 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Attention Market: Interpreting Online Fair Re-ranking as Manifold Optimization under Walrasian Equilibrium
Apr 28, 2026Fair re-ranking aims to promote long-tail items and enhance diversity within groups in information retrieval. While previous research on online fairness-aware re-ranking has shown promising outcomes, our comprehensive evaluation of online fair re-ranking methods over 20 settings reveals significant performance disparities among existing methods. To uncover the root causes of these inconsistencies, we reformulate fair re-ranking within an attentional market framework governed by a Walrasian Equilibrium, where the fairness is treated as a taxation cost. This market-based formulation is then coupled with manifold optimization, demonstrating that seeking this equilibrium is equivalent to performing gradient descent on a specific ranking manifold constructed by the market. Different re-ranking settings induce distinct manifold geometries, and these intrinsic geometric differences dictate the gradient landscapes and optimization trajectories. We propose ManifoldRank, an efficient online fair re-ranking algorithm. ManifoldRank adjusts gradients to align with the ranking manifold, considering various contextual settings. On the supply side, it incorporates a gradient adjustment based on different fairness requirements, accounting for associated costs. On the demand side, it empirically predicts an additional gradient adjustment term derived from the ranking scores. By integrating these two gradient adjustments, ManifoldRank effectively balances fairness and accuracy. Experimental results across multiple datasets confirm ManifoldRank's effectiveness.
DyJR: Preserving Diversity in Reinforcement Learning with Verifiable Rewards via Dynamic Jensen-Shannon Replay
Mar 17, 2026While Reinforcement Learning (RL) enhances Large Language Model reasoning, on-policy algorithms like GRPO are sample-inefficient as they discard past rollouts. Existing experience replay methods address this by reusing accurate samples for direct policy updates, but this often incurs high computational costs and causes mode collapse via overfitting. We argue that historical data should prioritize sustaining diversity rather than simply reinforcing accuracy. To this end, we propose Dynamic Jensen-Shannon Replay (DyJR), a simple yet effective regularization framework using a dynamic reference distribution from recent trajectories. DyJR introduces two innovations: (1) A Time-Sensitive Dynamic Buffer that uses FIFO and adaptive sizing to retain only temporally proximal samples, synchronizing with model evolution; and (2) Jensen-Shannon Divergence Regularization, which replaces direct gradient updates with a distributional constraint to prevent diversity collapse. Experiments on mathematical reasoning and Text-to-SQL benchmarks demonstrate that DyJR significantly outperforms GRPO as well as baselines such as RLEP and Ex-GRPO, while maintaining training efficiency comparable to the original GRPO. Furthermore, from the perspective of Rank-$k$ token probability evolution, we show that DyJR enhances diversity and mitigates over-reliance on Rank-1 tokens, elucidating how specific sub-modules of DyJR influence the training dynamics.
CTkvr: KV Cache Retrieval for Long-Context LLMs via Centroid then Token Indexing
Dec 17, 2025Large language models (LLMs) are increasingly applied in long-context scenarios such as multi-turn conversations. However, long contexts pose significant challenges for inference efficiency, including high memory overhead from Key-Value (KV) cache and increased latency due to excessive memory accesses. Recent methods for dynamic KV selection struggle with trade-offs: block-level indexing degrades accuracy by retrieving irrelevant KV entries, while token-level indexing incurs high latency from inefficient retrieval mechanisms. In this paper, we propose CTKVR, a novel centroid-then-token KV retrieval scheme that addresses these limitations. CTKVR leverages a key observation: query vectors adjacent in position exhibit high similarity after Rotary Position Embedding (RoPE) and share most of their top-k KV cache entries. Based on this insight, CTKVR employs a two-stage retrieval strategy: lightweight centroids are precomputed during prefilling for centroid-grained indexing, followed by token-level refinement for precise KV retrieval. This approach balances retrieval efficiency and accuracy. To further enhance performance, we implement an optimized system for indexing construction and search using CPU-GPU co-execution. Experimentally, CTKVR achieves superior performance across multiple benchmarks with less than 1% accuracy degradation. Meanwhile, CTKVR delivers 3 times and 4 times throughput speedups on Llama-3-8B and Yi-9B at 96K context length across diverse GPU hardware.
The Choice of Divergence: A Neglected Key to Mitigating Diversity Collapse in Reinforcement Learning with Verifiable Reward
Sep 09, 2025



A central paradox in fine-tuning Large Language Models (LLMs) with Reinforcement Learning with Verifiable Reward (RLVR) is the frequent degradation of multi-attempt performance (Pass@k) despite improvements in single-attempt accuracy (Pass@1). This is often accompanied by catastrophic forgetting, where models lose previously acquired skills. While various methods have been proposed, the choice and function of the divergence term have been surprisingly unexamined as a proactive solution. We argue that standard RLVR objectives -- both those using the mode-seeking reverse KL-divergence and those forgoing a divergence term entirely -- lack a crucial mechanism for knowledge retention. The reverse-KL actively accelerates this decay by narrowing the policy, while its absence provides no safeguard against the model drifting from its diverse knowledge base. We propose a fundamental shift in perspective: using the divergence term itself as the solution. Our framework, Diversity-Preserving Hybrid RL (DPH-RL), leverages mass-covering f-divergences (like forward-KL and JS-divergence) to function as a rehearsal mechanism. By continuously referencing the initial policy, this approach forces the model to maintain broad solution coverage. Extensive experiments on math and SQL generation demonstrate that DPH-RL not only resolves the Pass@k degradation but improves both Pass@1 and Pass@k in- and out-of-domain. Additionally, DPH-RL is more training-efficient because it computes f-divergence using generator functions, requiring only sampling from the initial policy and no online reference model. Our work highlights a crucial, overlooked axis for improving RLVR, demonstrating that the proper selection of a divergence measure is a powerful tool for building more general and diverse reasoning models.
OleSpeech-IV: A Large-Scale Multispeaker and Multilingual Conversational Speech Dataset with Diverse Topics
Sep 04, 2025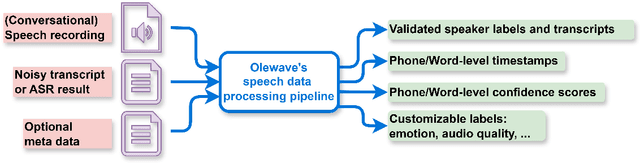
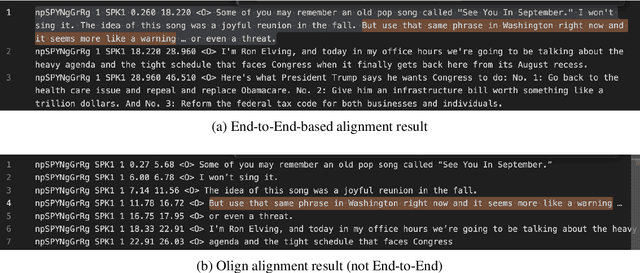
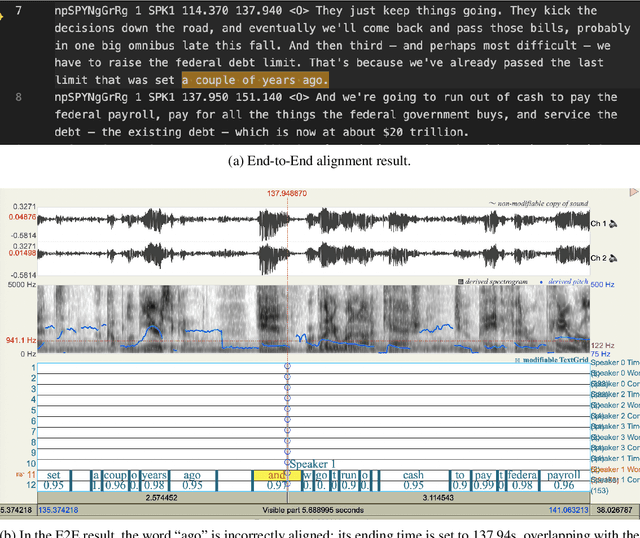
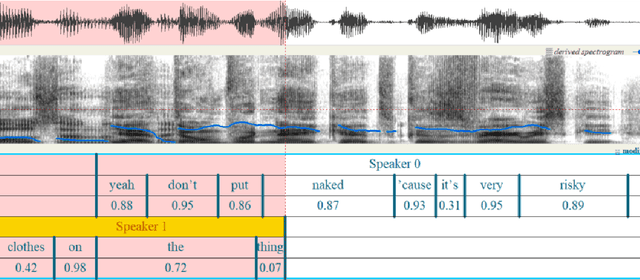
OleSpeech-IV dataset is a large-scale multispeaker and multilingual conversational speech dataset with diverse topics. The audio content comes from publicly-available English podcasts, talk shows, teleconferences, and other conversations. Speaker names, turns, and transcripts are human-sourced and refined by a proprietary pipeline, while additional information such as timestamps and confidence scores is derived from the pipeline. The IV denotes its position as Tier IV in the Olewave dataset series. In addition, we have open-sourced a subset, OleSpeech-IV-2025-EN-AR-100, for non-commercial research use.
Harnessing Negative Signals: Reinforcement Distillation from Teacher Data for LLM Reasoning
May 30, 2025Recent advances in model distillation demonstrate that data from advanced reasoning models (e.g., DeepSeek-R1, OpenAI's o1) can effectively transfer complex reasoning abilities to smaller, efficient student models. However, standard practices employ rejection sampling, discarding incorrect reasoning examples -- valuable, yet often underutilized data. This paper addresses the critical question: How can both positive and negative distilled reasoning traces be effectively leveraged to maximize LLM reasoning performance in an offline setting? To this end, We propose Reinforcement Distillation (REDI), a two-stage framework. Stage 1 learns from positive traces via Supervised Fine-Tuning (SFT). Stage 2 further refines the model using both positive and negative traces through our proposed REDI objective. This novel objective is a simple, reference-free loss function that outperforms established methods like DPO and SimPO in this distillation context. Our empirical evaluations demonstrate REDI's superiority over baseline Rejection Sampling SFT or SFT combined with DPO/SimPO on mathematical reasoning tasks. Notably, the Qwen-REDI-1.5B model, post-trained on just 131k positive and negative examples from the open Open-R1 dataset, achieves an 83.1% score on MATH-500 (pass@1). Its performance matches or surpasses that of DeepSeek-R1-Distill-Qwen-1.5B (a model post-trained on 800k proprietary data) across various mathematical reasoning benchmarks, establishing a new state-of-the-art for 1.5B models post-trained offline with openly available data.
VL-Rethinker: Incentivizing Self-Reflection of Vision-Language Models with Reinforcement Learning
Apr 10, 2025Recently, slow-thinking systems like GPT-o1 and DeepSeek-R1 have demonstrated great potential in solving challenging problems through explicit reflection. They significantly outperform the best fast-thinking models, such as GPT-4o, on various math and science benchmarks. However, their multimodal reasoning capabilities remain on par with fast-thinking models. For instance, GPT-o1's performance on benchmarks like MathVista, MathVerse, and MathVision is similar to fast-thinking models. In this paper, we aim to enhance the slow-thinking capabilities of vision-language models using reinforcement learning (without relying on distillation) to advance the state of the art. First, we adapt the GRPO algorithm with a novel technique called Selective Sample Replay (SSR) to address the vanishing advantages problem. While this approach yields strong performance, the resulting RL-trained models exhibit limited self-reflection or self-verification. To further encourage slow-thinking, we introduce Forced Rethinking, which appends a textual rethinking trigger to the end of initial rollouts in RL training, explicitly enforcing a self-reflection reasoning step. By combining these two techniques, our model, VL-Rethinker, advances state-of-the-art scores on MathVista, MathVerse, and MathVision to achieve 80.3%, 61.8%, and 43.9% respectively. VL-Rethinker also achieves open-source SoTA on multi-disciplinary benchmarks such as MMMU-Pro, EMMA, and MEGA-Bench, narrowing the gap with GPT-o1.
Guess What I am Thinking: A Benchmark for Inner Thought Reasoning of Role-Playing Language Agents
Mar 11, 2025



Recent advances in LLM-based role-playing language agents (RPLAs) have attracted broad attention in various applications. While chain-of-thought reasoning has shown importance in many tasks for LLMs, the internal thinking processes of RPLAs remain unexplored. Understanding characters' inner thoughts is crucial for developing advanced RPLAs. In this paper, we introduce ROLETHINK, a novel benchmark constructed from literature for evaluating character thought generation. We propose the task of inner thought reasoning, which includes two sets: the gold set that compares generated thoughts with original character monologues, and the silver set that uses expert synthesized character analyses as references. To address this challenge, we propose MIRROR, a chain-of-thought approach that generates character thoughts by retrieving memories, predicting character reactions, and synthesizing motivations. Through extensive experiments, we demonstrate the importance of inner thought reasoning for RPLAs, and MIRROR consistently outperforms existing methods. Resources are available at https://github.com/airaer1998/RPA_Thought.
AURORA:Automated Training Framework of Universal Process Reward Models via Ensemble Prompting and Reverse Verification
Feb 17, 2025



The reasoning capabilities of advanced large language models (LLMs) like o1 have revolutionized artificial intelligence applications. Nevertheless, evaluating and optimizing complex reasoning processes remain significant challenges due to diverse policy distributions and the inherent limitations of human effort and accuracy. In this paper, we present AURORA, a novel automated framework for training universal process reward models (PRMs) using ensemble prompting and reverse verification. The framework employs a two-phase approach: First, it uses diverse prompting strategies and ensemble methods to perform automated annotation and evaluation of processes, ensuring robust assessments for reward learning. Second, it leverages practical reference answers for reverse verification, enhancing the model's ability to validate outputs and improving training accuracy. To assess the framework's performance, we extend beyond the existing ProcessBench benchmark by introducing UniversalBench, which evaluates reward predictions across full trajectories under diverse policy distribtion with long Chain-of-Thought (CoT) outputs. Experimental results demonstrate that AURORA enhances process evaluation accuracy, improves PRMs' accuracy for diverse policy distributions and long-CoT responses. The project will be open-sourced at https://auroraprm.github.io/. The Universal-PRM-7B is available at https://huggingface.co/infly/Universal-PRM-7B.
SCP-116K: A High-Quality Problem-Solution Dataset and a Generalized Pipeline for Automated Extraction in the Higher Education Science Domain
Jan 26, 2025

Recent breakthroughs in large language models (LLMs) exemplified by the impressive mathematical and scientific reasoning capabilities of the o1 model have spotlighted the critical importance of high-quality training data in advancing LLM performance across STEM disciplines. While the mathematics community has benefited from a growing body of curated datasets, the scientific domain at the higher education level has long suffered from a scarcity of comparable resources. To address this gap, we present SCP-116K, a new large-scale dataset of 116,756 high-quality problem-solution pairs, automatically extracted from heterogeneous sources using a streamlined and highly generalizable pipeline. Our approach involves stringent filtering to ensure the scientific rigor and educational level of the extracted materials, while maintaining adaptability for future expansions or domain transfers. By openly releasing both the dataset and the extraction pipeline, we seek to foster research on scientific reasoning, enable comprehensive performance evaluations of new LLMs, and lower the barrier to replicating the successes of advanced models like o1 in the broader science community. We believe SCP-116K will serve as a critical resource, catalyzing progress in high-level scientific reasoning tasks and promoting further innovations in LLM development. The dataset and code are publicly available at https://github.com/AQA6666/SCP-116K-open.