 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeARC-Hunyuan-Video-7B: Structured Video Comprehension of Real-World Shorts
Jul 28, 2025Real-world user-generated short videos, especially those distributed on platforms such as WeChat Channel and TikTok, dominate the mobile internet. However, current large multimodal models lack essential temporally-structured, detailed, and in-depth video comprehension capabilities, which are the cornerstone of effective video search and recommendation, as well as emerging video applications. Understanding real-world shorts is actually challenging due to their complex visual elements, high information density in both visuals and audio, and fast pacing that focuses on emotional expression and viewpoint delivery. This requires advanced reasoning to effectively integrate multimodal information, including visual, audio, and text. In this work, we introduce ARC-Hunyuan-Video, a multimodal model that processes visual, audio, and textual signals from raw video inputs end-to-end for structured comprehension. The model is capable of multi-granularity timestamped video captioning and summarization, open-ended video question answering, temporal video grounding, and video reasoning. Leveraging high-quality data from an automated annotation pipeline, our compact 7B-parameter model is trained through a comprehensive regimen: pre-training, instruction fine-tuning, cold start, reinforcement learning (RL) post-training, and final instruction fine-tuning. Quantitative evaluations on our introduced benchmark ShortVid-Bench and qualitative comparisons demonstrate its strong performance in real-world video comprehension, and it supports zero-shot or fine-tuning with a few samples for diverse downstream applications. The real-world production deployment of our model has yielded tangible and measurable improvements in user engagement and satisfaction, a success supported by its remarkable efficiency, with stress tests indicating an inference time of just 10 seconds for a one-minute video on H20 GPU.
Aime: Towards Fully-Autonomous Multi-Agent Framework
Jul 16, 2025Multi-Agent Systems (MAS) powered by Large Language Models (LLMs) are emerging as a powerful paradigm for solving complex, multifaceted problems. However, the potential of these systems is often constrained by the prevalent plan-and-execute framework, which suffers from critical limitations: rigid plan execution, static agent capabilities, and inefficient communication. These weaknesses hinder their adaptability and robustness in dynamic environments. This paper introduces Aime, a novel multi-agent framework designed to overcome these challenges through dynamic, reactive planning and execution. Aime replaces the conventional static workflow with a fluid and adaptive architecture. Its core innovations include: (1) a Dynamic Planner that continuously refines the overall strategy based on real-time execution feedback; (2) an Actor Factory that implements Dynamic Actor instantiation, assembling specialized agents on-demand with tailored tools and knowledge; and (3) a centralized Progress Management Module that serves as a single source of truth for coherent, system-wide state awareness. We empirically evaluated Aime on a diverse suite of benchmarks spanning general reasoning (GAIA), software engineering (SWE-bench Verified), and live web navigation (WebVoyager). The results demonstrate that Aime consistently outperforms even highly specialized state-of-the-art agents in their respective domains. Its superior adaptability and task success rate establish Aime as a more resilient and effective foundation for multi-agent collaboration.
Reconstructing Close Human Interaction with Appearance and Proxemics Reasoning
Jul 03, 2025Due to visual ambiguities and inter-person occlusions, existing human pose estimation methods cannot recover plausible close interactions from in-the-wild videos. Even state-of-the-art large foundation models~(\eg, SAM) cannot accurately distinguish human semantics in such challenging scenarios. In this work, we find that human appearance can provide a straightforward cue to address these obstacles. Based on this observation, we propose a dual-branch optimization framework to reconstruct accurate interactive motions with plausible body contacts constrained by human appearances, social proxemics, and physical laws. Specifically, we first train a diffusion model to learn the human proxemic behavior and pose prior knowledge. The trained network and two optimizable tensors are then incorporated into a dual-branch optimization framework to reconstruct human motions and appearances. Several constraints based on 3D Gaussians, 2D keypoints, and mesh penetrations are also designed to assist the optimization. With the proxemics prior and diverse constraints, our method is capable of estimating accurate interactions from in-the-wild videos captured in complex environments. We further build a dataset with pseudo ground-truth interaction annotations, which may promote future research on pose estimation and human behavior understanding. Experimental results on several benchmarks demonstrate that our method outperforms existing approaches. The code and data are available at https://www.buzhenhuang.com/works/CloseApp.html.
Gradients of unitary optical neural networks using parameter-shift rule
Jun 13, 2025This paper explores the application of the parameter-shift rule (PSR) for computing gradients in unitary optical neural networks (UONNs). While backpropagation has been fundamental to training conventional neural networks, its implementation in optical neural networks faces significant challenges due to the physical constraints of optical systems. We demonstrate how PSR, which calculates gradients by evaluating functions at shifted parameter values, can be effectively adapted for training UONNs constructed from Mach-Zehnder interferometer meshes. The method leverages the inherent Fourier series nature of optical interference in these systems to compute exact analytical gradients directly from hardware measurements. This approach offers a promising alternative to traditional in silico training methods and circumvents the limitations of both finite difference approximations and all-optical backpropagation implementations. We present the theoretical framework and practical methodology for applying PSR to optimize phase parameters in optical neural networks, potentially advancing the development of efficient hardware-based training strategies for optical computing systems.
The Butterfly Effect in Pathology: Exploring Security in Pathology Foundation Models
May 30, 2025With the widespread adoption of pathology foundation models in both research and clinical decision support systems, exploring their security has become a critical concern. However, despite their growing impact, the vulnerability of these models to adversarial attacks remains largely unexplored. In this work, we present the first systematic investigation into the security of pathology foundation models for whole slide image~(WSI) analysis against adversarial attacks. Specifically, we introduce the principle of \textit{local perturbation with global impact} and propose a label-free attack framework that operates without requiring access to downstream task labels. Under this attack framework, we revise four classical white-box attack methods and redefine the perturbation budget based on the characteristics of WSI. We conduct comprehensive experiments on three representative pathology foundation models across five datasets and six downstream tasks. Despite modifying only 0.1\% of patches per slide with imperceptible noise, our attack leads to downstream accuracy degradation that can reach up to 20\% in the worst cases. Furthermore, we analyze key factors that influence attack success, explore the relationship between patch-level vulnerability and semantic content, and conduct a preliminary investigation into potential defence strategies. These findings lay the groundwork for future research on the adversarial robustness and reliable deployment of pathology foundation models. Our code is publicly available at: https://github.com/Jiashuai-Liu-hmos/Attack-WSI-pathology-foundation-models.
Unleashing High-Quality Image Generation in Diffusion Sampling Using Second-Order Levenberg-Marquardt-Langevin
May 30, 2025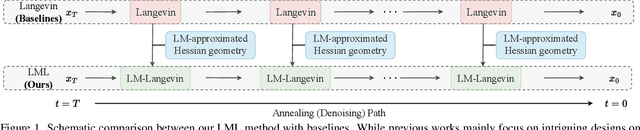


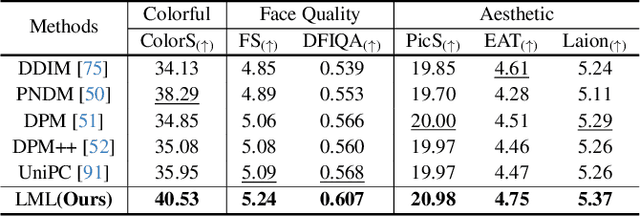
The diffusion models (DMs) have demonstrated the remarkable capability of generating images via learning the noised score function of data distribution. Current DM sampling techniques typically rely on first-order Langevin dynamics at each noise level, with efforts concentrated on refining inter-level denoising strategies. While leveraging additional second-order Hessian geometry to enhance the sampling quality of Langevin is a common practice in Markov chain Monte Carlo (MCMC), the naive attempts to utilize Hessian geometry in high-dimensional DMs lead to quadratic-complexity computational costs, rendering them non-scalable. In this work, we introduce a novel Levenberg-Marquardt-Langevin (LML) method that approximates the diffusion Hessian geometry in a training-free manner, drawing inspiration from the celebrated Levenberg-Marquardt optimization algorithm. Our approach introduces two key innovations: (1) A low-rank approximation of the diffusion Hessian, leveraging the DMs' inherent structure and circumventing explicit quadratic-complexity computations; (2) A damping mechanism to stabilize the approximated Hessian. This LML approximated Hessian geometry enables the diffusion sampling to execute more accurate steps and improve the image generation quality. We further conduct a theoretical analysis to substantiate the approximation error bound of low-rank approximation and the convergence property of the damping mechanism. Extensive experiments across multiple pretrained DMs validate that the LML method significantly improves image generation quality, with negligible computational overhead.
Efficiently Access Diffusion Fisher: Within the Outer Product Span Space
May 29, 2025Recent Diffusion models (DMs) advancements have explored incorporating the second-order diffusion Fisher information (DF), defined as the negative Hessian of log density, into various downstream tasks and theoretical analysis. However, current practices typically approximate the diffusion Fisher by applying auto-differentiation to the learned score network. This black-box method, though straightforward, lacks any accuracy guarantee and is time-consuming. In this paper, we show that the diffusion Fisher actually resides within a space spanned by the outer products of score and initial data. Based on the outer-product structure, we develop two efficient approximation algorithms to access the trace and matrix-vector multiplication of DF, respectively. These algorithms bypass the auto-differentiation operations with time-efficient vector-product calculations. Furthermore, we establish the approximation error bounds for the proposed algorithms. Experiments in likelihood evaluation and adjoint optimization demonstrate the superior accuracy and reduced computational cost of our proposed algorithms. Additionally, based on the novel outer-product formulation of DF, we design the first numerical verification experiment for the optimal transport property of the general PF-ODE deduced map.
MCTSr-Zero: Self-Reflective Psychological Counseling Dialogues Generation via Principles and Adaptive Exploration
May 29, 2025The integration of Monte Carlo Tree Search (MCTS) with Large Language Models (LLMs) has demonstrated significant success in structured, problem-oriented tasks. However, applying these methods to open-ended dialogues, such as those in psychological counseling, presents unique challenges. Unlike tasks with objective correctness, success in therapeutic conversations depends on subjective factors like empathetic engagement, ethical adherence, and alignment with human preferences, for which strict "correctness" criteria are ill-defined. Existing result-oriented MCTS approaches can therefore produce misaligned responses. To address this, we introduce MCTSr-Zero, an MCTS framework designed for open-ended, human-centric dialogues. Its core innovation is "domain alignment", which shifts the MCTS search objective from predefined end-states towards conversational trajectories that conform to target domain principles (e.g., empathy in counseling). Furthermore, MCTSr-Zero incorporates "Regeneration" and "Meta-Prompt Adaptation" mechanisms to substantially broaden exploration by allowing the MCTS to consider fundamentally different initial dialogue strategies. We evaluate MCTSr-Zero in psychological counseling by generating multi-turn dialogue data, which is used to fine-tune an LLM, PsyLLM. We also introduce PsyEval, a benchmark for assessing multi-turn psychological counseling dialogues. Experiments demonstrate that PsyLLM achieves state-of-the-art performance on PsyEval and other relevant metrics, validating MCTSr-Zero's effectiveness in generating high-quality, principle-aligned conversational data for human-centric domains and addressing the LLM challenge of consistently adhering to complex psychological standards.
Hunyuan-TurboS: Advancing Large Language Models through Mamba-Transformer Synergy and Adaptive Chain-of-Thought
May 21, 2025As Large Language Models (LLMs) rapidly advance, we introduce Hunyuan-TurboS, a novel large hybrid Transformer-Mamba Mixture of Experts (MoE) model. It synergistically combines Mamba's long-sequence processing efficiency with Transformer's superior contextual understanding. Hunyuan-TurboS features an adaptive long-short chain-of-thought (CoT) mechanism, dynamically switching between rapid responses for simple queries and deep "thinking" modes for complex problems, optimizing computational resources. Architecturally, this 56B activated (560B total) parameter model employs 128 layers (Mamba2, Attention, FFN) with an innovative AMF/MF block pattern. Faster Mamba2 ensures linear complexity, Grouped-Query Attention minimizes KV cache, and FFNs use an MoE structure. Pre-trained on 16T high-quality tokens, it supports a 256K context length and is the first industry-deployed large-scale Mamba model. Our comprehensive post-training strategy enhances capabilities via Supervised Fine-Tuning (3M instructions), a novel Adaptive Long-short CoT Fusion method, Multi-round Deliberation Learning for iterative improvement, and a two-stage Large-scale Reinforcement Learning process targeting STEM and general instruction-following. Evaluations show strong performance: overall top 7 rank on LMSYS Chatbot Arena with a score of 1356, outperforming leading models like Gemini-2.0-Flash-001 (1352) and o4-mini-2025-04-16 (1345). TurboS also achieves an average of 77.9% across 23 automated benchmarks. Hunyuan-TurboS balances high performance and efficiency, offering substantial capabilities at lower inference costs than many reasoning models, establishing a new paradigm for efficient large-scale pre-trained models.
Towards Efficient Multi-Scale Deformable Attention on NPU
May 20, 2025



Multi-scale deformable attention (MSDA) is a flexible and powerful feature extraction mechanism for visual tasks, but its random-access grid sampling strategy poses significant optimization challenges, especially on domain-specific accelerators such as NPUs. In this work, we present a co-design approach that systematically rethinks memory access and computation strategies for MSDA on the Ascend NPU architecture. With this co-design approach, our implementation supports both efficient forward and backward computation, is fully adapted for training workloads, and incorporates a suite of hardware-aware optimizations. Extensive experiments show that our solution achieves up to $5.9\times$ (forward), $8.9\times$ (backward), and $7.3\times$ (end-to-end training) speedup over the grid sample-based baseline, and $1.9\times$, $2.4\times$, and $2.0\times$ acceleration over the latest vendor library, respectively.