 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGazeVLA: Learning Human Intention for Robotic Manipulation
Apr 24, 2026Embodied foundation models have achieved significant breakthroughs in robotic manipulation, yet they still depend heavily on large-scale robot demonstrations. Although recent works have explored leveraging human data to alleviate this dependency, effectively extracting transferable knowledge remains a significant challenge due to the inherent embodiment gap between human and robot. We argue that the intention underlying human actions can serve as a powerful intermediate representation for bridging this gap. In this paper, we introduce a novel framework that explicitly learns and transfers human intention to facilitate robotic manipulation. Specifically, we model intention through gaze, as it naturally precedes physical actions and serves as an observable proxy for human intent. Our model is first pretrained on a large-scale egocentric human dataset to capture human intention and its synergy with action, followed by finetuning on a small set of robot and human data. During inference, the model adopts a Chain-of-Thought reasoning paradigm, sequentially predicting intention before executing the action. Extensive evaluations in simulation and real-world settings, across long-horizon and fine-grained tasks, and under few-shot and robustness benchmarks, show that our method consistently outperforms strong baselines, generalizes better, and achieves state-of-the-art performance.
Efficient and Scalable Granular-ball Graph Coarsening Method for Large-scale Graph Node Classification
Mar 31, 2026Graph Convolutional Network (GCN) is a model that can effectively handle graph data tasks and has been successfully applied. However, for large-scale graph datasets, GCN still faces the challenge of high computational overhead, especially when the number of convolutional layers in the graph is large. Currently, there are many advanced methods that use various sampling techniques or graph coarsening techniques to alleviate the inconvenience caused during training. However, among these methods, some ignore the multi-granularity information in the graph structure, and the time complexity of some coarsening methods is still relatively high. In response to these issues, based on our previous work, in this paper, we propose a new framework called Efficient and Scalable Granular-ball Graph Coarsening Method for Large-scale Graph Node Classification. Specifically, this method first uses a multi-granularity granular-ball graph coarsening algorithm to coarsen the original graph to obtain many subgraphs. The time complexity of this stage is linear and much lower than that of the exiting graph coarsening methods. Then, subgraphs composed of these granular-balls are randomly sampled to form minibatches for training GCN. Our algorithm can adaptively and significantly reduce the scale of the original graph, thereby enhancing the training efficiency and scalability of GCN. Ultimately, the experimental results of node classification on multiple datasets demonstrate that the method proposed in this paper exhibits superior performance. The code is available at https://anonymous.4open.science/r/1-141D/.
Unleashing High-Quality Image Generation in Diffusion Sampling Using Second-Order Levenberg-Marquardt-Langevin
May 30, 2025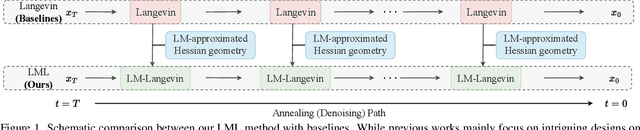


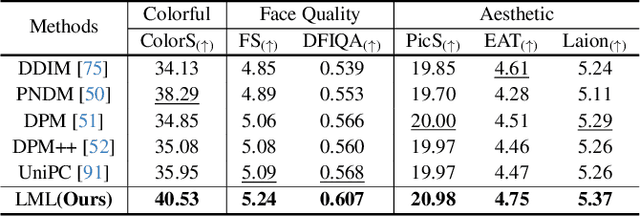
The diffusion models (DMs) have demonstrated the remarkable capability of generating images via learning the noised score function of data distribution. Current DM sampling techniques typically rely on first-order Langevin dynamics at each noise level, with efforts concentrated on refining inter-level denoising strategies. While leveraging additional second-order Hessian geometry to enhance the sampling quality of Langevin is a common practice in Markov chain Monte Carlo (MCMC), the naive attempts to utilize Hessian geometry in high-dimensional DMs lead to quadratic-complexity computational costs, rendering them non-scalable. In this work, we introduce a novel Levenberg-Marquardt-Langevin (LML) method that approximates the diffusion Hessian geometry in a training-free manner, drawing inspiration from the celebrated Levenberg-Marquardt optimization algorithm. Our approach introduces two key innovations: (1) A low-rank approximation of the diffusion Hessian, leveraging the DMs' inherent structure and circumventing explicit quadratic-complexity computations; (2) A damping mechanism to stabilize the approximated Hessian. This LML approximated Hessian geometry enables the diffusion sampling to execute more accurate steps and improve the image generation quality. We further conduct a theoretical analysis to substantiate the approximation error bound of low-rank approximation and the convergence property of the damping mechanism. Extensive experiments across multiple pretrained DMs validate that the LML method significantly improves image generation quality, with negligible computational overhead.
Efficiently Access Diffusion Fisher: Within the Outer Product Span Space
May 29, 2025Recent Diffusion models (DMs) advancements have explored incorporating the second-order diffusion Fisher information (DF), defined as the negative Hessian of log density, into various downstream tasks and theoretical analysis. However, current practices typically approximate the diffusion Fisher by applying auto-differentiation to the learned score network. This black-box method, though straightforward, lacks any accuracy guarantee and is time-consuming. In this paper, we show that the diffusion Fisher actually resides within a space spanned by the outer products of score and initial data. Based on the outer-product structure, we develop two efficient approximation algorithms to access the trace and matrix-vector multiplication of DF, respectively. These algorithms bypass the auto-differentiation operations with time-efficient vector-product calculations. Furthermore, we establish the approximation error bounds for the proposed algorithms. Experiments in likelihood evaluation and adjoint optimization demonstrate the superior accuracy and reduced computational cost of our proposed algorithms. Additionally, based on the novel outer-product formulation of DF, we design the first numerical verification experiment for the optimal transport property of the general PF-ODE deduced map.
Prediction of Depression Severity Based on the Prosodic and Semantic Features with Bidirectional LSTM and Time Distributed CNN
Feb 25, 2022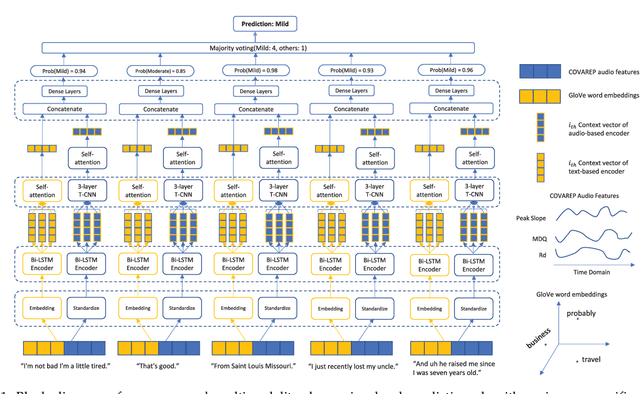

Depression is increasingly impacting individuals both physically and psychologically worldwide. It has become a global major public health problem and attracts attention from various research fields. Traditionally, the diagnosis of depression is formulated through semi-structured interviews and supplementary questionnaires, which makes the diagnosis heavily relying on physicians experience and is subject to bias. Mental health monitoring and cloud-based remote diagnosis can be implemented through an automated depression diagnosis system. In this article, we propose an attention-based multimodality speech and text representation for depression prediction. Our model is trained to estimate the depression severity of participants using the Distress Analysis Interview Corpus-Wizard of Oz (DAIC-WOZ) dataset. For the audio modality, we use the collaborative voice analysis repository (COVAREP) features provided by the dataset and employ a Bidirectional Long Short-Term Memory Network (Bi-LSTM) followed by a Time-distributed Convolutional Neural Network (T-CNN). For the text modality, we use global vectors for word representation (GloVe) to perform word embeddings and the embeddings are fed into the Bi-LSTM network. Results show that both audio and text models perform well on the depression severity estimation task, with best sequence level F1 score of 0.9870 and patient-level F1 score of 0.9074 for the audio model over five classes (healthy, mild, moderate, moderately severe, and severe), as well as sequence level F1 score of 0.9709 and patient-level F1 score of 0.9245 for the text model over five classes. Results are similar for the multimodality fused model, with the highest F1 score of 0.9580 on the patient-level depression detection task over five classes. Experiments show statistically significant improvements over previous works.
SiamReID: Confuser Aware Siamese Tracker with Re-identification Feature
Apr 15, 2021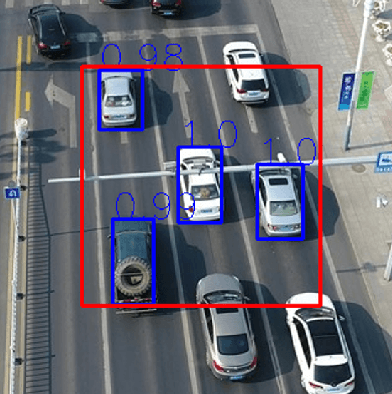
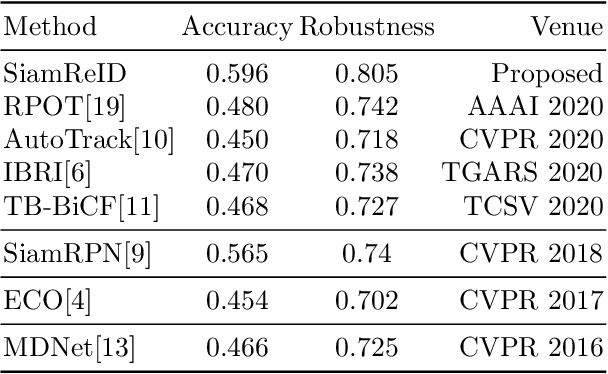
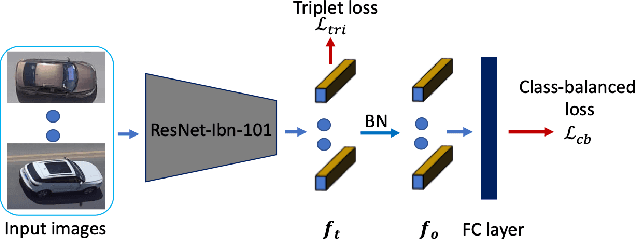
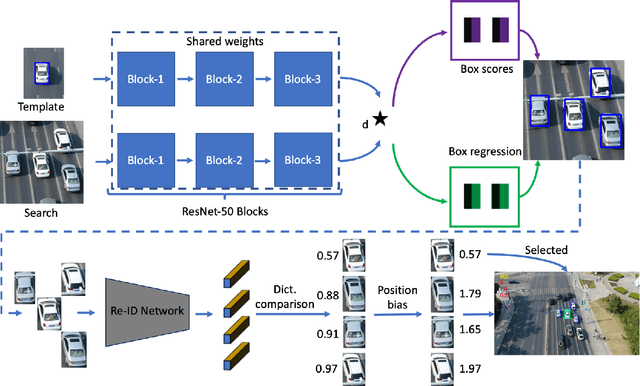
Siamese deep-network trackers have received significant attention in recent years due to their real-time speed and state-of-the-art performance. However, Siamese trackers suffer from similar looking confusers, that are prevalent in aerial imagery and create challenging conditions due to prolonged occlusions where the tracker object re-appears under different pose and illumination. Our work proposes SiamReID, a novel re-identification framework for Siamese trackers, that incorporates confuser rejection during prolonged occlusions and is well-suited for aerial tracking. The re-identification feature is trained using both triplet loss and a class balanced loss. Our approach achieves state-of-the-art performance in the UAVDT single object tracking benchmark.