 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCuBridge: An LLM-Based Framework for Understanding and Reconstructing High-Performance Attention Kernels
May 06, 2026Efficient CUDA implementations of attention mechanisms are critical to modern deep learning systems, yet supporting diverse and evolving attention variants remains challenging. Existing frameworks and compilers trade performance for flexibility, while expert-written kernels achieve high efficiency but are difficult to adapt. Recent work explores large language models (LLMs) for GPU kernel generation, but prior studies report unstable correctness and significant performance gaps for complex operators such as attention. We present CuBridge, an LLM-based framework that adapts expert-written attention kernels through a structured lift-transfer-lower workflow. CuBridge starts from expert-written CUDA attention kernels and lifts them into an executable intermediate representation that makes execution orchestration explicit while abstracting low-level CUDA syntax. Given a user-provided PyTorch specification, CuBridge generates and verifies a target IR program, then reconstructs optimized CUDA code via reference-guided lowering. Across diverse attention variants and GPU platforms, CuBridge consistently produces correct kernels and substantially outperforms general frameworks, compiler-based approaches, and prior LLM-based methods.
Yggdrasil: Bridging Dynamic Speculation and Static Runtime for Latency-Optimal Tree-Based LLM Decoding
Dec 29, 2025Speculative decoding improves LLM inference by generating and verifying multiple tokens in parallel, but existing systems suffer from suboptimal performance due to a mismatch between dynamic speculation and static runtime assumptions. We present Yggdrasil, a co-designed system that enables latency-optimal speculative decoding through context-aware tree drafting and compiler-friendly execution. Yggdrasil introduces an equal-growth tree structure for static graph compatibility, a latency-aware optimization objective for draft selection, and stage-based scheduling to reduce overhead. Yggdrasil supports unmodified LLMs and achieves up to $3.98\times$ speedup over state-of-the-art baselines across multiple hardware setups.
ClusterFusion: Expanding Operator Fusion Scope for LLM Inference via Cluster-Level Collective Primitive
Aug 26, 2025



Large language model (LLM) decoding suffers from high latency due to fragmented execution across operators and heavy reliance on off-chip memory for data exchange and reduction. This execution model limits opportunities for fusion and incurs significant memory traffic and kernel launch overhead. While modern architectures such as NVIDIA Hopper provide distributed shared memory and low-latency intra-cluster interconnects, they expose only low-level data movement instructions, lacking structured abstractions for collective on-chip communication. To bridge this software-hardware gap, we introduce two cluster-level communication primitives, ClusterReduce and ClusterGather, which abstract common communication patterns and enable structured, high-speed data exchange and reduction between thread blocks within a cluster, allowing intermediate results to be on-chip without involving off-chip memory. Building on these abstractions, we design ClusterFusion, an execution framework that schedules communication and computation jointly to expand operator fusion scope by composing decoding stages such as QKV Projection, Attention, and Output Projection into a single fused kernels. Evaluations on H100 GPUs show that ClusterFusion outperforms state-of-the-art inference frameworks by 1.61x on average in end-to-end latency across different models and configurations. The source code is available at https://github.com/xinhao-luo/ClusterFusion.
Accelerating Generic Graph Neural Networks via Architecture, Compiler, Partition Method Co-Design
Aug 16, 2023Graph neural networks (GNNs) have shown significant accuracy improvements in a variety of graph learning domains, sparking considerable research interest. To translate these accuracy improvements into practical applications, it is essential to develop high-performance and efficient hardware acceleration for GNN models. However, designing GNN accelerators faces two fundamental challenges: the high bandwidth requirement of GNN models and the diversity of GNN models. Previous works have addressed the first challenge by using more expensive memory interfaces to achieve higher bandwidth. For the second challenge, existing works either support specific GNN models or have generic designs with poor hardware utilization. In this work, we tackle both challenges simultaneously. First, we identify a new type of partition-level operator fusion, which we utilize to internally reduce the high bandwidth requirement of GNNs. Next, we introduce partition-level multi-threading to schedule the concurrent processing of graph partitions, utilizing different hardware resources. To further reduce the extra on-chip memory required by multi-threading, we propose fine-grained graph partitioning to generate denser graph partitions. Importantly, these three methods make no assumptions about the targeted GNN models, addressing the challenge of model variety. We implement these methods in a framework called SwitchBlade, consisting of a compiler, a graph partitioner, and a hardware accelerator. Our evaluation demonstrates that SwitchBlade achieves an average speedup of $1.85\times$ and energy savings of $19.03\times$ compared to the NVIDIA V100 GPU. Additionally, SwitchBlade delivers performance comparable to state-of-the-art specialized accelerators.
AdaptGear: Accelerating GNN Training via Adaptive Subgraph-Level Kernels on GPUs
May 27, 2023



Graph neural networks (GNNs) are powerful tools for exploring and learning from graph structures and features. As such, achieving high-performance execution for GNNs becomes crucially important. Prior works have proposed to explore the sparsity (i.e., low density) in the input graph to accelerate GNNs, which uses the full-graph-level or block-level sparsity format. We show that they fail to balance the sparsity benefit and kernel execution efficiency. In this paper, we propose a novel system, referred to as AdaptGear, that addresses the challenge of optimizing GNNs performance by leveraging kernels tailored to the density characteristics at the subgraph level. Meanwhile, we also propose a method that dynamically chooses the optimal set of kernels for a given input graph. Our evaluation shows that AdaptGear can achieve a significant performance improvement, up to $6.49 \times$ ($1.87 \times$ on average), over the state-of-the-art works on two mainstream NVIDIA GPUs across various datasets.
Efficient Activation Quantization via Adaptive Rounding Border for Post-Training Quantization
Aug 25, 2022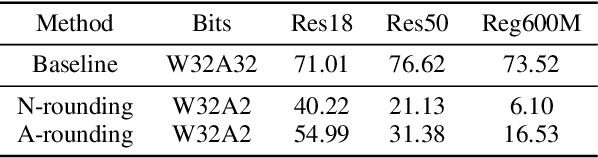
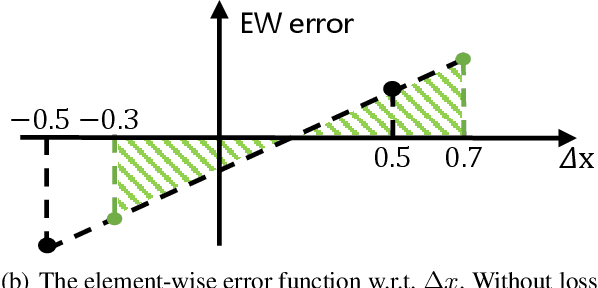
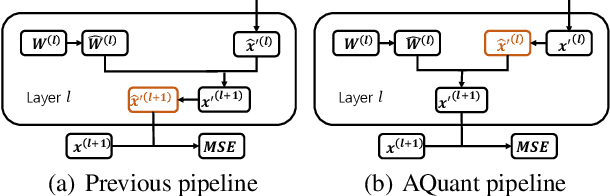
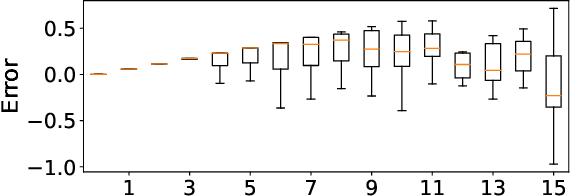
Post-training quantization (PTQ) attracts increasing attention due to its convenience in deploying quantized neural networks. Rounding, the primary source of quantization error, is optimized only for model weights, while activations still use the rounding-to-nearest operation. In this work, for the first time, we demonstrate that well-chosen rounding schemes for activations can improve the final accuracy. To deal with the challenge of the dynamicity of the activation rounding scheme, we adaptively adjust the rounding border through a simple function to generate rounding schemes at the inference stage. The border function covers the impact of weight errors, activation errors, and propagated errors to eliminate the bias of the element-wise error, which further benefits model accuracy. We also make the border aware of global errors to better fit different arriving activations. Finally, we propose the AQuant framework to learn the border function. Extensive experiments show that AQuant achieves noticeable improvements with negligible overhead compared with state-of-the-art works and pushes the accuracy of ResNet-18 up to 60.3\% under the 2-bit weight and activation post-training quantization.
Balancing Efficiency and Flexibility for DNN Acceleration via Temporal GPU-Systolic Array Integration
Feb 18, 2020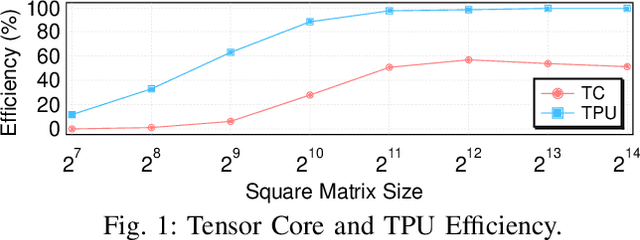
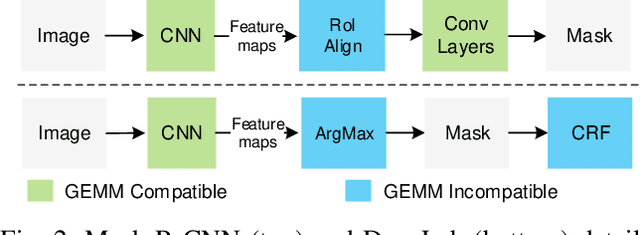

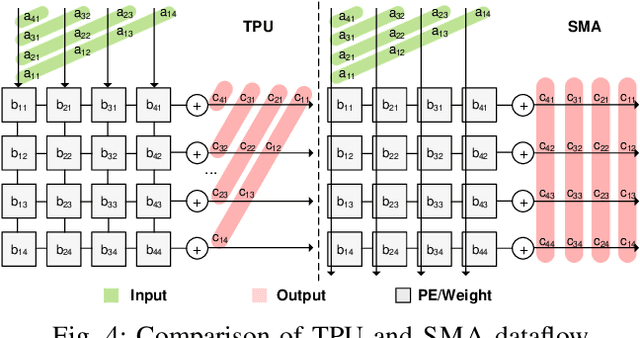
The research interest in specialized hardware accelerators for deep neural networks (DNN) spiked recently owing to their superior performance and efficiency. However, today's DNN accelerators primarily focus on accelerating specific "kernels" such as convolution and matrix multiplication, which are vital but only part of an end-to-end DNN-enabled application. Meaningful speedups over the entire application often require supporting computations that are, while massively parallel, ill-suited to DNN accelerators. Integrating a general-purpose processor such as a CPU or a GPU incurs significant data movement overhead and leads to resource under-utilization on the DNN accelerators. We propose Simultaneous Multi-mode Architecture (SMA), a novel architecture design and execution model that offers general-purpose programmability on DNN accelerators in order to accelerate end-to-end applications. The key to SMA is the temporal integration of the systolic execution model with the GPU-like SIMD execution model. The SMA exploits the common components shared between the systolic-array accelerator and the GPU, and provides lightweight reconfiguration capability to switch between the two modes in-situ. The SMA achieves up to 63% performance improvement while consuming 23% less energy than the baseline Volta architecture with TensorCore.