 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOpen-Loop Planning, Closed-Loop Verification: Speculative Verification for VLA
Apr 03, 2026Vision-Language-Action (VLA) models, as large foundation models for embodied control, have shown strong performance in manipulation tasks. However, their performance comes at high inference cost. To improve efficiency, recent methods adopt action chunking, which predicts a sequence of future actions for open-loop execution. Although effective for reducing computation, open-loop execution is sensitive to environmental changes and prone to error accumulation due to the lack of close-loop feedback. To address this limitation, we propose Speculative Verification for VLA Control (SV-VLA), a framework that combines efficient open-loop long-horizon planning with lightweight closed-loop online verification. Specifically, SV-VLA uses a heavy VLA as a low-frequency macro-planner to generate an action chunk together with a planning context, while a lightweight verifier continuously monitors execution based on the latest observations. Conditioned on both the current observation and the planning context, the verifier compares the planned action against a closed-loop reference action and triggers replanning only when necessary. Experiments demonstrate that SV-VLA combines the efficiency of chunked prediction with the robustness of closed-loop control, enabling efficient and reliable VLA-based control in dynamic environments. Code is available: https://github.com/edsad122/SV-VLA.
WorldForge: Unlocking Emergent 3D/4D Generation in Video Diffusion Model via Training-Free Guidance
Sep 18, 2025



Recent video diffusion models demonstrate strong potential in spatial intelligence tasks due to their rich latent world priors. However, this potential is hindered by their limited controllability and geometric inconsistency, creating a gap between their strong priors and their practical use in 3D/4D tasks. As a result, current approaches often rely on retraining or fine-tuning, which risks degrading pretrained knowledge and incurs high computational costs. To address this, we propose WorldForge, a training-free, inference-time framework composed of three tightly coupled modules. Intra-Step Recursive Refinement introduces a recursive refinement mechanism during inference, which repeatedly optimizes network predictions within each denoising step to enable precise trajectory injection. Flow-Gated Latent Fusion leverages optical flow similarity to decouple motion from appearance in the latent space and selectively inject trajectory guidance into motion-related channels. Dual-Path Self-Corrective Guidance compares guided and unguided denoising paths to adaptively correct trajectory drift caused by noisy or misaligned structural signals. Together, these components inject fine-grained, trajectory-aligned guidance without training, achieving both accurate motion control and photorealistic content generation. Extensive experiments across diverse benchmarks validate our method's superiority in realism, trajectory consistency, and visual fidelity. This work introduces a novel plug-and-play paradigm for controllable video synthesis, offering a new perspective on leveraging generative priors for spatial intelligence.
Weakly and Self-Supervised Class-Agnostic Motion Prediction for Autonomous Driving
Sep 16, 2025Understanding motion in dynamic environments is critical for autonomous driving, thereby motivating research on class-agnostic motion prediction. In this work, we investigate weakly and self-supervised class-agnostic motion prediction from LiDAR point clouds. Outdoor scenes typically consist of mobile foregrounds and static backgrounds, allowing motion understanding to be associated with scene parsing. Based on this observation, we propose a novel weakly supervised paradigm that replaces motion annotations with fully or partially annotated (1%, 0.1%) foreground/background masks for supervision. To this end, we develop a weakly supervised approach utilizing foreground/background cues to guide the self-supervised learning of motion prediction models. Since foreground motion generally occurs in non-ground regions, non-ground/ground masks can serve as an alternative to foreground/background masks, further reducing annotation effort. Leveraging non-ground/ground cues, we propose two additional approaches: a weakly supervised method requiring fewer (0.01%) foreground/background annotations, and a self-supervised method without annotations. Furthermore, we design a Robust Consistency-aware Chamfer Distance loss that incorporates multi-frame information and robust penalty functions to suppress outliers in self-supervised learning. Experiments show that our weakly and self-supervised models outperform existing self-supervised counterparts, and our weakly supervised models even rival some supervised ones. This demonstrates that our approaches effectively balance annotation effort and performance.
DSOcc: Leveraging Depth Awareness and Semantic Aid to Boost Camera-Based 3D Semantic Occupancy Prediction
May 27, 2025Camera-based 3D semantic occupancy prediction offers an efficient and cost-effective solution for perceiving surrounding scenes in autonomous driving. However, existing works rely on explicit occupancy state inference, leading to numerous incorrect feature assignments, and insufficient samples restrict the learning of occupancy class inference. To address these challenges, we propose leveraging Depth awareness and Semantic aid to boost camera-based 3D semantic Occupancy prediction (DSOcc). We jointly perform occupancy state and occupancy class inference, where soft occupancy confidence is calculated through non-learning method and multiplied with image features to make the voxel representation aware of depth, enabling adaptive implicit occupancy state inference. Rather than focusing on improving feature learning, we directly utilize well-trained image semantic segmentation and fuse multiple frames with their occupancy probabilities to aid occupancy class inference, thereby enhancing robustness. Experimental results demonstrate that DSOcc achieves state-of-the-art performance on the SemanticKITTI dataset among camera-based methods.
FLASH: Latent-Aware Semi-Autoregressive Speculative Decoding for Multimodal Tasks
May 19, 2025Large language and multimodal models (LLMs and LMMs) exhibit strong inference capabilities but are often limited by slow decoding speeds. This challenge is especially acute in LMMs, where visual inputs typically comprise more tokens with lower information density than text -- an issue exacerbated by recent trends toward finer-grained visual tokenizations to boost performance. Speculative decoding has been effective in accelerating LLM inference by using a smaller draft model to generate candidate tokens, which are then selectively verified by the target model, improving speed without sacrificing output quality. While this strategy has been extended to LMMs, existing methods largely overlook the unique properties of visual inputs and depend solely on text-based draft models. In this work, we propose \textbf{FLASH} (Fast Latent-Aware Semi-Autoregressive Heuristics), a speculative decoding framework designed specifically for LMMs, which leverages two key properties of multimodal data to design the draft model. First, to address redundancy in visual tokens, we propose a lightweight latent-aware token compression mechanism. Second, recognizing that visual objects often co-occur within a scene, we employ a semi-autoregressive decoding strategy to generate multiple tokens per forward pass. These innovations accelerate draft decoding while maintaining high acceptance rates, resulting in faster overall inference. Experiments show that FLASH significantly outperforms prior speculative decoding approaches in both unimodal and multimodal settings, achieving up to \textbf{2.68$\times$} speed-up on video captioning and \textbf{2.55$\times$} on visual instruction tuning tasks compared to the original LMM.
TacoDepth: Towards Efficient Radar-Camera Depth Estimation with One-stage Fusion
Apr 16, 2025



Radar-Camera depth estimation aims to predict dense and accurate metric depth by fusing input images and Radar data. Model efficiency is crucial for this task in pursuit of real-time processing on autonomous vehicles and robotic platforms. However, due to the sparsity of Radar returns, the prevailing methods adopt multi-stage frameworks with intermediate quasi-dense depth, which are time-consuming and not robust. To address these challenges, we propose TacoDepth, an efficient and accurate Radar-Camera depth estimation model with one-stage fusion. Specifically, the graph-based Radar structure extractor and the pyramid-based Radar fusion module are designed to capture and integrate the graph structures of Radar point clouds, delivering superior model efficiency and robustness without relying on the intermediate depth results. Moreover, TacoDepth can be flexible for different inference modes, providing a better balance of speed and accuracy. Extensive experiments are conducted to demonstrate the efficacy of our method. Compared with the previous state-of-the-art approach, TacoDepth improves depth accuracy and processing speed by 12.8% and 91.8%. Our work provides a new perspective on efficient Radar-Camera depth estimation.
Distill Any Depth: Distillation Creates a Stronger Monocular Depth Estimator
Feb 26, 2025Monocular depth estimation (MDE) aims to predict scene depth from a single RGB image and plays a crucial role in 3D scene understanding. Recent advances in zero-shot MDE leverage normalized depth representations and distillation-based learning to improve generalization across diverse scenes. However, current depth normalization methods for distillation, relying on global normalization, can amplify noisy pseudo-labels, reducing distillation effectiveness. In this paper, we systematically analyze the impact of different depth normalization strategies on pseudo-label distillation. Based on our findings, we propose Cross-Context Distillation, which integrates global and local depth cues to enhance pseudo-label quality. Additionally, we introduce a multi-teacher distillation framework that leverages complementary strengths of different depth estimation models, leading to more robust and accurate depth predictions. Extensive experiments on benchmark datasets demonstrate that our approach significantly outperforms state-of-the-art methods, both quantitatively and qualitatively.
Self-Supervised 3D Scene Flow Estimation and Motion Prediction using Local Rigidity Prior
Oct 17, 2023



In this article, we investigate self-supervised 3D scene flow estimation and class-agnostic motion prediction on point clouds. A realistic scene can be well modeled as a collection of rigidly moving parts, therefore its scene flow can be represented as a combination of the rigid motion of these individual parts. Building upon this observation, we propose to generate pseudo scene flow labels for self-supervised learning through piecewise rigid motion estimation, in which the source point cloud is decomposed into local regions and each region is treated as rigid. By rigidly aligning each region with its potential counterpart in the target point cloud, we obtain a region-specific rigid transformation to generate its pseudo flow labels. To mitigate the impact of potential outliers on label generation, when solving the rigid registration for each region, we alternately perform three steps: establishing point correspondences, measuring the confidence for the correspondences, and updating the rigid transformation based on the correspondences and their confidence. As a result, confident correspondences will dominate label generation and a validity mask will be derived for the generated pseudo labels. By using the pseudo labels together with their validity mask for supervision, models can be trained in a self-supervised manner. Extensive experiments on FlyingThings3D and KITTI datasets demonstrate that our method achieves new state-of-the-art performance in self-supervised scene flow learning, without any ground truth scene flow for supervision, even performing better than some supervised counterparts. Additionally, our method is further extended to class-agnostic motion prediction and significantly outperforms previous state-of-the-art self-supervised methods on nuScenes dataset.
Unsupervised 3D Pose Transfer with Cross Consistency and Dual Reconstruction
Nov 18, 2022



The goal of 3D pose transfer is to transfer the pose from the source mesh to the target mesh while preserving the identity information (e.g., face, body shape) of the target mesh. Deep learning-based methods improved the efficiency and performance of 3D pose transfer. However, most of them are trained under the supervision of the ground truth, whose availability is limited in real-world scenarios. In this work, we present X-DualNet, a simple yet effective approach that enables unsupervised 3D pose transfer. In X-DualNet, we introduce a generator $G$ which contains correspondence learning and pose transfer modules to achieve 3D pose transfer. We learn the shape correspondence by solving an optimal transport problem without any key point annotations and generate high-quality meshes with our elastic instance normalization (ElaIN) in the pose transfer module. With $G$ as the basic component, we propose a cross consistency learning scheme and a dual reconstruction objective to learn the pose transfer without supervision. Besides that, we also adopt an as-rigid-as-possible deformer in the training process to fine-tune the body shape of the generated results. Extensive experiments on human and animal data demonstrate that our framework can successfully achieve comparable performance as the state-of-the-art supervised approaches.
RWSeg: Cross-graph Competing Random Walks for Weakly Supervised 3D Instance Segmentation
Aug 11, 2022

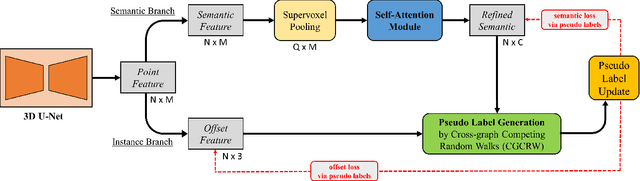

Instance segmentation on 3D point clouds has been attracting increasing attention due to its wide applications, especially in scene understanding areas. However, most existing methods require training data to be fully annotated. Manually preparing ground-truth labels at point-level is very cumbersome and labor-intensive. To address this issue, we propose a novel weakly supervised method RWSeg that only requires labeling one object with one point. With these sparse weak labels, we introduce a unified framework with two branches to propagate semantic and instance information respectively to unknown regions, using self-attention and random walk. Furthermore, we propose a Cross-graph Competing Random Walks (CGCRW) algorithm which encourages competition among different instance graphs to resolve ambiguities in closely placed objects and improve the performance on instance assignment. RWSeg can generate qualitative instance-level pseudo labels. Experimental results on ScanNet-v2 and S3DIS datasets show that our approach achieves comparable performance with fully-supervised methods and outperforms previous weakly-supervised methods by large margins. This is the first work that bridges the gap between weak and full supervision in the area.