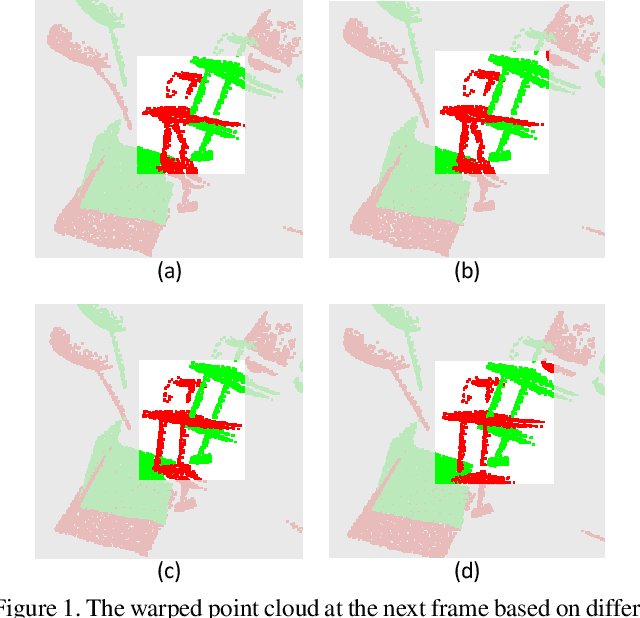
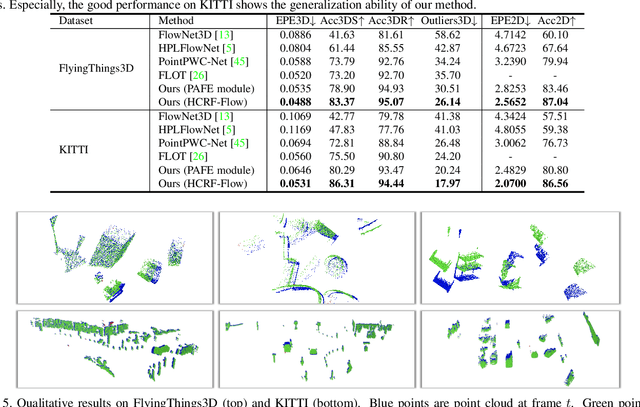
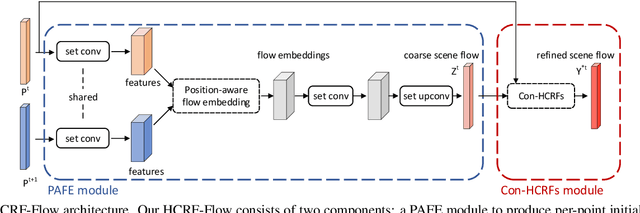
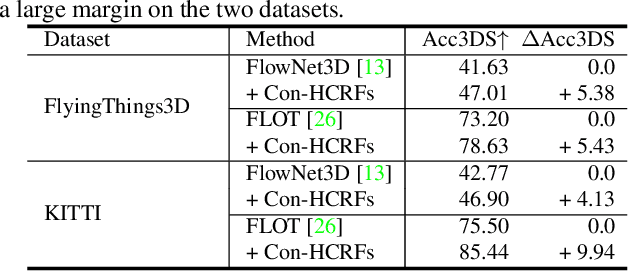
Scene flow in 3D point clouds plays an important role in understanding dynamic environments. Although significant advances have been made by deep neural networks, the performance is far from satisfactory as only per-point translational motion is considered, neglecting the constraints of the rigid motion in local regions. To address the issue, we propose to introduce the motion consistency to force the smoothness among neighboring points. In addition, constraints on the rigidity of the local transformation are also added by sharing unique rigid motion parameters for all points within each local region. To this end, a high-order CRFs based relation module (Con-HCRFs) is deployed to explore both point-wise smoothness and region-wise rigidity. To empower the CRFs to have a discriminative unary term, we also introduce a position-aware flow estimation module to be incorporated into the Con-HCRFs. Comprehensive experiments on FlyingThings3D and KITTI show that our proposed framework (HCRF-Flow) achieves state-of-the-art performance and significantly outperforms previous approaches substantially.
Twins: Revisiting the Design of Spatial Attention in Vision Transformers
May 11, 2021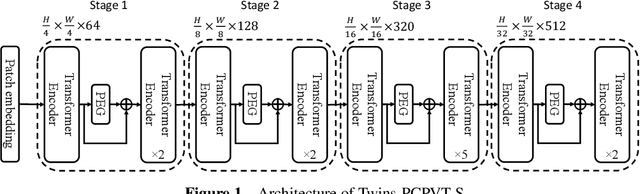
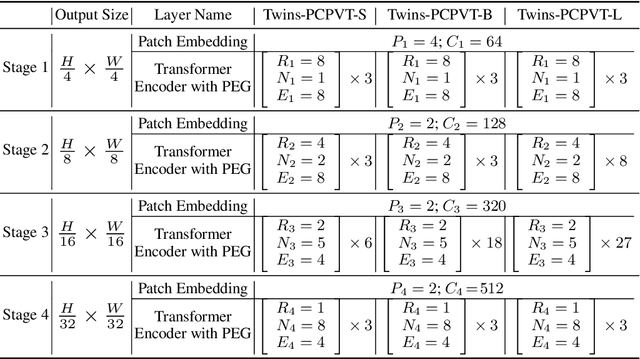
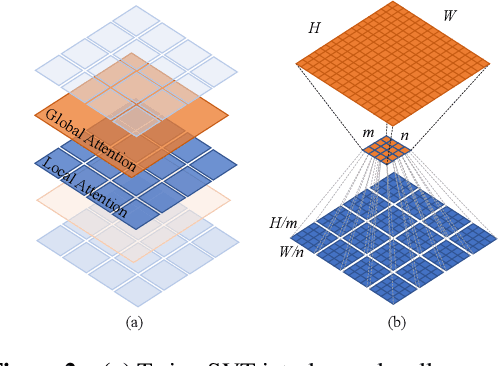
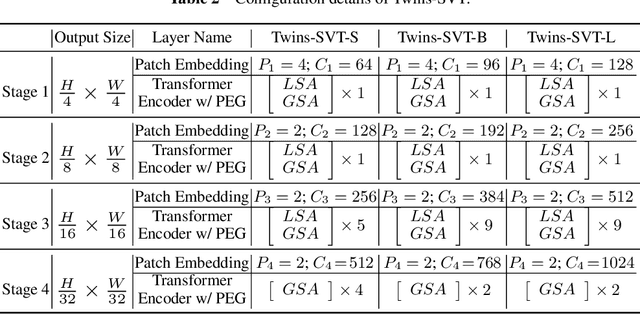
Very recently, a variety of vision transformer architectures for dense prediction tasks have been proposed and they show that the design of spatial attention is critical to their success in these tasks. In this work, we revisit the design of the spatial attention and demonstrate that a carefully-devised yet simple spatial attention mechanism performs favourably against the state-of-the-art schemes. As a result, we propose two vision transformer architectures, namely, Twins-PCPVT and Twins-SVT. Our proposed architectures are highly-efficient and easy to implement, only involving matrix multiplications that are highly optimized in modern deep learning frameworks. More importantly, the proposed architectures achieve excellent performance on a wide range of visual tasks including imagelevel classification as well as dense detection and segmentation. The simplicity and strong performance suggest that our proposed architectures may serve as stronger backbones for many vision tasks. Our code will be released soon at https://github.com/Meituan-AutoML/Twins .
PAN++: Towards Efficient and Accurate End-to-End Spotting of Arbitrarily-Shaped Text
May 09, 2021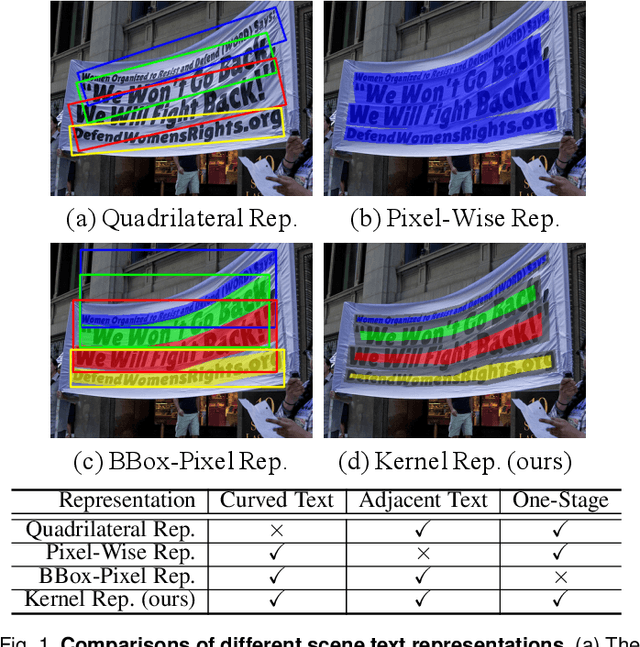
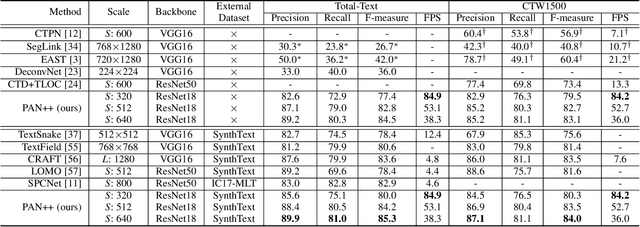
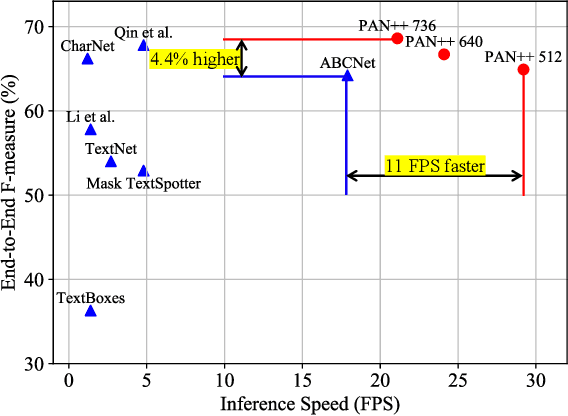
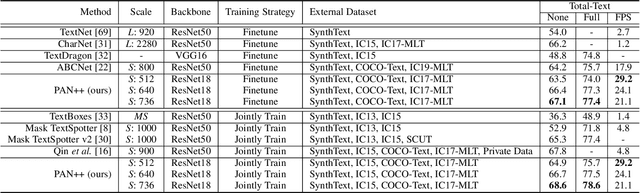
Scene text detection and recognition have been well explored in the past few years. Despite the progress, efficient and accurate end-to-end spotting of arbitrarily-shaped text remains challenging. In this work, we propose an end-to-end text spotting framework, termed PAN++, which can efficiently detect and recognize text of arbitrary shapes in natural scenes. PAN++ is based on the kernel representation that reformulates a text line as a text kernel (central region) surrounded by peripheral pixels. By systematically comparing with existing scene text representations, we show that our kernel representation can not only describe arbitrarily-shaped text but also well distinguish adjacent text. Moreover, as a pixel-based representation, the kernel representation can be predicted by a single fully convolutional network, which is very friendly to real-time applications. Taking the advantages of the kernel representation, we design a series of components as follows: 1) a computationally efficient feature enhancement network composed of stacked Feature Pyramid Enhancement Modules (FPEMs); 2) a lightweight detection head cooperating with Pixel Aggregation (PA); and 3) an efficient attention-based recognition head with Masked RoI. Benefiting from the kernel representation and the tailored components, our method achieves high inference speed while maintaining competitive accuracy. Extensive experiments show the superiority of our method. For example, the proposed PAN++ achieves an end-to-end text spotting F-measure of 64.9 at 29.2 FPS on the Total-Text dataset, which significantly outperforms the previous best method. Code will be available at: https://git.io/PAN.
Feature Decomposition and Reconstruction Learning for Effective Facial Expression Recognition
Apr 21, 2021
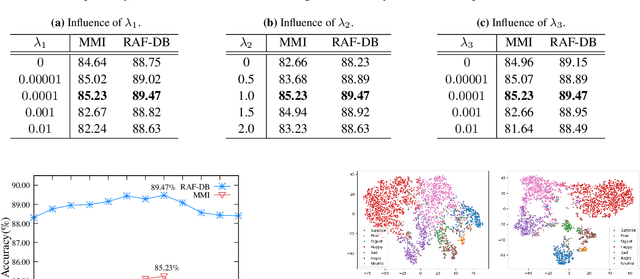
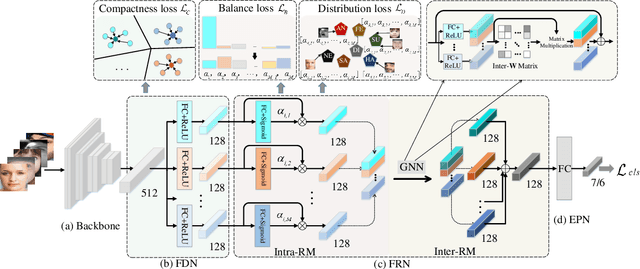
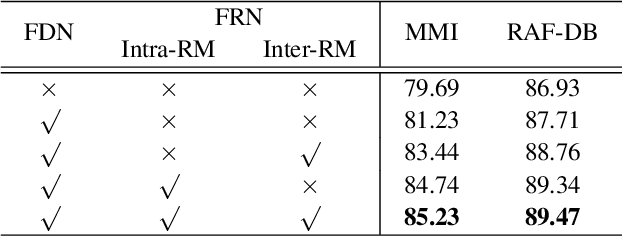
In this paper, we propose a novel Feature Decomposition and Reconstruction Learning (FDRL) method for effective facial expression recognition. We view the expression information as the combination of the shared information (expression similarities) across different expressions and the unique information (expression-specific variations) for each expression. More specifically, FDRL mainly consists of two crucial networks: a Feature Decomposition Network (FDN) and a Feature Reconstruction Network (FRN). In particular, FDN first decomposes the basic features extracted from a backbone network into a set of facial action-aware latent features to model expression similarities. Then, FRN captures the intra-feature and inter-feature relationships for latent features to characterize expression-specific variations, and reconstructs the expression feature. To this end, two modules including an intra-feature relation modeling module and an inter-feature relation modeling module are developed in FRN. Experimental results on both the in-the-lab databases (including CK+, MMI, and Oulu-CASIA) and the in-the-wild databases (including RAF-DB and SFEW) show that the proposed FDRL method consistently achieves higher recognition accuracy than several state-of-the-art methods. This clearly highlights the benefit of feature decomposition and reconstruction for classifying expressions.