 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePredicting the Original Appearance of Damaged Historical Documents
Dec 16, 2024



Historical documents encompass a wealth of cultural treasures but suffer from severe damages including character missing, paper damage, and ink erosion over time. However, existing document processing methods primarily focus on binarization, enhancement, etc., neglecting the repair of these damages. To this end, we present a new task, termed Historical Document Repair (HDR), which aims to predict the original appearance of damaged historical documents. To fill the gap in this field, we propose a large-scale dataset HDR28K and a diffusion-based network DiffHDR for historical document repair. Specifically, HDR28K contains 28,552 damaged-repaired image pairs with character-level annotations and multi-style degradations. Moreover, DiffHDR augments the vanilla diffusion framework with semantic and spatial information and a meticulously designed character perceptual loss for contextual and visual coherence. Experimental results demonstrate that the proposed DiffHDR trained using HDR28K significantly surpasses existing approaches and exhibits remarkable performance in handling real damaged documents. Notably, DiffHDR can also be extended to document editing and text block generation, showcasing its high flexibility and generalization capacity. We believe this study could pioneer a new direction of document processing and contribute to the inheritance of invaluable cultures and civilizations. The dataset and code is available at https://github.com/yeungchenwa/HDR.
* Accepted to AAAI 2025; Github Page: https://github.com/yeungchenwa/HDR
DocRes: A Generalist Model Toward Unifying Document Image Restoration Tasks
May 07, 2024



Document image restoration is a crucial aspect of Document AI systems, as the quality of document images significantly influences the overall performance. Prevailing methods address distinct restoration tasks independently, leading to intricate systems and the incapability to harness the potential synergies of multi-task learning. To overcome this challenge, we propose DocRes, a generalist model that unifies five document image restoration tasks including dewarping, deshadowing, appearance enhancement, deblurring, and binarization. To instruct DocRes to perform various restoration tasks, we propose a novel visual prompt approach called Dynamic Task-Specific Prompt (DTSPrompt). The DTSPrompt for different tasks comprises distinct prior features, which are additional characteristics extracted from the input image. Beyond its role as a cue for task-specific execution, DTSPrompt can also serve as supplementary information to enhance the model's performance. Moreover, DTSPrompt is more flexible than prior visual prompt approaches as it can be seamlessly applied and adapted to inputs with high and variable resolutions. Experimental results demonstrate that DocRes achieves competitive or superior performance compared to existing state-of-the-art task-specific models. This underscores the potential of DocRes across a broader spectrum of document image restoration tasks. The source code is publicly available at https://github.com/ZZZHANG-jx/DocRes
Datasets for Large Language Models: A Comprehensive Survey
Feb 28, 2024



This paper embarks on an exploration into the Large Language Model (LLM) datasets, which play a crucial role in the remarkable advancements of LLMs. The datasets serve as the foundational infrastructure analogous to a root system that sustains and nurtures the development of LLMs. Consequently, examination of these datasets emerges as a critical topic in research. In order to address the current lack of a comprehensive overview and thorough analysis of LLM datasets, and to gain insights into their current status and future trends, this survey consolidates and categorizes the fundamental aspects of LLM datasets from five perspectives: (1) Pre-training Corpora; (2) Instruction Fine-tuning Datasets; (3) Preference Datasets; (4) Evaluation Datasets; (5) Traditional Natural Language Processing (NLP) Datasets. The survey sheds light on the prevailing challenges and points out potential avenues for future investigation. Additionally, a comprehensive review of the existing available dataset resources is also provided, including statistics from 444 datasets, covering 8 language categories and spanning 32 domains. Information from 20 dimensions is incorporated into the dataset statistics. The total data size surveyed surpasses 774.5 TB for pre-training corpora and 700M instances for other datasets. We aim to present the entire landscape of LLM text datasets, serving as a comprehensive reference for researchers in this field and contributing to future studies. Related resources are available at: https://github.com/lmmlzn/Awesome-LLMs-Datasets.
SwinTextSpotter v2: Towards Better Synergy for Scene Text Spotting
Jan 15, 2024End-to-end scene text spotting, which aims to read the text in natural images, has garnered significant attention in recent years. However, recent state-of-the-art methods usually incorporate detection and recognition simply by sharing the backbone, which does not directly take advantage of the feature interaction between the two tasks. In this paper, we propose a new end-to-end scene text spotting framework termed SwinTextSpotter v2, which seeks to find a better synergy between text detection and recognition. Specifically, we enhance the relationship between two tasks using novel Recognition Conversion and Recognition Alignment modules. Recognition Conversion explicitly guides text localization through recognition loss, while Recognition Alignment dynamically extracts text features for recognition through the detection predictions. This simple yet effective design results in a concise framework that requires neither an additional rectification module nor character-level annotations for the arbitrarily-shaped text. Furthermore, the parameters of the detector are greatly reduced without performance degradation by introducing a Box Selection Schedule. Qualitative and quantitative experiments demonstrate that SwinTextSpotter v2 achieved state-of-the-art performance on various multilingual (English, Chinese, and Vietnamese) benchmarks. The code will be available at \href{https://github.com/mxin262/SwinTextSpotterv2}{SwinTextSpotter v2}.
UPOCR: Towards Unified Pixel-Level OCR Interface
Dec 05, 2023In recent years, the optical character recognition (OCR) field has been proliferating with plentiful cutting-edge approaches for a wide spectrum of tasks. However, these approaches are task-specifically designed with divergent paradigms, architectures, and training strategies, which significantly increases the complexity of research and maintenance and hinders the fast deployment in applications. To this end, we propose UPOCR, a simple-yet-effective generalist model for Unified Pixel-level OCR interface. Specifically, the UPOCR unifies the paradigm of diverse OCR tasks as image-to-image transformation and the architecture as a vision Transformer (ViT)-based encoder-decoder. Learnable task prompts are introduced to push the general feature representations extracted by the encoder toward task-specific spaces, endowing the decoder with task awareness. Moreover, the model training is uniformly aimed at minimizing the discrepancy between the generated and ground-truth images regardless of the inhomogeneity among tasks. Experiments are conducted on three pixel-level OCR tasks including text removal, text segmentation, and tampered text detection. Without bells and whistles, the experimental results showcase that the proposed method can simultaneously achieve state-of-the-art performance on three tasks with a unified single model, which provides valuable strategies and insights for future research on generalist OCR models. Code will be publicly available.
Exploring OCR Capabilities of GPT-4V : A Quantitative and In-depth Evaluation
Oct 29, 2023



This paper presents a comprehensive evaluation of the Optical Character Recognition (OCR) capabilities of the recently released GPT-4V(ision), a Large Multimodal Model (LMM). We assess the model's performance across a range of OCR tasks, including scene text recognition, handwritten text recognition, handwritten mathematical expression recognition, table structure recognition, and information extraction from visually-rich document. The evaluation reveals that GPT-4V performs well in recognizing and understanding Latin contents, but struggles with multilingual scenarios and complex tasks. Specifically, it showed limitations when dealing with non-Latin languages and complex tasks such as handwriting mathematical expression recognition, table structure recognition, and end-to-end semantic entity recognition and pair extraction from document image. Based on these observations, we affirm the necessity and continued research value of specialized OCR models. In general, despite its versatility in handling diverse OCR tasks, GPT-4V does not outperform existing state-of-the-art OCR models. How to fully utilize pre-trained general-purpose LMMs such as GPT-4V for OCR downstream tasks remains an open problem. The study offers a critical reference for future research in OCR with LMMs. Evaluation pipeline and results are available at https://github.com/SCUT-DLVCLab/GPT-4V_OCR.
Revisiting Scene Text Recognition: A Data Perspective
Jul 19, 2023



This paper aims to re-assess scene text recognition (STR) from a data-oriented perspective. We begin by revisiting the six commonly used benchmarks in STR and observe a trend of performance saturation, whereby only 2.91% of the benchmark images cannot be accurately recognized by an ensemble of 13 representative models. While these results are impressive and suggest that STR could be considered solved, however, we argue that this is primarily due to the less challenging nature of the common benchmarks, thus concealing the underlying issues that STR faces. To this end, we consolidate a large-scale real STR dataset, namely Union14M, which comprises 4 million labeled images and 10 million unlabeled images, to assess the performance of STR models in more complex real-world scenarios. Our experiments demonstrate that the 13 models can only achieve an average accuracy of 66.53% on the 4 million labeled images, indicating that STR still faces numerous challenges in the real world. By analyzing the error patterns of the 13 models, we identify seven open challenges in STR and develop a challenge-driven benchmark consisting of eight distinct subsets to facilitate further progress in the field. Our exploration demonstrates that STR is far from being solved and leveraging data may be a promising solution. In this regard, we find that utilizing the 10 million unlabeled images through self-supervised pre-training can significantly improve the robustness of STR model in real-world scenarios and leads to state-of-the-art performance.
ViTEraser: Harnessing the Power of Vision Transformers for Scene Text Removal with SegMIM Pretraining
Jun 21, 2023Scene text removal (STR) aims at replacing text strokes in natural scenes with visually coherent backgrounds. Recent STR approaches rely on iterative refinements or explicit text masks, resulting in higher complexity and sensitivity to the accuracy of text localization. Moreover, most existing STR methods utilize convolutional neural networks (CNNs) for feature representation while the potential of vision Transformers (ViTs) remains largely unexplored. In this paper, we propose a simple-yet-effective ViT-based text eraser, dubbed ViTEraser. Following a concise encoder-decoder framework, different types of ViTs can be easily integrated into ViTEraser to enhance the long-range dependencies and global reasoning. Specifically, the encoder hierarchically maps the input image into the hidden space through ViT blocks and patch embedding layers, while the decoder gradually upsamples the hidden features to the text-erased image with ViT blocks and patch splitting layers. As ViTEraser implicitly integrates text localization and inpainting, we propose a novel end-to-end pretraining method, termed SegMIM, which focuses the encoder and decoder on the text box segmentation and masked image modeling tasks, respectively. To verify the effectiveness of the proposed methods, we comprehensively explore the architecture, pretraining, and scalability of the ViT-based encoder-decoder for STR, which provides deep insights into the application of ViT to STR. Experimental results demonstrate that ViTEraser with SegMIM achieves state-of-the-art performance on STR by a substantial margin. Furthermore, the extended experiment on tampered scene text detection demonstrates the generality of ViTEraser to other tasks. We believe this paper can inspire more research on ViT-based STR approaches. Code will be available at https://github.com/shannanyinxiang/ViTEraser.
Don't Forget Me: Accurate Background Recovery for Text Removal via Modeling Local-Global Context
Jul 21, 2022
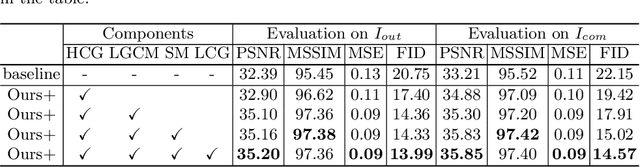
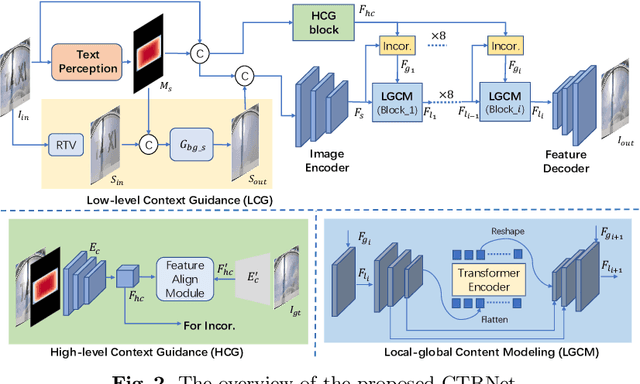
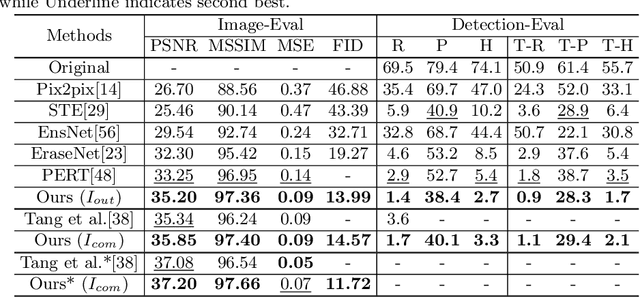
Text removal has attracted increasingly attention due to its various applications on privacy protection, document restoration, and text editing. It has shown significant progress with deep neural network. However, most of the existing methods often generate inconsistent results for complex background. To address this issue, we propose a Contextual-guided Text Removal Network, termed as CTRNet. CTRNet explores both low-level structure and high-level discriminative context feature as prior knowledge to guide the process of background restoration. We further propose a Local-global Content Modeling (LGCM) block with CNNs and Transformer-Encoder to capture local features and establish the long-term relationship among pixels globally. Finally, we incorporate LGCM with context guidance for feature modeling and decoding. Experiments on benchmark datasets, SCUT-EnsText and SCUT-Syn show that CTRNet significantly outperforms the existing state-of-the-art methods. Furthermore, a qualitative experiment on examination papers also demonstrates the generalization ability of our method. The codes and supplement materials are available at https://github.com/lcy0604/CTRNet.
SwinTextSpotter: Scene Text Spotting via Better Synergy between Text Detection and Text Recognition
Mar 19, 2022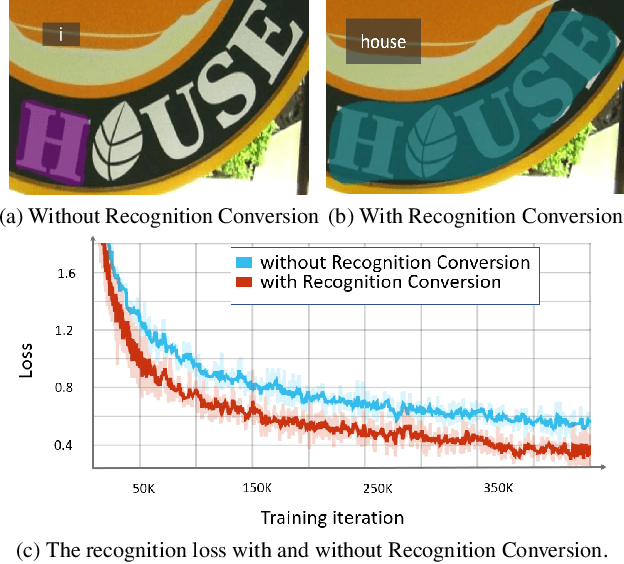
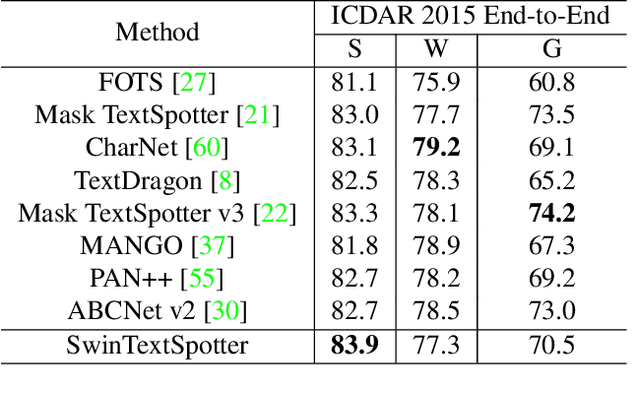
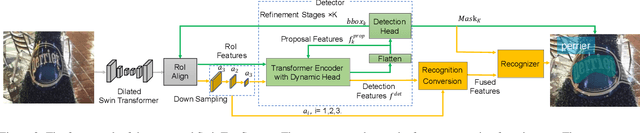
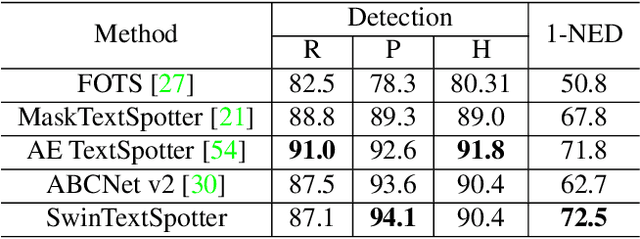
End-to-end scene text spotting has attracted great attention in recent years due to the success of excavating the intrinsic synergy of the scene text detection and recognition. However, recent state-of-the-art methods usually incorporate detection and recognition simply by sharing the backbone, which does not directly take advantage of the feature interaction between the two tasks. In this paper, we propose a new end-to-end scene text spotting framework termed SwinTextSpotter. Using a transformer encoder with dynamic head as the detector, we unify the two tasks with a novel Recognition Conversion mechanism to explicitly guide text localization through recognition loss. The straightforward design results in a concise framework that requires neither additional rectification module nor character-level annotation for the arbitrarily-shaped text. Qualitative and quantitative experiments on multi-oriented datasets RoIC13 and ICDAR 2015, arbitrarily-shaped datasets Total-Text and CTW1500, and multi-lingual datasets ReCTS (Chinese) and VinText (Vietnamese) demonstrate SwinTextSpotter significantly outperforms existing methods. Code is available at https://github.com/mxin262/SwinTextSpotter.