 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFeature Entanglement-based Quantum Multimodal Fusion Neural Network
Jan 09, 2026Multimodal learning aims to enhance perceptual and decision-making capabilities by integrating information from diverse sources. However, classical deep learning approaches face a critical trade-off between the high accuracy of black-box feature-level fusion and the interpretability of less outstanding decision-level fusion, alongside the challenges of parameter explosion and complexity. This paper discusses the accuracy-interpretablity-complexity dilemma under the quantum computation framework and propose a feature entanglement-based quantum multimodal fusion neural network. The model is composed of three core components: a classical feed-forward module for unimodal processing, an interpretable quantum fusion block, and a quantum convolutional neural network (QCNN) for deep feature extraction. By leveraging the strong expressive power of quantum, we have reduced the complexity of multimodal fusion and post-processing to linear, and the fusion process also possesses the interpretability of decision-level fusion. The simulation results demonstrate that our model achieves classification accuracy comparable to classical networks with dozens of times of parameters, exhibiting notable stability and performance across multimodal image datasets.
Aime: Towards Fully-Autonomous Multi-Agent Framework
Jul 16, 2025

Multi-Agent Systems (MAS) powered by Large Language Models (LLMs) are emerging as a powerful paradigm for solving complex, multifaceted problems. However, the potential of these systems is often constrained by the prevalent plan-and-execute framework, which suffers from critical limitations: rigid plan execution, static agent capabilities, and inefficient communication. These weaknesses hinder their adaptability and robustness in dynamic environments. This paper introduces Aime, a novel multi-agent framework designed to overcome these challenges through dynamic, reactive planning and execution. Aime replaces the conventional static workflow with a fluid and adaptive architecture. Its core innovations include: (1) a Dynamic Planner that continuously refines the overall strategy based on real-time execution feedback; (2) an Actor Factory that implements Dynamic Actor instantiation, assembling specialized agents on-demand with tailored tools and knowledge; and (3) a centralized Progress Management Module that serves as a single source of truth for coherent, system-wide state awareness. We empirically evaluated Aime on a diverse suite of benchmarks spanning general reasoning (GAIA), software engineering (SWE-bench Verified), and live web navigation (WebVoyager). The results demonstrate that Aime consistently outperforms even highly specialized state-of-the-art agents in their respective domains. Its superior adaptability and task success rate establish Aime as a more resilient and effective foundation for multi-agent collaboration.
Real-time Streaming Wave-U-Net with Temporal Convolutions for Multichannel Speech Enhancement
Apr 05, 2021
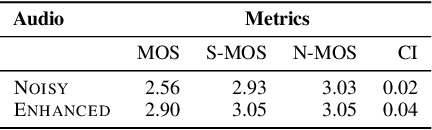
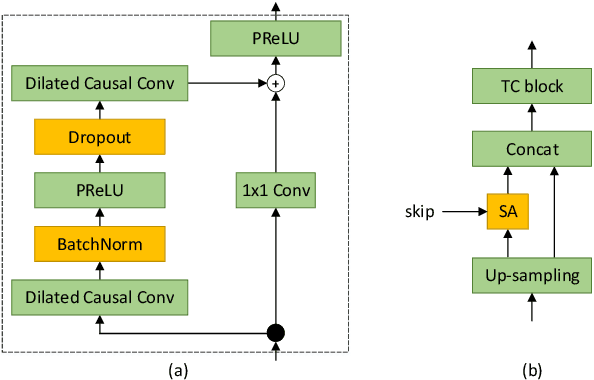

In this paper, we describe the work that we have done to participate in Task1 of the ConferencingSpeech2021 challenge. This task set a goal to develop the solution for multi-channel speech enhancement in a real-time manner. We propose a novel system for streaming speech enhancement. We employ Wave-U-Net architecture with temporal convolutions in encoder and decoder. We incorporate self-attention in the decoder to apply attention mask retrieved from skip-connection on features from down-blocks. We explore history cache mechanisms that work like hidden states in recurrent networks and implemented them in proposal solution. It helps us to run an inference with chunks length 40ms and Real-Time Factor 0.4 with the same precision.