 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStableMind: Source-Free Cross-Subject fMRI Decoding with Regularized Adaptation
May 04, 2026Existing cross-subject fMRI decoding methods typically train a model on multiple scanned subjects and then adapt it to a new subject using substantial paired fMRI-image data. However, in realistic scenarios, new-subject fMRI data are often limited due to costly data acquisition, and raw data from previous subjects may be inaccessible, leading existing methods to suffer performance degradation during new-subject adaptation. In this paper, we identify that this degradation stems from two key issues: brain-side instability caused by large subject differences in fMRI responses, and image-side supervision unreliability caused by fine-grained visual details that are not reliably supported by limited fMRI signals. To address these challenges, we propose StableMind, a regularized adaptation framework designed to improve brain-side representation stability and image-side supervision reliability. (1) To stabilize brain representations, StableMind reuses ridge projections from the pretrained model as adaptation priors to constrain limited-data new-subject adaptation, and applies Fourier-based feature-level brain augmentation to improve robustness to individual variability. (2) To improve image supervision reliability, StableMind introduces difficulty-aware image blur for brain-image alignment, reducing the influence of fine-grained visual details that are weakly supported by limited fMRI signals while preserving stable visual structure. Experiments on the Natural Scenes Dataset under a unified 1-hour adaptation protocol demonstrate that StableMind achieves 84.02% image retrieval accuracy and 81.66% brain retrieval accuracy averaged over four subjects, surpassing the state-of-the-art method by 5.71% brain retrieval accuracy with fewer trainable adaptation parameters. Our code is available at https://github.com/lingeringlight/StableMind.
Duala: Dual-Level Alignment of Subjects and Stimuli for Cross-Subject fMRI Decoding
Mar 08, 2026Cross-subject visual decoding aims to reconstruct visual experiences from brain activity across individuals, enabling more scalable and practical brain-computer interfaces. However, existing methods often suffer from degraded performance when adapting to new subjects with limited data, as they struggle to preserve both the semantic consistency of stimuli and the alignment of brain responses. To address these challenges, we propose Duala, a dual-level alignment framework designed to achieve stimulus-level consistency and subject-level alignment in fMRI-based cross-subject visual decoding. (1) At the stimulus level, Duala introduces a semantic alignment and relational consistency strategy that preserves intra-class similarity and inter-class separability, maintaining clear semantic boundaries during adaptation. (2) At the subject level, a distribution-based feature perturbation mechanism is developed to capture both global and subject-specific variations, enabling adaptation to individual neural representations without overfitting. Experiments on the Natural Scenes Dataset (NSD) demonstrate that Duala effectively improves alignment across subjects. Remarkably, even when fine-tuned with only about one hour of fMRI data, Duala achieves over 81.1% image-to-brain retrieval accuracy and consistently outperforms existing fine-tuning strategies in both retrieval and reconstruction. Our code is available at https://github.com/ShumengLI/Duala.
Empirical-MCTS: Continuous Agent Evolution via Dual-Experience Monte Carlo Tree Search
Feb 04, 2026Inference-time scaling strategies, particularly Monte Carlo Tree Search (MCTS), have significantly enhanced the reasoning capabilities of Large Language Models (LLMs). However, current approaches remain predominantly stateless, discarding successful reasoning patterns after each problem instance and failing to mimic the empirical accumulation of wisdom characteristic of human problem-solving. To bridge this gap, we introduce Empirical-MCTS, a dual-loop framework that transforms stateless search into a continuous, non-parametric learning process. The framework unifies local exploration with global memory optimization through two novel mechanisms: Pairwise-Experience-Evolutionary Meta-Prompting (PE-EMP) and a Memory Optimization Agent. PE-EMP functions as a reflexive optimizer within the local search, utilizing pairwise feedback to dynamically synthesize adaptive criteria and evolve meta-prompts (system prompts) in real-time. Simultaneously, the Memory Optimization Agent manages a global repository as a dynamic policy prior, employing atomic operations to distill high-quality insights across problems. Extensive evaluations on complex reasoning benchmarks, including AIME25, ARC-AGI-2, and MathArena Apex, demonstrate that Empirical-MCTS significantly outperforms both stateless MCTS strategies and standalone experience-driven agents. These results underscore the critical necessity of coupling structured search with empirical accumulation for mastering complex, open-ended reasoning tasks.
MCTSr-Zero: Self-Reflective Psychological Counseling Dialogues Generation via Principles and Adaptive Exploration
May 29, 2025The integration of Monte Carlo Tree Search (MCTS) with Large Language Models (LLMs) has demonstrated significant success in structured, problem-oriented tasks. However, applying these methods to open-ended dialogues, such as those in psychological counseling, presents unique challenges. Unlike tasks with objective correctness, success in therapeutic conversations depends on subjective factors like empathetic engagement, ethical adherence, and alignment with human preferences, for which strict "correctness" criteria are ill-defined. Existing result-oriented MCTS approaches can therefore produce misaligned responses. To address this, we introduce MCTSr-Zero, an MCTS framework designed for open-ended, human-centric dialogues. Its core innovation is "domain alignment", which shifts the MCTS search objective from predefined end-states towards conversational trajectories that conform to target domain principles (e.g., empathy in counseling). Furthermore, MCTSr-Zero incorporates "Regeneration" and "Meta-Prompt Adaptation" mechanisms to substantially broaden exploration by allowing the MCTS to consider fundamentally different initial dialogue strategies. We evaluate MCTSr-Zero in psychological counseling by generating multi-turn dialogue data, which is used to fine-tune an LLM, PsyLLM. We also introduce PsyEval, a benchmark for assessing multi-turn psychological counseling dialogues. Experiments demonstrate that PsyLLM achieves state-of-the-art performance on PsyEval and other relevant metrics, validating MCTSr-Zero's effectiveness in generating high-quality, principle-aligned conversational data for human-centric domains and addressing the LLM challenge of consistently adhering to complex psychological standards.
MTIL: Encoding Full History with Mamba for Temporal Imitation Learning
May 18, 2025Standard imitation learning (IL) methods have achieved considerable success in robotics, yet often rely on the Markov assumption, limiting their applicability to tasks where historical context is crucial for disambiguating current observations. This limitation hinders performance in long-horizon sequential manipulation tasks where the correct action depends on past events not fully captured by the current state. To address this fundamental challenge, we introduce Mamba Temporal Imitation Learning (MTIL), a novel approach that leverages the recurrent state dynamics inherent in State Space Models (SSMs), specifically the Mamba architecture. MTIL encodes the entire trajectory history into a compressed hidden state, conditioning action predictions on this comprehensive temporal context alongside current multi-modal observations. Through extensive experiments on simulated benchmarks (ACT dataset tasks, Robomimic, LIBERO) and real-world sequential manipulation tasks specifically designed to probe temporal dependencies, MTIL significantly outperforms state-of-the-art methods like ACT and Diffusion Policy. Our findings affirm the necessity of full temporal context for robust sequential decision-making and validate MTIL as a powerful approach that transcends the inherent limitations of Markovian imitation learning
Existence Is Chaos: Enhancing 3D Human Motion Prediction with Uncertainty Consideration
Mar 21, 2024



Human motion prediction is consisting in forecasting future body poses from historically observed sequences. It is a longstanding challenge due to motion's complex dynamics and uncertainty. Existing methods focus on building up complicated neural networks to model the motion dynamics. The predicted results are required to be strictly similar to the training samples with L2 loss in current training pipeline. However, little attention has been paid to the uncertainty property which is crucial to the prediction task. We argue that the recorded motion in training data could be an observation of possible future, rather than a predetermined result. In addition, existing works calculate the predicted error on each future frame equally during training, while recent work indicated that different frames could play different roles. In this work, a novel computationally efficient encoder-decoder model with uncertainty consideration is proposed, which could learn proper characteristics for future frames by a dynamic function. Experimental results on benchmark datasets demonstrate that our uncertainty consideration approach has obvious advantages both in quantity and quality. Moreover, the proposed method could produce motion sequences with much better quality that avoids the intractable shaking artefacts. We believe our work could provide a novel perspective to consider the uncertainty quality for the general motion prediction task and encourage the studies in this field. The code will be available in https://github.com/Motionpre/Adaptive-Salient-Loss-SAGGB.
GelSplitter: Tactile Reconstruction from Near Infrared and Visible Images
Sep 15, 2023



The GelSight-like visual tactile (VT) sensor has gained popularity as a high-resolution tactile sensing technology for robots, capable of measuring touch geometry using a single RGB camera. However, the development of multi-modal perception for VT sensors remains a challenge, limited by the mono camera. In this paper, we propose the GelSplitter, a new framework approach the multi-modal VT sensor with synchronized multi-modal cameras and resemble a more human-like tactile receptor. Furthermore, we focus on 3D tactile reconstruction and implement a compact sensor structure that maintains a comparable size to state-of-the-art VT sensors, even with the addition of a prism and a near infrared (NIR) camera. We also design a photometric fusion stereo neural network (PFSNN), which estimates surface normals of objects and reconstructs touch geometry from both infrared and visible images. Our results demonstrate that the accuracy of RGB and NIR fusion is higher than that of RGB images alone. Additionally, our GelSplitter framework allows for a flexible configuration of different camera sensor combinations, such as RGB and thermal imaging.
An Empirical Study on Fertility Proposals Using Multi-Grained Topic Analysis Methods
Jul 22, 2023Fertility issues are closely related to population security, in 60 years China's population for the first time in a negative growth trend, the change of fertility policy is of great concern to the community. 2023 "two sessions" proposal "suggests that the country in the form of legislation, the birth of the registration of the cancellation of the marriage restriction" This topic was once a hot topic on the Internet, and "unbundling" the relationship between birth registration and marriage has become the focus of social debate. In this paper, we adopt co-occurrence semantic analysis, topic analysis and sentiment analysis to conduct multi-granularity semantic analysis of microblog comments. It is found that the discussion on the proposal of "removing marriage restrictions from birth registration" involves the individual, society and the state at three dimensions, and is detailed into social issues such as personal behaviour, social ethics and law, and national policy, with people's sentiment inclined to be negative in most of the topics. Based on this, eight proposals were made to provide a reference for governmental decision making and to form a reference method for researching public opinion on political issues.
Revisiting Automated Prompting: Are We Actually Doing Better?
Apr 07, 2023



Current literature demonstrates that Large Language Models (LLMs) are great few-shot learners, and prompting significantly increases their performance on a range of downstream tasks in a few-shot learning setting. An attempt to automate human-led prompting followed, with some progress achieved. In particular, subsequent work demonstrates automation can outperform fine-tuning in certain K-shot learning scenarios. In this paper, we revisit techniques for automated prompting on six different downstream tasks and a larger range of K-shot learning settings. We find that automated prompting does not consistently outperform simple manual prompts. Our work suggests that, in addition to fine-tuning, manual prompts should be used as a baseline in this line of research.
Shifting Perspective to See Difference: A Novel Multi-View Method for Skeleton based Action Recognition
Sep 07, 2022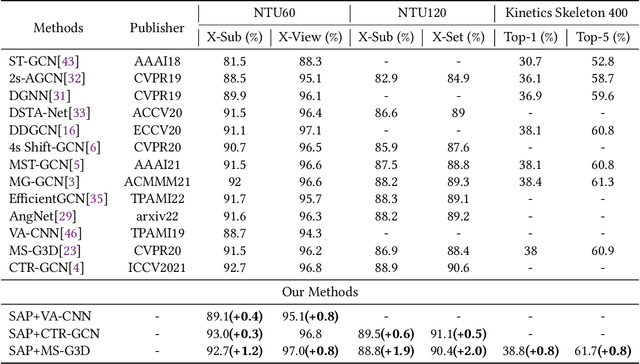
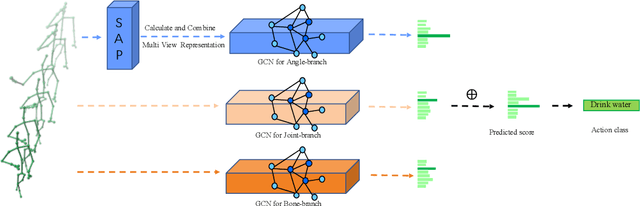
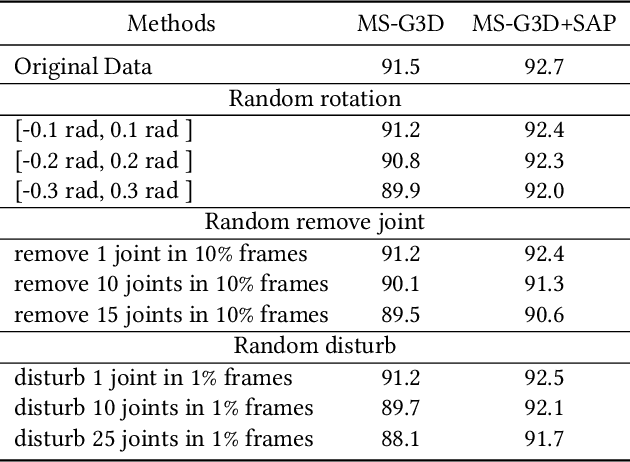
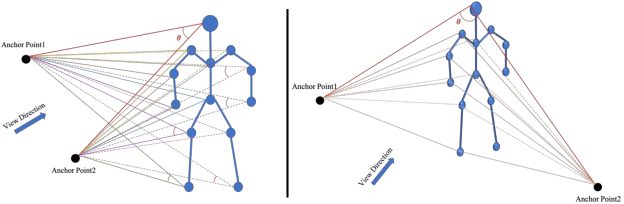
Skeleton-based human action recognition is a longstanding challenge due to its complex dynamics. Some fine-grain details of the dynamics play a vital role in classification. The existing work largely focuses on designing incremental neural networks with more complicated adjacent matrices to capture the details of joints relationships. However, they still have difficulties distinguishing actions that have broadly similar motion patterns but belong to different categories. Interestingly, we found that the subtle differences in motion patterns can be significantly amplified and become easy for audience to distinct through specified view directions, where this property haven't been fully explored before. Drastically different from previous work, we boost the performance by proposing a conceptually simple yet effective Multi-view strategy that recognizes actions from a collection of dynamic view features. Specifically, we design a novel Skeleton-Anchor Proposal (SAP) module which contains a Multi-head structure to learn a set of views. For feature learning of different views, we introduce a novel Angle Representation to transform the actions under different views and feed the transformations into the baseline model. Our module can work seamlessly with the existing action classification model. Incorporated with baseline models, our SAP module exhibits clear performance gains on many challenging benchmarks. Moreover, comprehensive experiments show that our model consistently beats down the state-of-the-art and remains effective and robust especially when dealing with corrupted data. Related code will be available on https://github.com/ideal-idea/SAP .