 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePyramidCLIP: Hierarchical Feature Alignment for Vision-language Model Pretraining
Apr 29, 2022
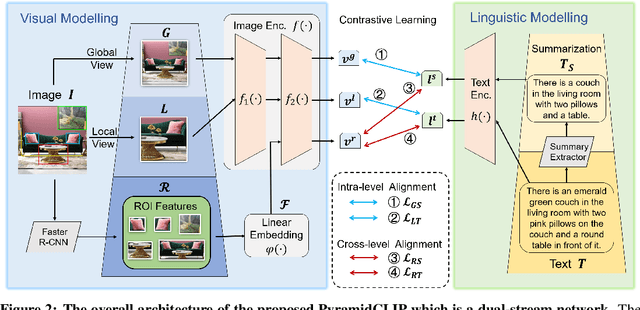
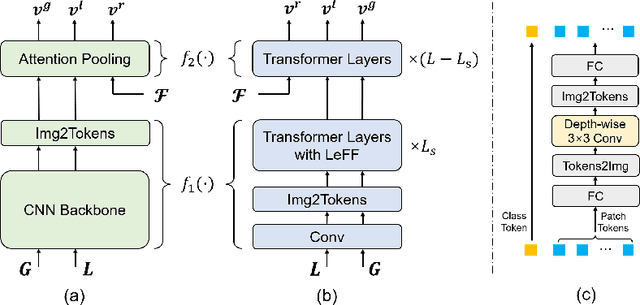
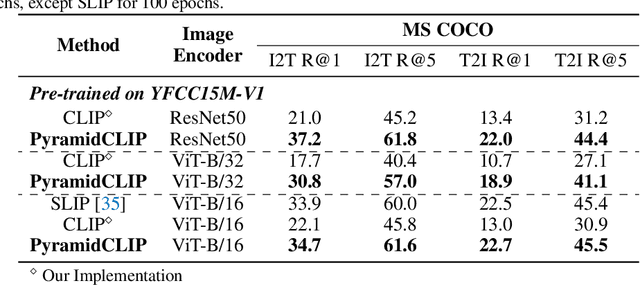
Large-scale vision-language pre-training has achieved promising results on downstream tasks. Existing methods highly rely on the assumption that the image-text pairs crawled from the Internet are in perfect one-to-one correspondence. However, in real scenarios, this assumption can be difficult to hold: the text description, obtained by crawling the affiliated metadata of the image, often suffer from semantic mismatch and mutual compatibility. To address these issues, here we introduce PyramidCLIP, which constructs an input pyramid with different semantic levels, and aligns visual elements and linguistic elements in the form of hierarchy via intra-level semantics alignment and cross-level relation alignment. Furthermore, we adjust the objective function by softening the loss of negative samples (unpaired samples) so as to weaken the strict constraint during the pre-training stage, thus mitigating the risk of the model being over-confident. Experiments on three downstream tasks, including zero-shot image classification, zero-shot image-text retrieval and image object detection, verify the effectiveness of the proposed PyramidCLIP. In particular, with the same amount of pre-training data of 15 millions image-text pairs, PyramidCLIP exceeds CLIP by 19.2%/18.5%/19.6% respectively, with the image encoder being ResNet-50/ViT-B32/ViT-B16 on ImageNet zero-shot classification top-1 accuracy. When scaling to larger datasets, the results of PyramidCLIP only trained for 8 epochs using 128M image-text pairs are very close to that of CLIP trained for 32 epochs using 400M training data.
PointInst3D: Segmenting 3D Instances by Points
Apr 25, 2022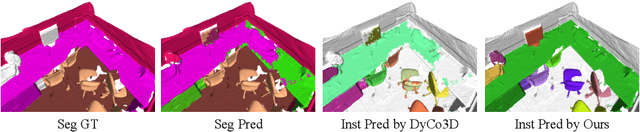

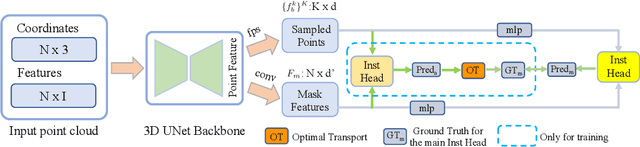
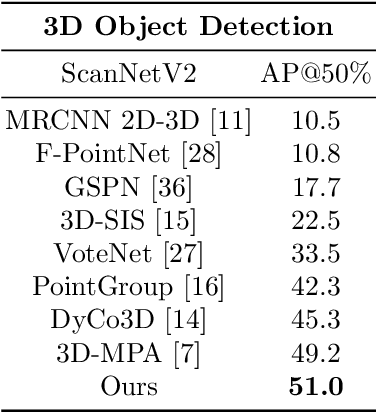
The current state-of-the-art methods in 3D instance segmentation typically involve a clustering step, despite the tendency towards heuristics, greedy algorithms, and a lack of robustness to the changes in data statistics. In contrast, we propose a fully-convolutional 3D point cloud instance segmentation method that works in a per-point prediction fashion. In doing so it avoids the challenges that clustering-based methods face: introducing dependencies among different tasks of the model. We find the key to its success is assigning a suitable target to each sampled point. Instead of the commonly used static or distance-based assignment strategies, we propose to use an Optimal Transport approach to optimally assign target masks to the sampled points according to the dynamic matching costs. Our approach achieves promising results on both ScanNet and S3DIS benchmarks. The proposed approach removes intertask dependencies and thus represents a simpler and more flexible 3D instance segmentation framework than other competing methods, while achieving improved segmentation accuracy.
TopFormer: Token Pyramid Transformer for Mobile Semantic Segmentation
Apr 12, 2022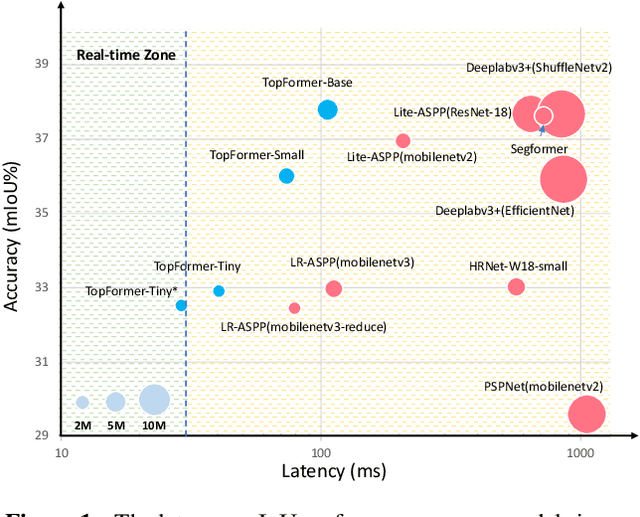
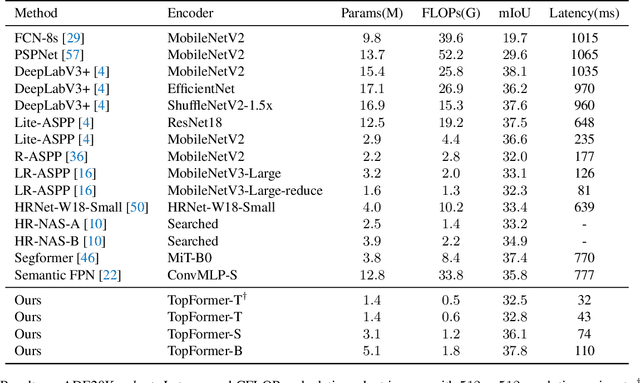
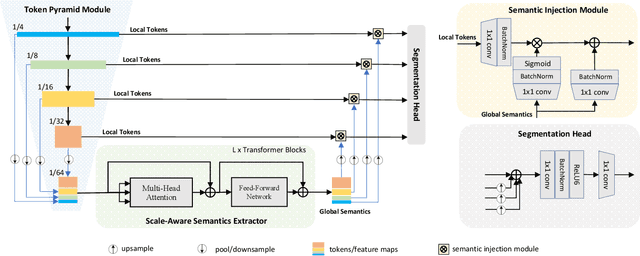
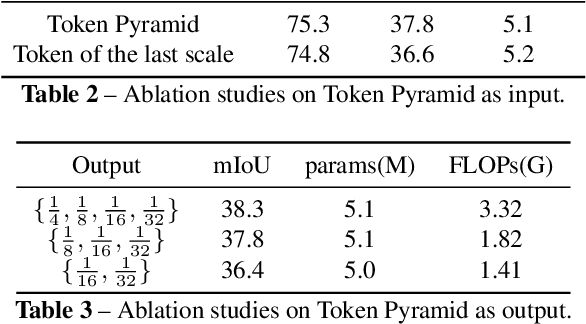
Although vision transformers (ViTs) have achieved great success in computer vision, the heavy computational cost hampers their applications to dense prediction tasks such as semantic segmentation on mobile devices. In this paper, we present a mobile-friendly architecture named \textbf{To}ken \textbf{P}yramid Vision Trans\textbf{former} (\textbf{TopFormer}). The proposed \textbf{TopFormer} takes Tokens from various scales as input to produce scale-aware semantic features, which are then injected into the corresponding tokens to augment the representation. Experimental results demonstrate that our method significantly outperforms CNN- and ViT-based networks across several semantic segmentation datasets and achieves a good trade-off between accuracy and latency. On the ADE20K dataset, TopFormer achieves 5\% higher accuracy in mIoU than MobileNetV3 with lower latency on an ARM-based mobile device. Furthermore, the tiny version of TopFormer achieves real-time inference on an ARM-based mobile device with competitive results. The code and models are available at: https://github.com/hustvl/TopFormer
Improving Monocular Visual Odometry Using Learned Depth
Apr 04, 2022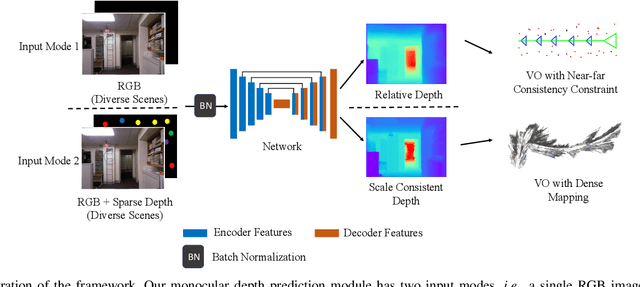
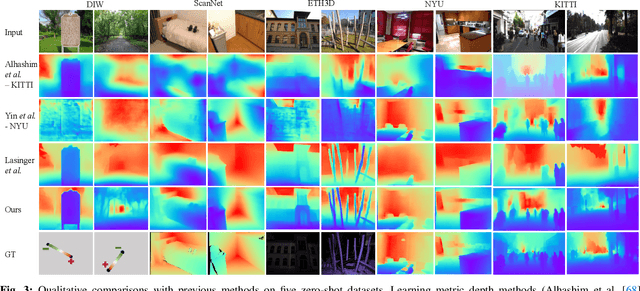
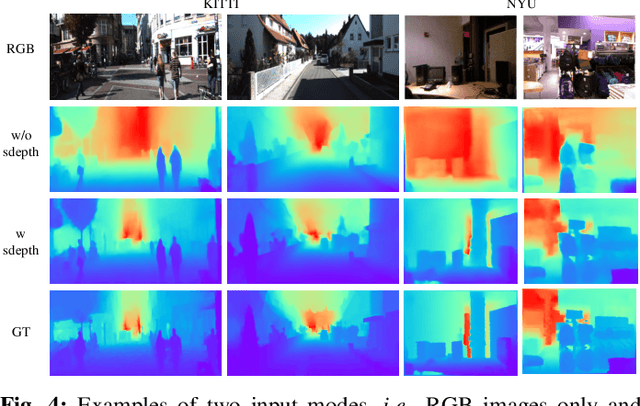
Monocular visual odometry (VO) is an important task in robotics and computer vision. Thus far, how to build accurate and robust monocular VO systems that can work well in diverse scenarios remains largely unsolved. In this paper, we propose a framework to exploit monocular depth estimation for improving VO. The core of our framework is a monocular depth estimation module with a strong generalization capability for diverse scenes. It consists of two separate working modes to assist the localization and mapping. With a single monocular image input, the depth estimation module predicts a relative depth to help the localization module on improving the accuracy. With a sparse depth map and an RGB image input, the depth estimation module can generate accurate scale-consistent depth for dense mapping. Compared with current learning-based VO methods, our method demonstrates a stronger generalization ability to diverse scenes. More significantly, our framework is able to boost the performances of existing geometry-based VO methods by a large margin.
Catching Both Gray and Black Swans: Open-set Supervised Anomaly Detection
Mar 28, 2022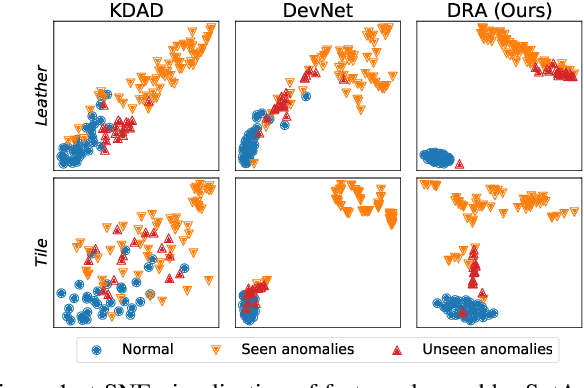
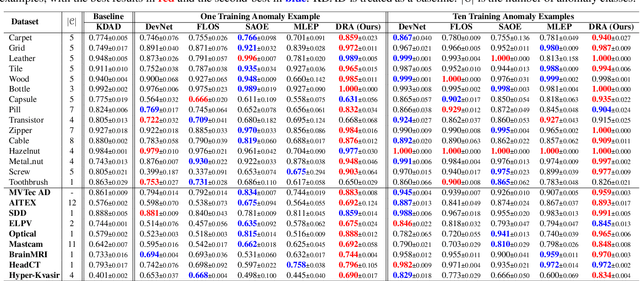
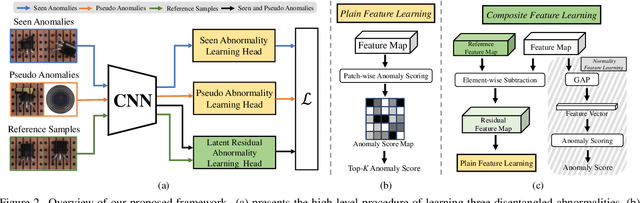
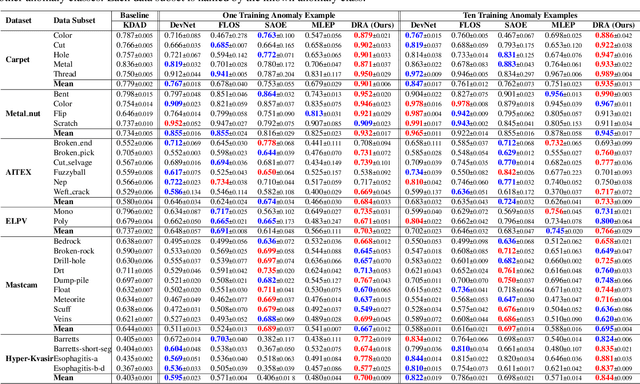
Despite most existing anomaly detection studies assume the availability of normal training samples only, a few labeled anomaly examples are often available in many real-world applications, such as defect samples identified during random quality inspection, lesion images confirmed by radiologists in daily medical screening, etc. These anomaly examples provide valuable knowledge about the application-specific abnormality, enabling significantly improved detection of similar anomalies in some recent models. However, those anomalies seen during training often do not illustrate every possible class of anomaly, rendering these models ineffective in generalizing to unseen anomaly classes. This paper tackles open-set supervised anomaly detection, in which we learn detection models using the anomaly examples with the objective to detect both seen anomalies (`gray swans') and unseen anomalies (`black swans'). We propose a novel approach that learns disentangled representations of abnormalities illustrated by seen anomalies, pseudo anomalies, and latent residual anomalies (i.e., samples that have unusual residuals compared to the normal data in a latent space), with the last two abnormalities designed to detect unseen anomalies. Extensive experiments on nine real-world anomaly detection datasets show superior performance of our model in detecting seen and unseen anomalies under diverse settings. Code and data are available at: https://github.com/choubo/DRA.
End-to-End Video Text Spotting with Transformer
Mar 20, 2022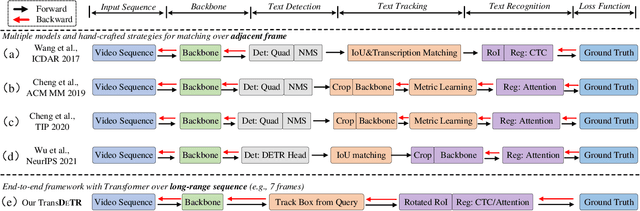
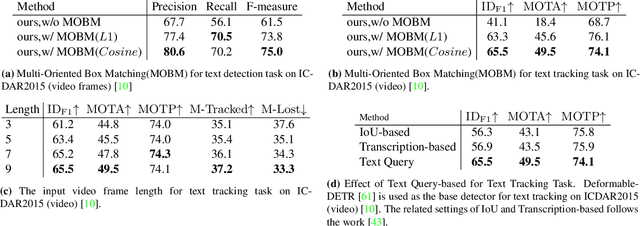
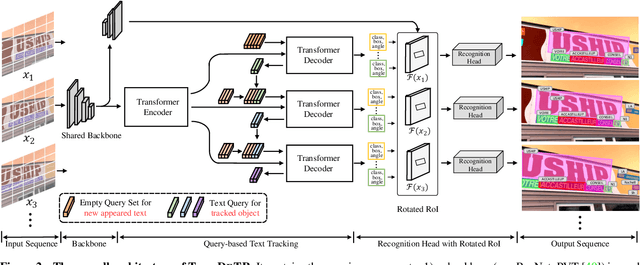
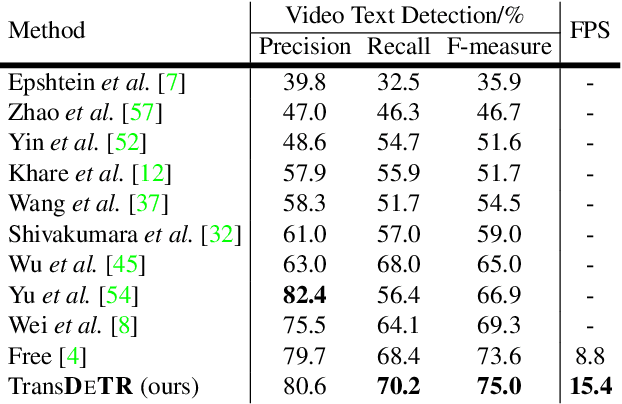
Recent video text spotting methods usually require the three-staged pipeline, i.e., detecting text in individual images, recognizing localized text, tracking text streams with post-processing to generate final results. These methods typically follow the tracking-by-match paradigm and develop sophisticated pipelines. In this paper, rooted in Transformer sequence modeling, we propose a simple, but effective end-to-end video text DEtection, Tracking, and Recognition framework (TransDETR). TransDETR mainly includes two advantages: 1) Different from the explicit match paradigm in the adjacent frame, TransDETR tracks and recognizes each text implicitly by the different query termed text query over long-range temporal sequence (more than 7 frames). 2) TransDETR is the first end-to-end trainable video text spotting framework, which simultaneously addresses the three sub-tasks (e.g., text detection, tracking, recognition). Extensive experiments in four video text datasets (i.e.,ICDAR2013 Video, ICDAR2015 Video, Minetto, and YouTube Video Text) are conducted to demonstrate that TransDETR achieves state-of-the-art performance with up to around 8.0% improvements on video text spotting tasks. The code of TransDETR can be found at https://github.com/weijiawu/TransDETR.
Training Protocol Matters: Towards Accurate Scene Text Recognition via Training Protocol Searching
Mar 17, 2022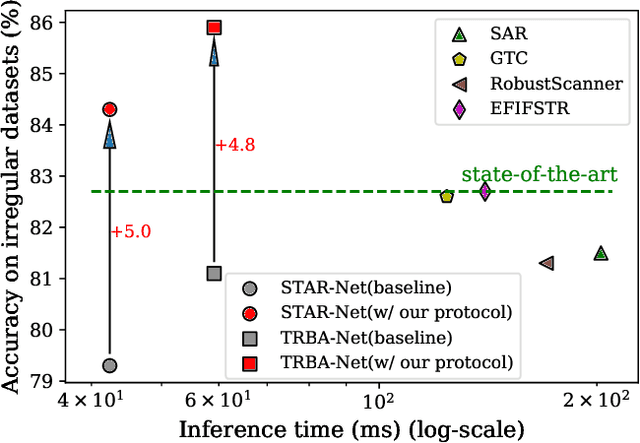
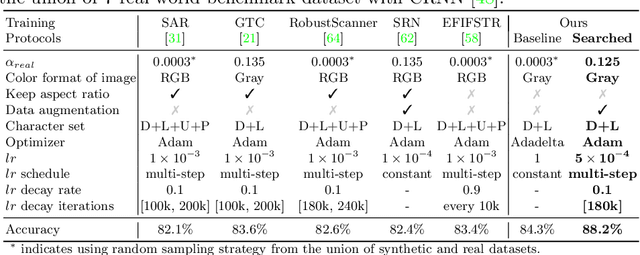

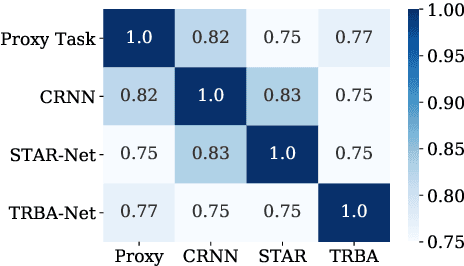
The development of scene text recognition (STR) in the era of deep learning has been mainly focused on novel architectures of STR models. However, training protocol (i.e., settings of the hyper-parameters involved in the training of STR models), which plays an equally important role in successfully training a good STR model, is under-explored for scene text recognition. In this work, we attempt to improve the accuracy of existing STR models by searching for optimal training protocol. Specifically, we develop a training protocol search algorithm, based on a newly designed search space and an efficient search algorithm using evolutionary optimization and proxy tasks. Experimental results show that our searched training protocol can improve the recognition accuracy of mainstream STR models by 2.7%~3.9%. In particular, with the searched training protocol, TRBA-Net achieves 2.1% higher accuracy than the state-of-the-art STR model (i.e., EFIFSTR), while the inference speed is 2.3x and 3.7x faster on CPU and GPU respectively. Extensive experiments are conducted to demonstrate the effectiveness of the proposed method and the generalization ability of the training protocol found by our search method. Code is available at https://github.com/VDIGPKU/STR_TPSearch.
PointAttN: You Only Need Attention for Point Cloud Completion
Mar 16, 2022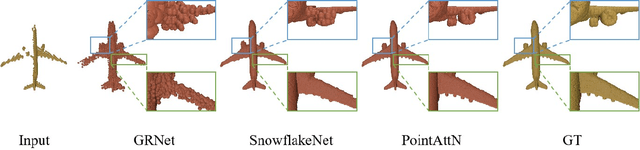
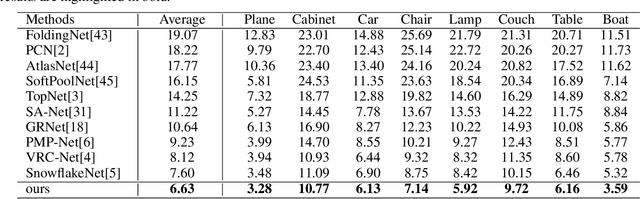
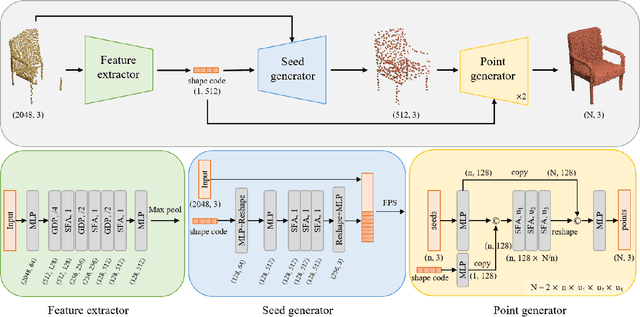
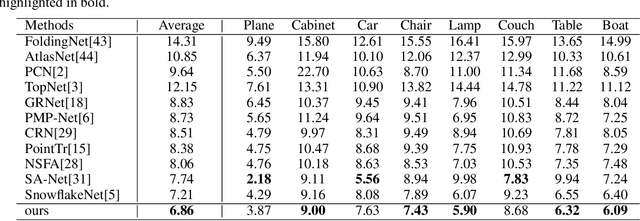
Point cloud completion referring to completing 3D shapes from partial 3D point clouds is a fundamental problem for 3D point cloud analysis tasks. Benefiting from the development of deep neural networks, researches on point cloud completion have made great progress in recent years. However, the explicit local region partition like kNNs involved in existing methods makes them sensitive to the density distribution of point clouds. Moreover, it serves limited receptive fields that prevent capturing features from long-range context information. To solve the problems, we leverage the cross-attention and self-attention mechanisms to design novel neural network for processing point cloud in a per-point manner to eliminate kNNs. Two essential blocks Geometric Details Perception (GDP) and Self-Feature Augment (SFA) are proposed to establish the short-range and long-range structural relationships directly among points in a simple yet effective way via attention mechanism. Then based on GDP and SFA, we construct a new framework with popular encoder-decoder architecture for point cloud completion. The proposed framework, namely PointAttN, is simple, neat and effective, which can precisely capture the structural information of 3D shapes and predict complete point clouds with highly detailed geometries. Experimental results demonstrate that our PointAttN outperforms state-of-the-art methods by a large margin on popular benchmarks like Completion3D and PCN. Code is available at: https://github.com/ohhhyeahhh/PointAttN
Efficient Video Segmentation Models with Per-frame Inference
Feb 24, 2022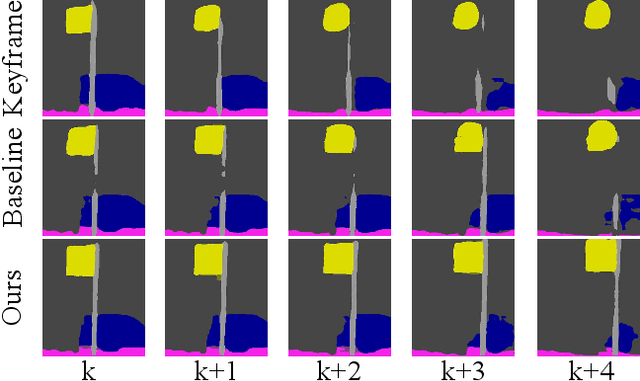
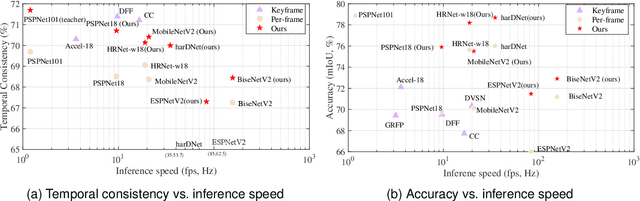
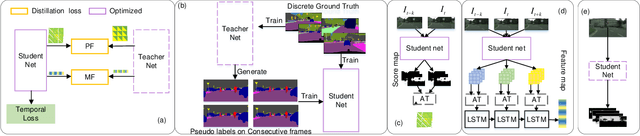
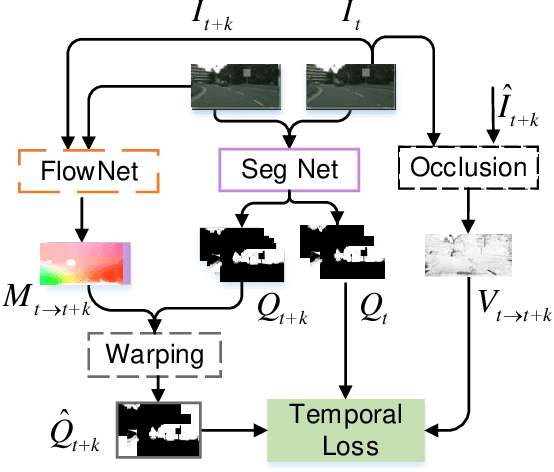
Most existing real-time deep models trained with each frame independently may produce inconsistent results across the temporal axis when tested on a video sequence. A few methods take the correlations in the video sequence into account,e.g., by propagating the results to the neighboring frames using optical flow or extracting frame representations using multi-frame information, which may lead to inaccurate results or unbalanced latency. In this work, we focus on improving the temporal consistency without introducing computation overhead in inference. To this end, we perform inference at each frame. Temporal consistency is achieved by learning from video frames with extra constraints during the training phase. introduced for inference. We propose several techniques to learn from the video sequence, including a temporal consistency loss and online/offline knowledge distillation methods. On the task of semantic video segmentation, weighing among accuracy, temporal smoothness, and efficiency, our proposed method outperforms keyframe-based methods and a few baseline methods that are trained with each frame independently, on datasets including Cityscapes, Camvid, and 300VW-Mask. We further apply our training method to video instance segmentation on YouTubeVISand develop an application of portrait matting in video sequences, by segmenting temporally consistent instance-level trimaps across frames. Experiments show superior qualitative and quantitative results. Code is available at: https://git.io/vidseg.
FreeSOLO: Learning to Segment Objects without Annotations
Feb 24, 2022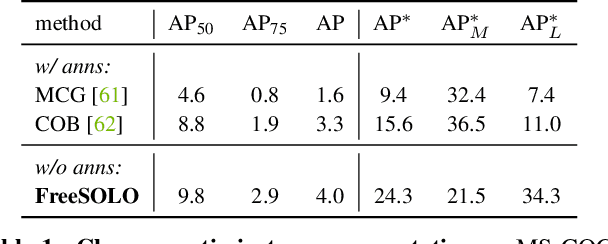

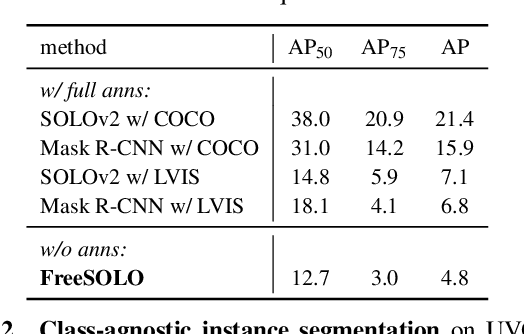
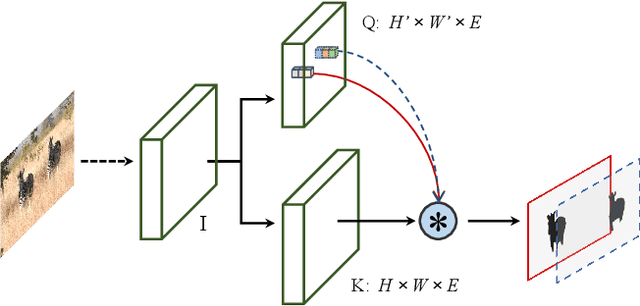
Instance segmentation is a fundamental vision task that aims to recognize and segment each object in an image. However, it requires costly annotations such as bounding boxes and segmentation masks for learning. In this work, we propose a fully unsupervised learning method that learns class-agnostic instance segmentation without any annotations. We present FreeSOLO, a self-supervised instance segmentation framework built on top of the simple instance segmentation method SOLO. Our method also presents a novel localization-aware pre-training framework, where objects can be discovered from complicated scenes in an unsupervised manner. FreeSOLO achieves 9.8% AP_{50} on the challenging COCO dataset, which even outperforms several segmentation proposal methods that use manual annotations. For the first time, we demonstrate unsupervised class-agnostic instance segmentation successfully. FreeSOLO's box localization significantly outperforms state-of-the-art unsupervised object detection/discovery methods, with about 100% relative improvements in COCO AP. FreeSOLO further demonstrates superiority as a strong pre-training method, outperforming state-of-the-art self-supervised pre-training methods by +9.8% AP when fine-tuning instance segmentation with only 5% COCO masks.