 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePoint-to-Voxel Knowledge Distillation for LiDAR Semantic Segmentation
Jun 05, 2022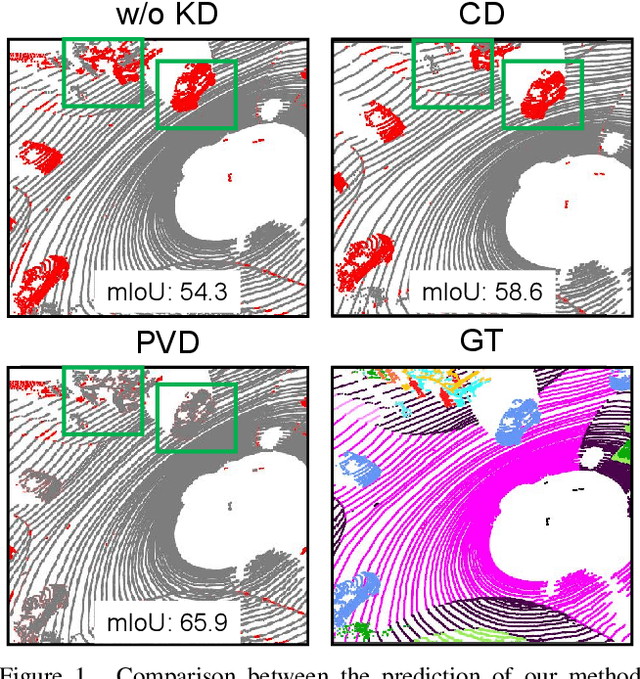
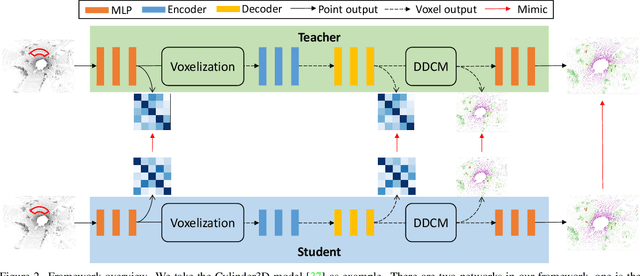
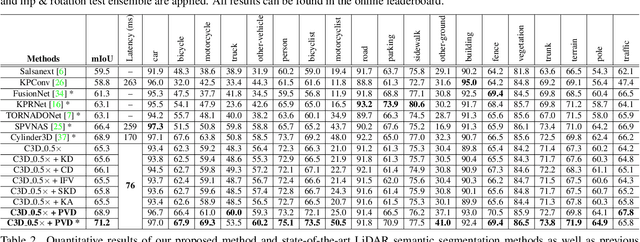
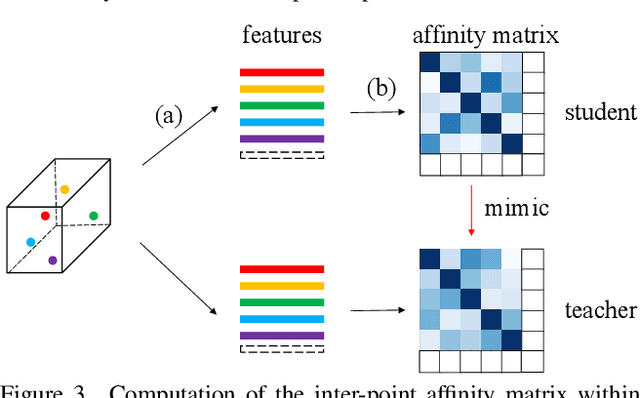
This article addresses the problem of distilling knowledge from a large teacher model to a slim student network for LiDAR semantic segmentation. Directly employing previous distillation approaches yields inferior results due to the intrinsic challenges of point cloud, i.e., sparsity, randomness and varying density. To tackle the aforementioned problems, we propose the Point-to-Voxel Knowledge Distillation (PVD), which transfers the hidden knowledge from both point level and voxel level. Specifically, we first leverage both the pointwise and voxelwise output distillation to complement the sparse supervision signals. Then, to better exploit the structural information, we divide the whole point cloud into several supervoxels and design a difficulty-aware sampling strategy to more frequently sample supervoxels containing less-frequent classes and faraway objects. On these supervoxels, we propose inter-point and inter-voxel affinity distillation, where the similarity information between points and voxels can help the student model better capture the structural information of the surrounding environment. We conduct extensive experiments on two popular LiDAR segmentation benchmarks, i.e., nuScenes and SemanticKITTI. On both benchmarks, our PVD consistently outperforms previous distillation approaches by a large margin on three representative backbones, i.e., Cylinder3D, SPVNAS and MinkowskiNet. Notably, on the challenging nuScenes and SemanticKITTI datasets, our method can achieve roughly 75% MACs reduction and 2x speedup on the competitive Cylinder3D model and rank 1st on the SemanticKITTI leaderboard among all published algorithms. Our code is available at https://github.com/cardwing/Codes-for-PVKD.
Text2Human: Text-Driven Controllable Human Image Generation
May 31, 2022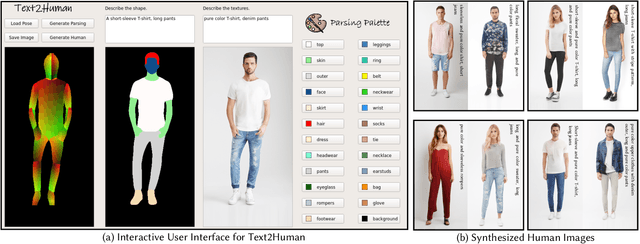
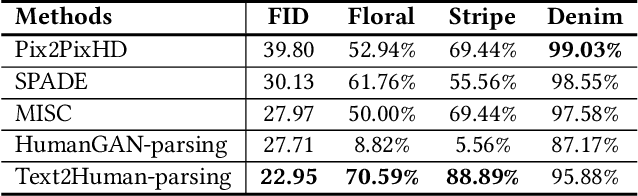
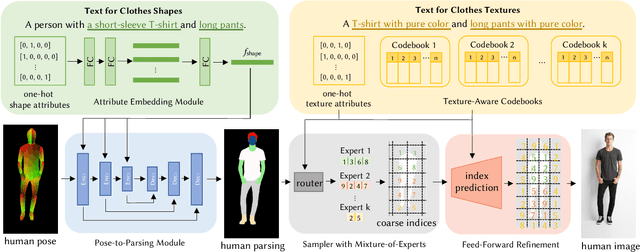
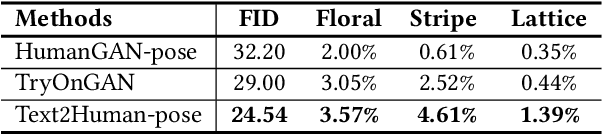
Generating high-quality and diverse human images is an important yet challenging task in vision and graphics. However, existing generative models often fall short under the high diversity of clothing shapes and textures. Furthermore, the generation process is even desired to be intuitively controllable for layman users. In this work, we present a text-driven controllable framework, Text2Human, for a high-quality and diverse human generation. We synthesize full-body human images starting from a given human pose with two dedicated steps. 1) With some texts describing the shapes of clothes, the given human pose is first translated to a human parsing map. 2) The final human image is then generated by providing the system with more attributes about the textures of clothes. Specifically, to model the diversity of clothing textures, we build a hierarchical texture-aware codebook that stores multi-scale neural representations for each type of texture. The codebook at the coarse level includes the structural representations of textures, while the codebook at the fine level focuses on the details of textures. To make use of the learned hierarchical codebook to synthesize desired images, a diffusion-based transformer sampler with mixture of experts is firstly employed to sample indices from the coarsest level of the codebook, which then is used to predict the indices of the codebook at finer levels. The predicted indices at different levels are translated to human images by the decoder learned accompanied with hierarchical codebooks. The use of mixture-of-experts allows for the generated image conditioned on the fine-grained text input. The prediction for finer level indices refines the quality of clothing textures. Extensive quantitative and qualitative evaluations demonstrate that our proposed framework can generate more diverse and realistic human images compared to state-of-the-art methods.
Delving into High-Quality Synthetic Face Occlusion Segmentation Datasets
May 12, 2022


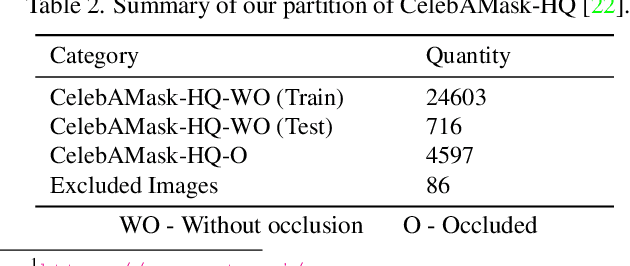
This paper performs comprehensive analysis on datasets for occlusion-aware face segmentation, a task that is crucial for many downstream applications. The collection and annotation of such datasets are time-consuming and labor-intensive. Although some efforts have been made in synthetic data generation, the naturalistic aspect of data remains less explored. In our study, we propose two occlusion generation techniques, Naturalistic Occlusion Generation (NatOcc), for producing high-quality naturalistic synthetic occluded faces; and Random Occlusion Generation (RandOcc), a more general synthetic occluded data generation method. We empirically show the effectiveness and robustness of both methods, even for unseen occlusions. To facilitate model evaluation, we present two high-resolution real-world occluded face datasets with fine-grained annotations, RealOcc and RealOcc-Wild, featuring both careful alignment preprocessing and an in-the-wild setting for robustness test. We further conduct a comprehensive analysis on a newly introduced segmentation benchmark, offering insights for future exploration.
HuMMan: Multi-Modal 4D Human Dataset for Versatile Sensing and Modeling
Apr 28, 2022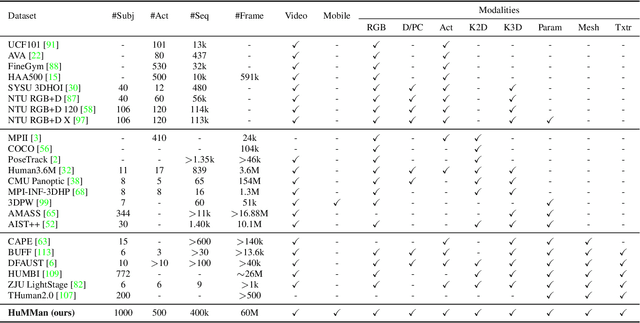
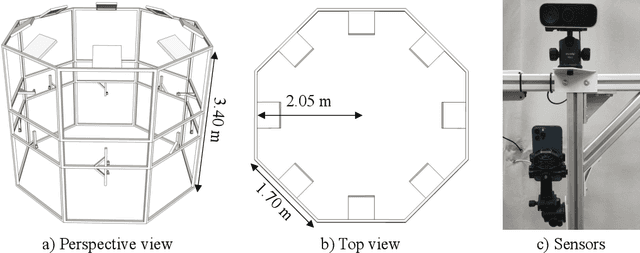

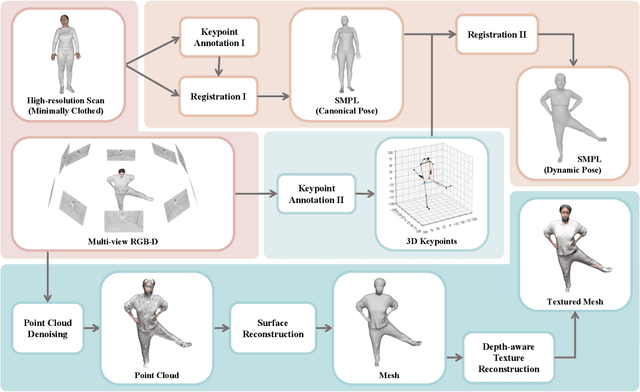
4D human sensing and modeling are fundamental tasks in vision and graphics with numerous applications. With the advances of new sensors and algorithms, there is an increasing demand for more versatile datasets. In this work, we contribute HuMMan, a large-scale multi-modal 4D human dataset with 1000 human subjects, 400k sequences and 60M frames. HuMMan has several appealing properties: 1) multi-modal data and annotations including color images, point clouds, keypoints, SMPL parameters, and textured meshes; 2) popular mobile device is included in the sensor suite; 3) a set of 500 actions, designed to cover fundamental movements; 4) multiple tasks such as action recognition, pose estimation, parametric human recovery, and textured mesh reconstruction are supported and evaluated. Extensive experiments on HuMMan voice the need for further study on challenges such as fine-grained action recognition, dynamic human mesh reconstruction, point cloud-based parametric human recovery, and cross-device domain gaps.
StyleGAN-Human: A Data-Centric Odyssey of Human Generation
Apr 25, 2022

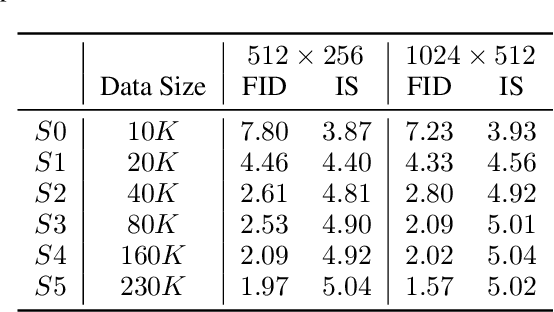
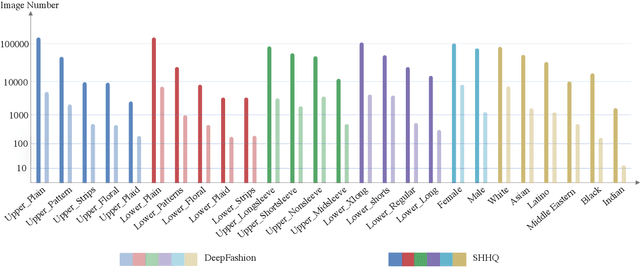
Unconditional human image generation is an important task in vision and graphics, which enables various applications in the creative industry. Existing studies in this field mainly focus on "network engineering" such as designing new components and objective functions. This work takes a data-centric perspective and investigates multiple critical aspects in "data engineering", which we believe would complement the current practice. To facilitate a comprehensive study, we collect and annotate a large-scale human image dataset with over 230K samples capturing diverse poses and textures. Equipped with this large dataset, we rigorously investigate three essential factors in data engineering for StyleGAN-based human generation, namely data size, data distribution, and data alignment. Extensive experiments reveal several valuable observations w.r.t. these aspects: 1) Large-scale data, more than 40K images, are needed to train a high-fidelity unconditional human generation model with vanilla StyleGAN. 2) A balanced training set helps improve the generation quality with rare face poses compared to the long-tailed counterpart, whereas simply balancing the clothing texture distribution does not effectively bring an improvement. 3) Human GAN models with body centers for alignment outperform models trained using face centers or pelvis points as alignment anchors. In addition, a model zoo and human editing applications are demonstrated to facilitate future research in the community.
On the Generalization of BasicVSR++ to Video Deblurring and Denoising
Apr 11, 2022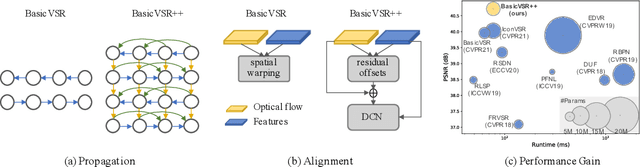
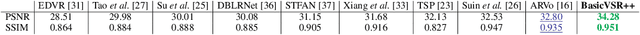


The exploitation of long-term information has been a long-standing problem in video restoration. The recent BasicVSR and BasicVSR++ have shown remarkable performance in video super-resolution through long-term propagation and effective alignment. Their success has led to a question of whether they can be transferred to different video restoration tasks. In this work, we extend BasicVSR++ to a generic framework for video restoration tasks. In tasks where inputs and outputs possess identical spatial size, the input resolution is reduced by strided convolutions to maintain efficiency. With only minimal changes from BasicVSR++, the proposed framework achieves compelling performance with great efficiency in various video restoration tasks including video deblurring and denoising. Notably, BasicVSR++ achieves comparable performance to Transformer-based approaches with up to 79% of parameter reduction and 44x speedup. The promising results demonstrate the importance of propagation and alignment in video restoration tasks beyond just video super-resolution. Code and models are available at https://github.com/ckkelvinchan/BasicVSR_PlusPlus.
Video K-Net: A Simple, Strong, and Unified Baseline for Video Segmentation
Apr 10, 2022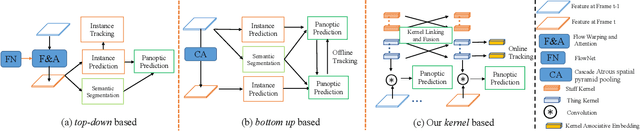

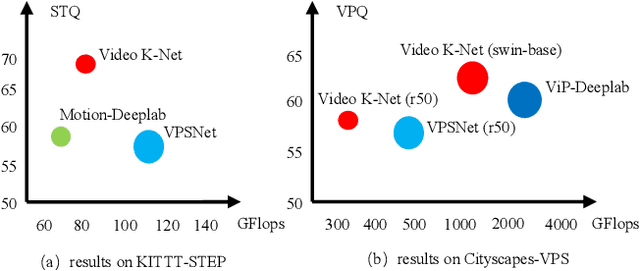
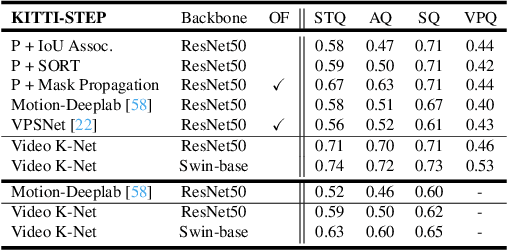
This paper presents Video K-Net, a simple, strong, and unified framework for fully end-to-end video panoptic segmentation. The method is built upon K-Net, a method that unifies image segmentation via a group of learnable kernels. We observe that these learnable kernels from K-Net, which encode object appearances and contexts, can naturally associate identical instances across video frames. Motivated by this observation, Video K-Net learns to simultaneously segment and track "things" and "stuff" in a video with simple kernel-based appearance modeling and cross-temporal kernel interaction. Despite the simplicity, it achieves state-of-the-art video panoptic segmentation results on Citscapes-VPS and KITTI-STEP without bells and whistles. In particular on KITTI-STEP, the simple method can boost almost 12\% relative improvements over previous methods. We also validate its generalization on video semantic segmentation, where we boost various baselines by 2\% on the VSPW dataset. Moreover, we extend K-Net into clip-level video framework for video instance segmentation where we obtain 40.5\% for ResNet50 backbone and 51.5\% mAP for Swin-base on YouTube-2019 validation set. We hope this simple yet effective method can serve as a new flexible baseline in video segmentation. Both code and models are released at https://github.com/lxtGH/Video-K-Net
Unsupervised Image-to-Image Translation with Generative Prior
Apr 07, 2022

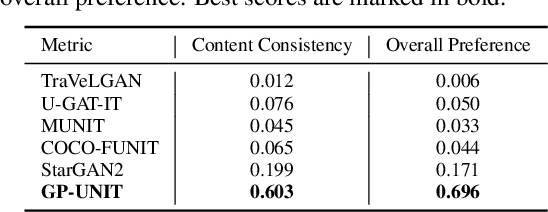

Unsupervised image-to-image translation aims to learn the translation between two visual domains without paired data. Despite the recent progress in image translation models, it remains challenging to build mappings between complex domains with drastic visual discrepancies. In this work, we present a novel framework, Generative Prior-guided UNsupervised Image-to-image Translation (GP-UNIT), to improve the overall quality and applicability of the translation algorithm. Our key insight is to leverage the generative prior from pre-trained class-conditional GANs (e.g., BigGAN) to learn rich content correspondences across various domains. We propose a novel coarse-to-fine scheme: we first distill the generative prior to capture a robust coarse-level content representation that can link objects at an abstract semantic level, based on which fine-level content features are adaptively learned for more accurate multi-level content correspondences. Extensive experiments demonstrate the superiority of our versatile framework over state-of-the-art methods in robust, high-quality and diversified translations, even for challenging and distant domains.
TransEditor: Transformer-Based Dual-Space GAN for Highly Controllable Facial Editing
Mar 31, 2022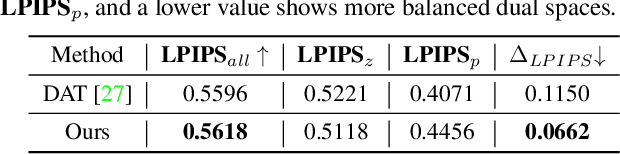
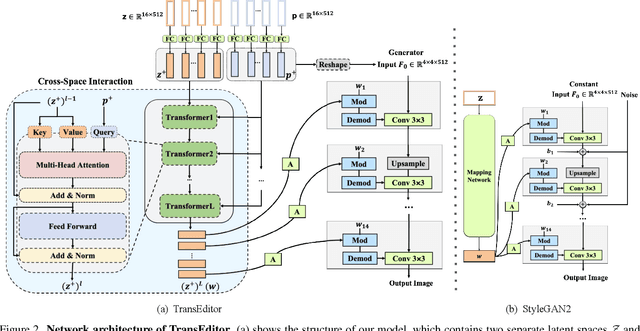

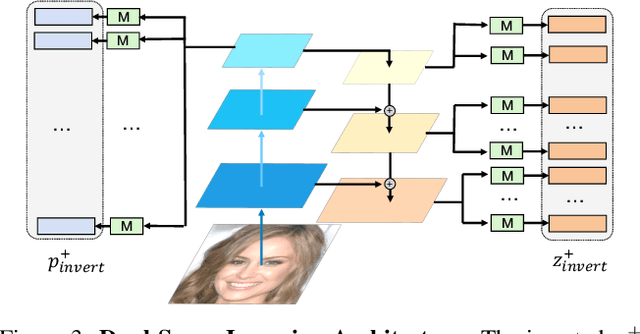
Recent advances like StyleGAN have promoted the growth of controllable facial editing. To address its core challenge of attribute decoupling in a single latent space, attempts have been made to adopt dual-space GAN for better disentanglement of style and content representations. Nonetheless, these methods are still incompetent to obtain plausible editing results with high controllability, especially for complicated attributes. In this study, we highlight the importance of interaction in a dual-space GAN for more controllable editing. We propose TransEditor, a novel Transformer-based framework to enhance such interaction. Besides, we develop a new dual-space editing and inversion strategy to provide additional editing flexibility. Extensive experiments demonstrate the superiority of the proposed framework in image quality and editing capability, suggesting the effectiveness of TransEditor for highly controllable facial editing.
Bailando: 3D Dance Generation by Actor-Critic GPT with Choreographic Memory
Mar 25, 2022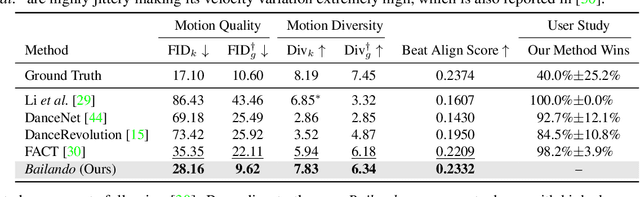
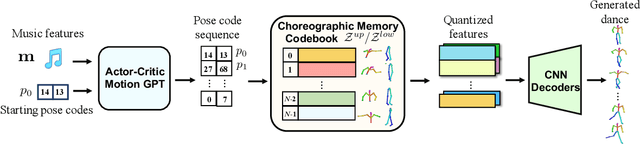
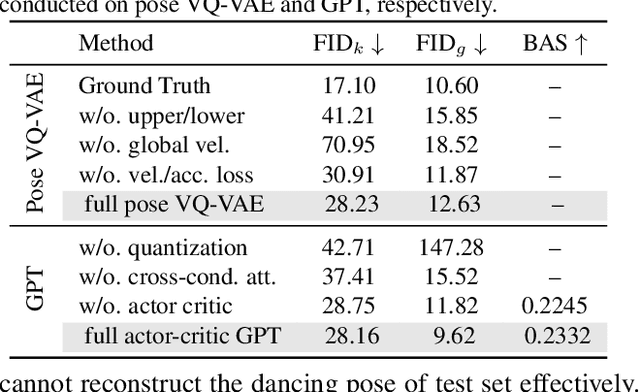
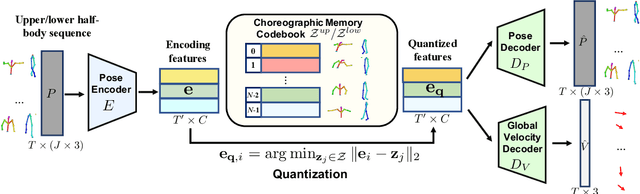
Driving 3D characters to dance following a piece of music is highly challenging due to the spatial constraints applied to poses by choreography norms. In addition, the generated dance sequence also needs to maintain temporal coherency with different music genres. To tackle these challenges, we propose a novel music-to-dance framework, Bailando, with two powerful components: 1) a choreographic memory that learns to summarize meaningful dancing units from 3D pose sequence to a quantized codebook, 2) an actor-critic Generative Pre-trained Transformer (GPT) that composes these units to a fluent dance coherent to the music. With the learned choreographic memory, dance generation is realized on the quantized units that meet high choreography standards, such that the generated dancing sequences are confined within the spatial constraints. To achieve synchronized alignment between diverse motion tempos and music beats, we introduce an actor-critic-based reinforcement learning scheme to the GPT with a newly-designed beat-align reward function. Extensive experiments on the standard benchmark demonstrate that our proposed framework achieves state-of-the-art performance both qualitatively and quantitatively. Notably, the learned choreographic memory is shown to discover human-interpretable dancing-style poses in an unsupervised manner.