 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Survey on LLM Mid-training
Oct 27, 2025Recent advances in foundation models have highlighted the significant benefits of multi-stage training, with a particular emphasis on the emergence of mid-training as a vital stage that bridges pre-training and post-training. Mid-training is distinguished by its use of intermediate data and computational resources, systematically enhancing specified capabilities such as mathematics, coding, reasoning, and long-context extension, while maintaining foundational competencies. This survey provides a formal definition of mid-training for large language models (LLMs) and investigates optimization frameworks that encompass data curation, training strategies, and model architecture optimization. We analyze mainstream model implementations in the context of objective-driven interventions, illustrating how mid-training serves as a distinct and critical stage in the progressive development of LLM capabilities. By clarifying the unique contributions of mid-training, this survey offers a comprehensive taxonomy and actionable insights, supporting future research and innovation in the advancement of LLMs.
Efficient Learning of Optimal Markov Network Topology with k-Tree Modeling
Jan 21, 2018The seminal work of Chow and Liu (1968) shows that approximation of a finite probabilistic system by Markov trees can achieve the minimum information loss with the topology of a maximum spanning tree. Our current paper generalizes the result to Markov networks of tree width $\leq k$, for every fixed $k\geq 2$. In particular, we prove that approximation of a finite probabilistic system with such Markov networks has the minimum information loss when the network topology is achieved with a maximum spanning $k$-tree. While constructing a maximum spanning $k$-tree is intractable for even $k=2$, we show that polynomial algorithms can be ensured by a sufficient condition accommodated by many meaningful applications. In particular, we prove an efficient algorithm for learning the optimal topology of higher order correlations among random variables that belong to an underlying linear structure.
Stock Prediction: a method based on extraction of news features and recurrent neural networks
Jul 19, 2017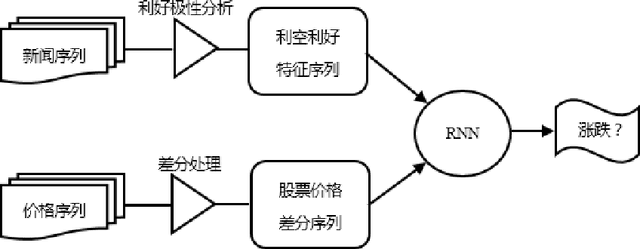
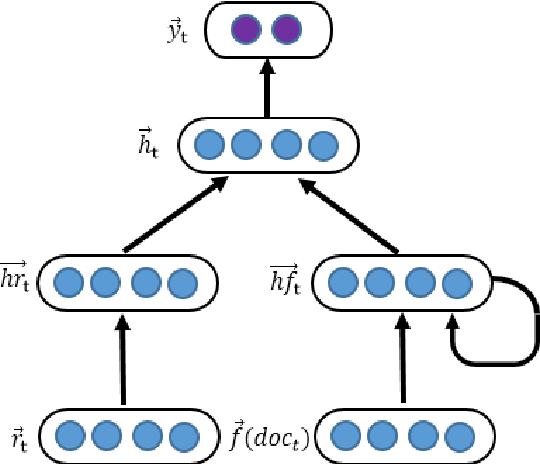
This paper proposed a method for stock prediction. In terms of feature extraction, we extract the features of stock-related news besides stock prices. We first select some seed words based on experience which are the symbols of good news and bad news. Then we propose an optimization method and calculate the positive polar of all words. After that, we construct the features of news based on the positive polar of their words. In consideration of sequential stock prices and continuous news effects, we propose a recurrent neural network model to help predict stock prices. Compared to SVM classifier with price features, we find our proposed method has an over 5% improvement on stock prediction accuracy in experiments.