 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChen Zhang
On Elastic Language Models
Nov 13, 2023
Large-scale pretrained language models have achieved compelling performance in a wide range of language understanding and information retrieval tasks. Knowledge distillation offers an opportunity to compress a large language model to a small one, in order to reach a reasonable latency-performance tradeoff. However, for scenarios where the number of requests (e.g., queries submitted to a search engine) is highly variant, the static tradeoff attained by the compressed language model might not always fit. Once a model is assigned with a static tradeoff, it could be inadequate in that the latency is too high when the number of requests is large or the performance is too low when the number of requests is small. To this end, we propose an elastic language model (ElasticLM) that elastically adjusts the tradeoff according to the request stream. The basic idea is to introduce a compute elasticity to the compressed language model, so that the tradeoff could vary on-the-fly along scalable and controllable compute. Specifically, we impose an elastic structure to enable ElasticLM with compute elasticity and design an elastic optimization to learn ElasticLM under compute elasticity. To serve ElasticLM, we apply an elastic schedule. Considering the specificity of information retrieval, we adapt ElasticLM to dense retrieval and reranking and present ElasticDenser and ElasticRanker respectively. Offline evaluation is conducted on a language understanding benchmark GLUE; and several information retrieval tasks including Natural Question, Trivia QA, and MS MARCO. The results show that ElasticLM along with ElasticDenser and ElasticRanker can perform correctly and competitively compared with an array of static baselines. Furthermore, online simulation with concurrency is also carried out. The results demonstrate that ElasticLM can provide elastic tradeoffs with respect to varying request stream.
Towards the Law of Capacity Gap in Distilling Language Models
Nov 13, 2023Language model (LM) distillation is a trending area that aims to distil the knowledge resided in a large teacher LM to a small student one. While various methods have been proposed to push the distillation to its limits, it is still a pain distilling LMs when a large capacity gap is exhibited between the teacher and the student LMs. The pain is mainly resulted by the curse of capacity gap, which describes that a larger teacher LM cannot always lead to a better student LM than one distilled from a smaller teacher LM due to the affect of capacity gap increment. That is, there is likely an optimal point yielding the best student LM along the scaling course of the teacher LM. Even worse, the curse of capacity gap can be only partly yet not fully lifted as indicated in previous studies. However, the tale is not ever one-sided. Although a larger teacher LM has better performance than a smaller teacher LM, it is much more resource-demanding especially in the context of recent large LMs (LLMs). Consequently, instead of sticking to lifting the curse, leaving the curse as is should be arguably fine. Even better, in this paper, we reveal that the optimal capacity gap is almost consistent across different student scales and architectures, fortunately turning the curse into the law of capacity gap. The law later guides us to distil a 3B student LM (termed MiniMA) from a 7B teacher LM (adapted LLaMA2-7B). MiniMA is demonstrated to yield a new compute-performance pareto frontier among existing 3B LMs on commonly used benchmarks, and its instruction-tuned version (termed MiniChat) outperforms a wide range of 3B competitors in GPT4 evaluation and could even compete with several 7B chat models.
Sparse Contrastive Learning of Sentence Embeddings
Nov 07, 2023Recently, SimCSE has shown the feasibility of contrastive learning in training sentence embeddings and illustrates its expressiveness in spanning an aligned and uniform embedding space. However, prior studies have shown that dense models could contain harmful parameters that affect the model performance, and it is no wonder that SimCSE can as well be invented with such parameters. Driven by this, parameter sparsification is applied, where alignment and uniformity scores are used to measure the contribution of each parameter to the overall quality of sentence embeddings. Drawing from a preliminary study, we consider parameters with minimal contributions to be detrimental, as their sparsification results in improved model performance. To discuss the ubiquity of detrimental parameters and remove them, more experiments on the standard semantic textual similarity (STS) tasks and transfer learning tasks are conducted, and the results show that the proposed sparsified SimCSE (SparseCSE) has excellent performance in comparison with SimCSE. Furthermore, through in-depth analysis, we establish the validity and stability of our sparsification method, showcasing that the embedding space generated by SparseCSE exhibits improved alignment compared to that produced by SimCSE. Importantly, the uniformity yet remains uncompromised.
Choose A Table: Tensor Dirichlet Process Multinomial Mixture Model with Graphs for Passenger Trajectory Clustering
Oct 31, 2023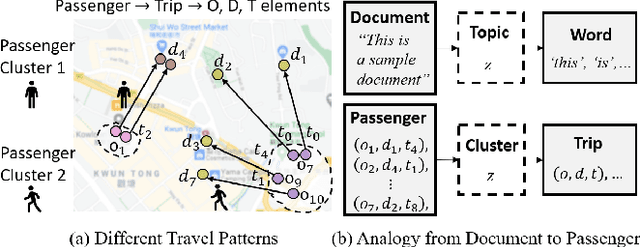
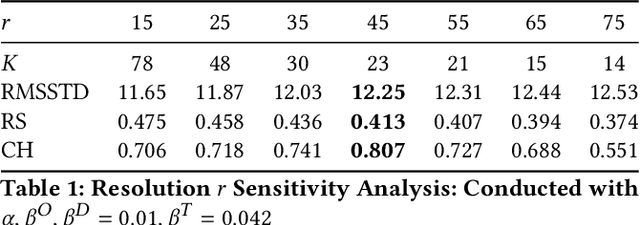
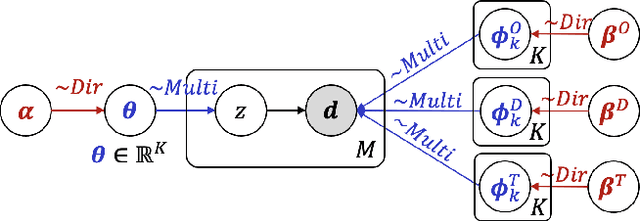
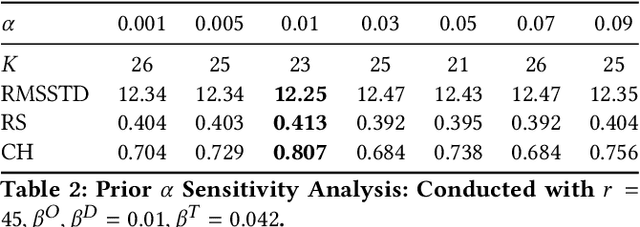
Passenger clustering based on trajectory records is essential for transportation operators. However, existing methods cannot easily cluster the passengers due to the hierarchical structure of the passenger trip information, including multiple trips within each passenger and multi-dimensional information about each trip. Furthermore, existing approaches rely on an accurate specification of the clustering number to start. Finally, existing methods do not consider spatial semantic graphs such as geographical proximity and functional similarity between the locations. In this paper, we propose a novel tensor Dirichlet Process Multinomial Mixture model with graphs, which can preserve the hierarchical structure of the multi-dimensional trip information and cluster them in a unified one-step manner with the ability to determine the number of clusters automatically. The spatial graphs are utilized in community detection to link the semantic neighbors. We further propose a tensor version of Collapsed Gibbs Sampling method with a minimum cluster size requirement. A case study based on Hong Kong metro passenger data is conducted to demonstrate the automatic process of cluster amount evolution and better cluster quality measured by within-cluster compactness and cross-cluster separateness. The code is available at https://github.com/bonaldli/TensorDPMM-G.
Underwater and Surface Aquatic Locomotion of Soft Biomimetic Robot Based on Bending Rolled Dielectric Elastomer Actuators
Oct 19, 2023All-around, real-time navigation and sensing across the water environments by miniature soft robotics are promising, for their merits of small size, high agility and good compliance to the unstructured surroundings. In this paper, we propose and demonstrate a mantas-like soft aquatic robot which propels itself by flapping-fins using rolled dielectric elastomer actuators (DEAs) with bending motions. This robot exhibits fast-moving capabilities of swimming at 57mm/s or 1.25 body length per second (BL/s), skating on water surface at 64 mm/s (1.36 BL/s) and vertical ascending at 38mm/s (0.82 BL/s) at 1300 V, 17 Hz of the power supply. These results show the feasibility of adopting rolled DEAs for mesoscale aquatic robots with high motion performance in various water-related scenarios.
xDial-Eval: A Multilingual Open-Domain Dialogue Evaluation Benchmark
Oct 13, 2023Recent advancements in reference-free learned metrics for open-domain dialogue evaluation have been driven by the progress in pre-trained language models and the availability of dialogue data with high-quality human annotations. However, current studies predominantly concentrate on English dialogues, and the generalization of these metrics to other languages has not been fully examined. This is largely due to the absence of a multilingual dialogue evaluation benchmark. To address the issue, we introduce xDial-Eval, built on top of open-source English dialogue evaluation datasets. xDial-Eval includes 12 turn-level and 6 dialogue-level English datasets, comprising 14930 annotated turns and 8691 annotated dialogues respectively. The English dialogue data are extended to nine other languages with commercial machine translation systems. On xDial-Eval, we conduct comprehensive analyses of previous BERT-based metrics and the recently-emerged large language models. Lastly, we establish strong self-supervised and multilingual baselines. In terms of average Pearson correlations over all datasets and languages, the best baseline outperforms OpenAI's ChatGPT by absolute improvements of 6.5% and 4.6% at the turn and dialogue levels respectively, albeit with much fewer parameters. The data and code are publicly available at https://github.com/e0397123/xDial-Eval.
Point-NeuS: Point-Guided Neural Implicit Surface Reconstruction by Volume Rendering
Oct 12, 2023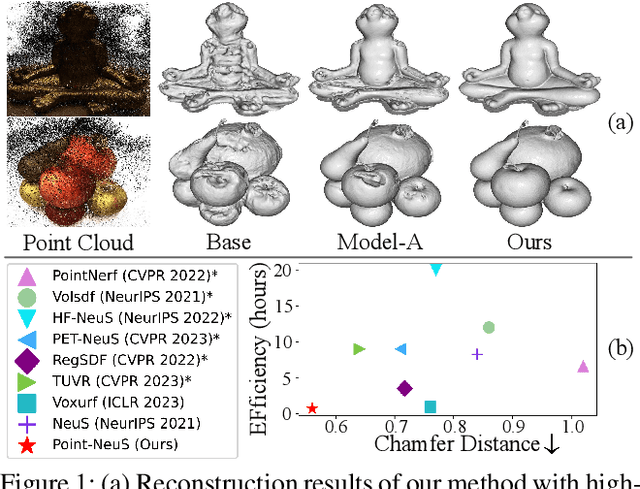
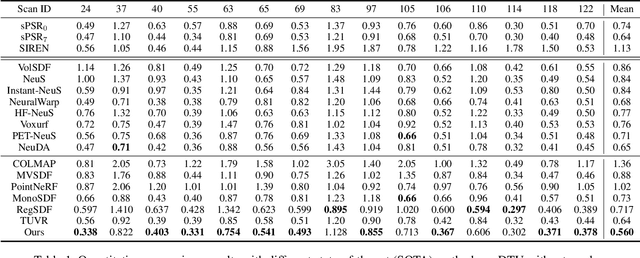
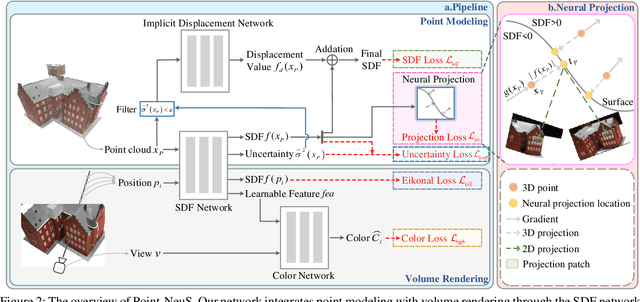

Recently, learning neural implicit surface by volume rendering has been a promising way for multi-view reconstruction. However, limited accuracy and excessive time complexity remain bottlenecks that current methods urgently need to overcome. To address these challenges, we propose a new method called Point-NeuS, utilizing point-guided mechanisms to achieve accurate and efficient reconstruction. Point modeling is organically embedded into the volume rendering to enhance and regularize the representation of implicit surface. Specifically, to achieve precise point guidance and noise robustness, aleatoric uncertainty of the point cloud is modeled to capture the distribution of noise and estimate the reliability of points. Additionally, a Neural Projection module connecting points and images is introduced to add geometric constraints to the Signed Distance Function (SDF). To better compensate for geometric bias between volume rendering and point modeling, high-fidelity points are filtered into an Implicit Displacement Network to improve the representation of SDF. Benefiting from our effective point guidance, lightweight networks are employed to achieve an impressive 11x speedup compared to NeuS. Extensive experiments show that our method yields high-quality surfaces, especially for fine-grained details and smooth regions. Moreover, it exhibits strong robustness to both noisy and sparse data.
Unsupervised Learning of Nanoindentation Data to Infer Microstructural Details of Complex Materials
Sep 12, 2023
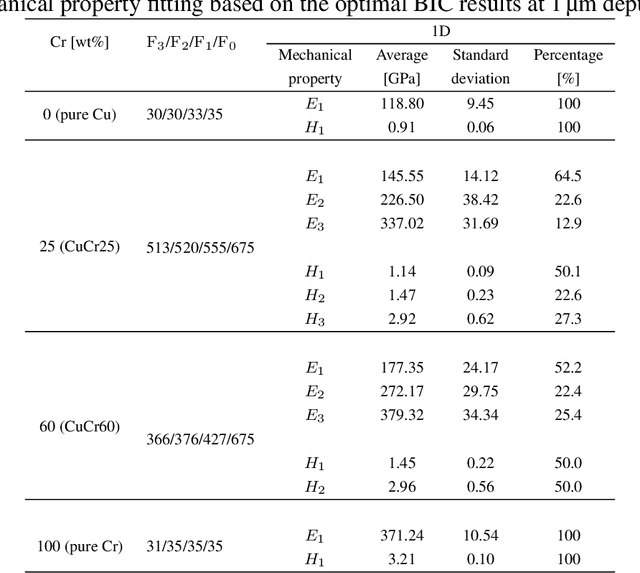
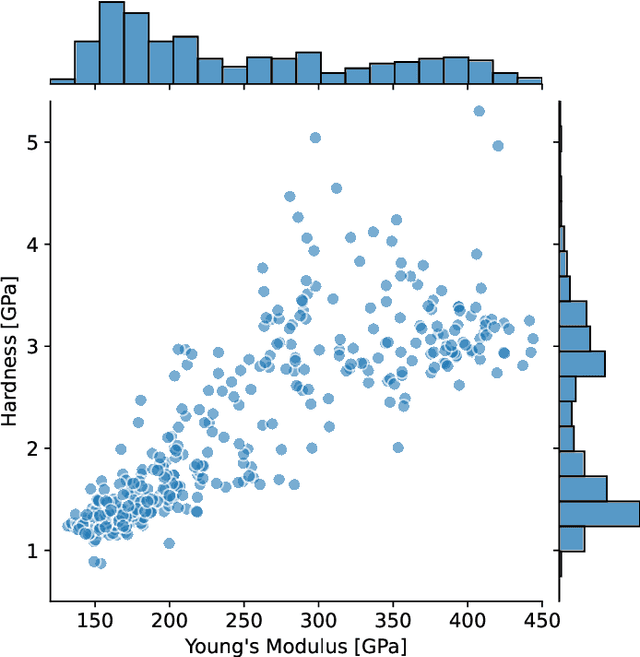
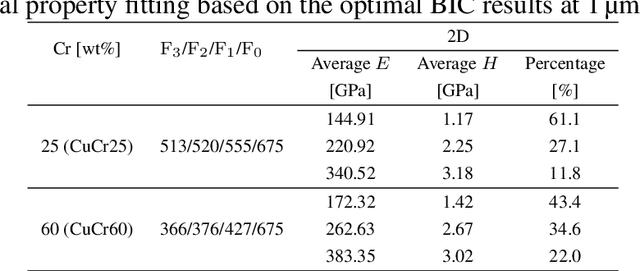
In this study, Cu-Cr composites were studied by nanoindentation. Arrays of indents were placed over large areas of the samples resulting in datasets consisting of several hundred measurements of Young's modulus and hardness at varying indentation depths. The unsupervised learning technique, Gaussian mixture model, was employed to analyze the data, which helped to determine the number of "mechanical phases" and the respective mechanical properties. Additionally, a cross-validation approach was introduced to infer whether the data quantity was adequate and to suggest the amount of data required for reliable predictions -- one of the often encountered but difficult to resolve issues in machine learning of materials science problems.
C2G2: Controllable Co-speech Gesture Generation with Latent Diffusion Model
Aug 29, 2023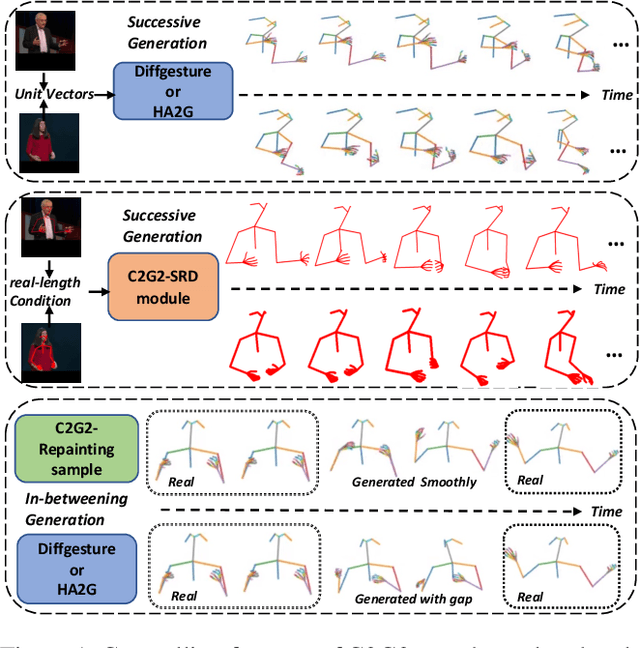
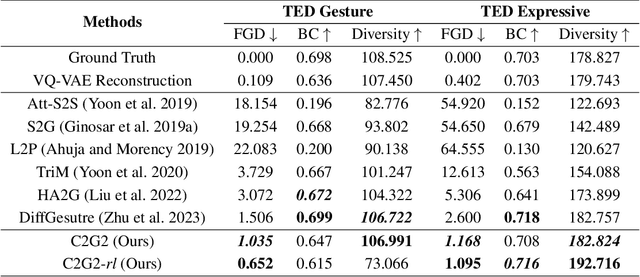
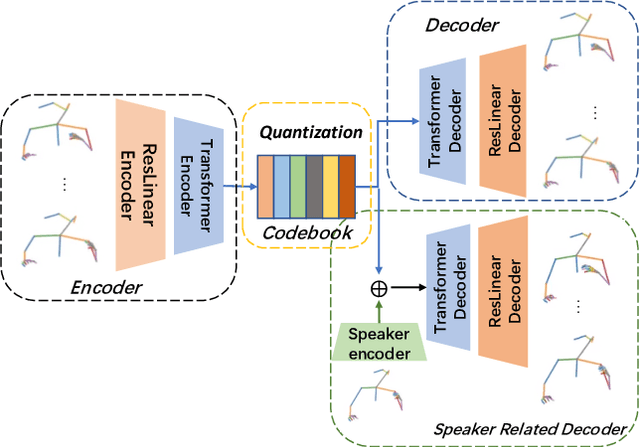

Co-speech gesture generation is crucial for automatic digital avatar animation. However, existing methods suffer from issues such as unstable training and temporal inconsistency, particularly in generating high-fidelity and comprehensive gestures. Additionally, these methods lack effective control over speaker identity and temporal editing of the generated gestures. Focusing on capturing temporal latent information and applying practical controlling, we propose a Controllable Co-speech Gesture Generation framework, named C2G2. Specifically, we propose a two-stage temporal dependency enhancement strategy motivated by latent diffusion models. We further introduce two key features to C2G2, namely a speaker-specific decoder to generate speaker-related real-length skeletons and a repainting strategy for flexible gesture generation/editing. Extensive experiments on benchmark gesture datasets verify the effectiveness of our proposed C2G2 compared with several state-of-the-art baselines. The link of the project demo page can be found at https://c2g2-gesture.github.io/c2_gesture
Point-aware Interaction and CNN-induced Refinement Network for RGB-D Salient Object Detection
Aug 17, 2023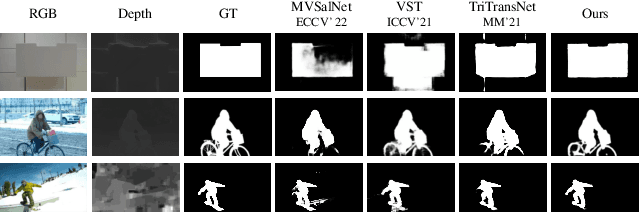
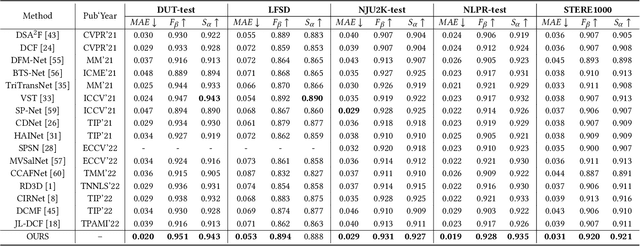
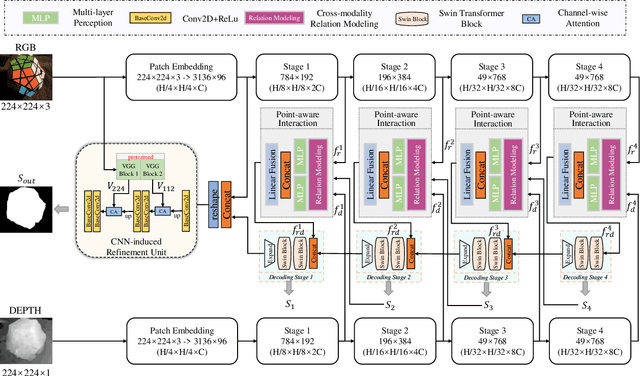
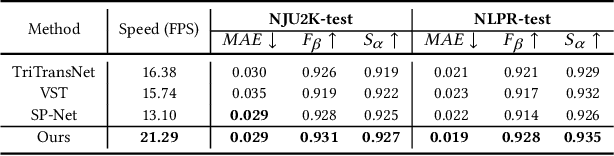
By integrating complementary information from RGB image and depth map, the ability of salient object detection (SOD) for complex and challenging scenes can be improved. In recent years, the important role of Convolutional Neural Networks (CNNs) in feature extraction and cross-modality interaction has been fully explored, but it is still insufficient in modeling global long-range dependencies of self-modality and cross-modality. To this end, we introduce CNNs-assisted Transformer architecture and propose a novel RGB-D SOD network with Point-aware Interaction and CNN-induced Refinement (PICR-Net). On the one hand, considering the prior correlation between RGB modality and depth modality, an attention-triggered cross-modality point-aware interaction (CmPI) module is designed to explore the feature interaction of different modalities with positional constraints. On the other hand, in order to alleviate the block effect and detail destruction problems brought by the Transformer naturally, we design a CNN-induced refinement (CNNR) unit for content refinement and supplementation. Extensive experiments on five RGB-D SOD datasets show that the proposed network achieves competitive results in both quantitative and qualitative comparisons.