 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInfiniteDance: Scalable 3D Dance Generation Towards in-the-wild Generalization
Mar 10, 2026Although existing 3D dance generation methods perform well in controlled scenarios, they often struggle to generalize in the wild. When conditioned on unseen music, existing methods often produce unstructured or physically implausible dance, largely due to limited music-to-dance data and restricted model capacity. This work aims to push the frontier of generalizable 3D dance generation by scaling up both data and model design. (1) On the data side, we develop a fully automated pipeline that reconstructs high-fidelity 3D dance motions from monocular videos. To eliminate the physical artifacts prevalent in existing reconstruction methods, we introduce a Foot Restoration Diffusion Model (FRDM) guided by foot-contact and geometric constraints that enforce physical plausibility while preserving kinematic smoothness and expressiveness, resulting in a diverse, high-quality multimodal 3D dance dataset totaling 100.69 hours. (2) On model design, we propose Choreographic LLaMA (ChoreoLLaMA), a scalable LLaMA-based architecture. To enhance robustness under unfamiliar music conditions, we integrate a retrieval-augmented generation (RAG) module that injects reference dance as a prompt. Additionally, we design a slow/fast-cadence Mixture-of-Experts (MoE) module that enables ChoreoLLaMA to smoothly adapt motion rhythms across varying music tempos. Extensive experiments across diverse dance genres show that our approach surpasses existing methods in both qualitative and quantitative evaluations, marking a step toward scalable, real-world 3D dance generation. Code, models, and data will be released.
Half-Physics: Enabling Kinematic 3D Human Model with Physical Interactions
Jul 31, 2025While current general-purpose 3D human models (e.g., SMPL-X) efficiently represent accurate human shape and pose, they lacks the ability to physically interact with the environment due to the kinematic nature. As a result, kinematic-based interaction models often suffer from issues such as interpenetration and unrealistic object dynamics. To address this limitation, we introduce a novel approach that embeds SMPL-X into a tangible entity capable of dynamic physical interactions with its surroundings. Specifically, we propose a "half-physics" mechanism that transforms 3D kinematic motion into a physics simulation. Our approach maintains kinematic control over inherent SMPL-X poses while ensuring physically plausible interactions with scenes and objects, effectively eliminating penetration and unrealistic object dynamics. Unlike reinforcement learning-based methods, which demand extensive and complex training, our half-physics method is learning-free and generalizes to any body shape and motion; meanwhile, it operates in real time. Moreover, it preserves the fidelity of the original kinematic motion while seamlessly integrating physical interactions
Duolando: Follower GPT with Off-Policy Reinforcement Learning for Dance Accompaniment
Mar 27, 2024



We introduce a novel task within the field of 3D dance generation, termed dance accompaniment, which necessitates the generation of responsive movements from a dance partner, the "follower", synchronized with the lead dancer's movements and the underlying musical rhythm. Unlike existing solo or group dance generation tasks, a duet dance scenario entails a heightened degree of interaction between the two participants, requiring delicate coordination in both pose and position. To support this task, we first build a large-scale and diverse duet interactive dance dataset, DD100, by recording about 117 minutes of professional dancers' performances. To address the challenges inherent in this task, we propose a GPT-based model, Duolando, which autoregressively predicts the subsequent tokenized motion conditioned on the coordinated information of the music, the leader's and the follower's movements. To further enhance the GPT's capabilities of generating stable results on unseen conditions (music and leader motions), we devise an off-policy reinforcement learning strategy that allows the model to explore viable trajectories from out-of-distribution samplings, guided by human-defined rewards. Based on the collected dataset and proposed method, we establish a benchmark with several carefully designed metrics.
Deep Geometrized Cartoon Line Inbetweening
Sep 28, 2023



We aim to address a significant but understudied problem in the anime industry, namely the inbetweening of cartoon line drawings. Inbetweening involves generating intermediate frames between two black-and-white line drawings and is a time-consuming and expensive process that can benefit from automation. However, existing frame interpolation methods that rely on matching and warping whole raster images are unsuitable for line inbetweening and often produce blurring artifacts that damage the intricate line structures. To preserve the precision and detail of the line drawings, we propose a new approach, AnimeInbet, which geometrizes raster line drawings into graphs of endpoints and reframes the inbetweening task as a graph fusion problem with vertex repositioning. Our method can effectively capture the sparsity and unique structure of line drawings while preserving the details during inbetweening. This is made possible via our novel modules, i.e., vertex geometric embedding, a vertex correspondence Transformer, an effective mechanism for vertex repositioning and a visibility predictor. To train our method, we introduce MixamoLine240, a new dataset of line drawings with ground truth vectorization and matching labels. Our experiments demonstrate that AnimeInbet synthesizes high-quality, clean, and complete intermediate line drawings, outperforming existing methods quantitatively and qualitatively, especially in cases with large motions. Data and code are available at https://github.com/lisiyao21/AnimeInbet.
AnimeRun: 2D Animation Visual Correspondence from Open Source 3D Movies
Nov 10, 2022



Existing correspondence datasets for two-dimensional (2D) cartoon suffer from simple frame composition and monotonic movements, making them insufficient to simulate real animations. In this work, we present a new 2D animation visual correspondence dataset, AnimeRun, by converting open source three-dimensional (3D) movies to full scenes in 2D style, including simultaneous moving background and interactions of multiple subjects. Our analyses show that the proposed dataset not only resembles real anime more in image composition, but also possesses richer and more complex motion patterns compared to existing datasets. With this dataset, we establish a comprehensive benchmark by evaluating several existing optical flow and segment matching methods, and analyze shortcomings of these methods on animation data. Data, code and other supplementary materials are available at https://lisiyao21.github.io/projects/AnimeRun.
Bailando: 3D Dance Generation by Actor-Critic GPT with Choreographic Memory
Mar 25, 2022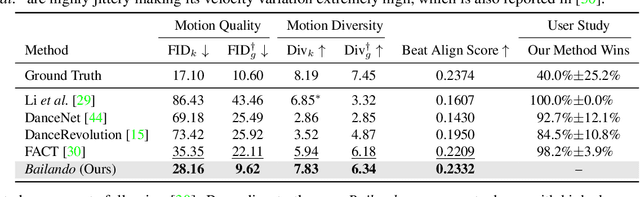
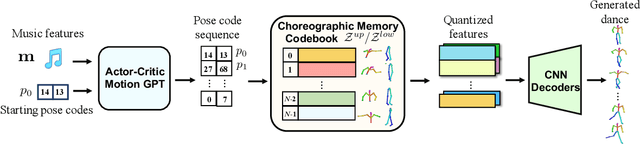
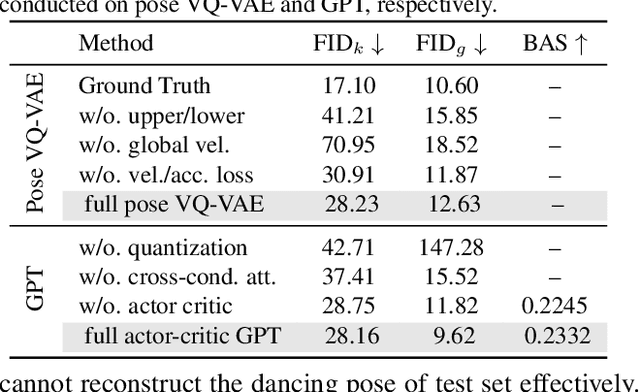
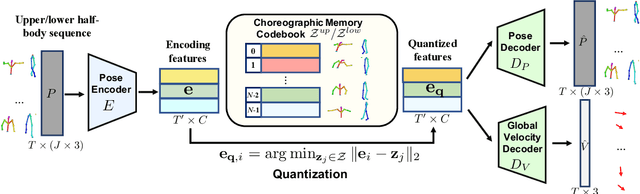
Driving 3D characters to dance following a piece of music is highly challenging due to the spatial constraints applied to poses by choreography norms. In addition, the generated dance sequence also needs to maintain temporal coherency with different music genres. To tackle these challenges, we propose a novel music-to-dance framework, Bailando, with two powerful components: 1) a choreographic memory that learns to summarize meaningful dancing units from 3D pose sequence to a quantized codebook, 2) an actor-critic Generative Pre-trained Transformer (GPT) that composes these units to a fluent dance coherent to the music. With the learned choreographic memory, dance generation is realized on the quantized units that meet high choreography standards, such that the generated dancing sequences are confined within the spatial constraints. To achieve synchronized alignment between diverse motion tempos and music beats, we introduce an actor-critic-based reinforcement learning scheme to the GPT with a newly-designed beat-align reward function. Extensive experiments on the standard benchmark demonstrate that our proposed framework achieves state-of-the-art performance both qualitatively and quantitatively. Notably, the learned choreographic memory is shown to discover human-interpretable dancing-style poses in an unsupervised manner.
Deep Animation Video Interpolation in the Wild
Apr 06, 2021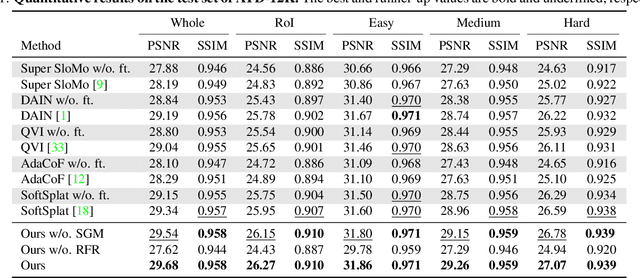

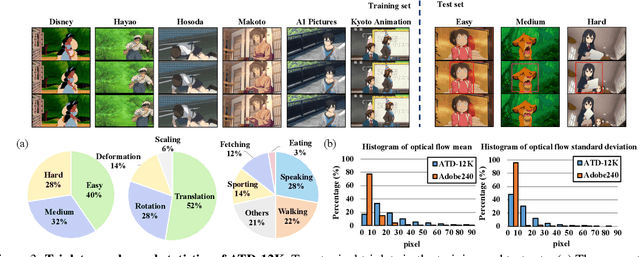
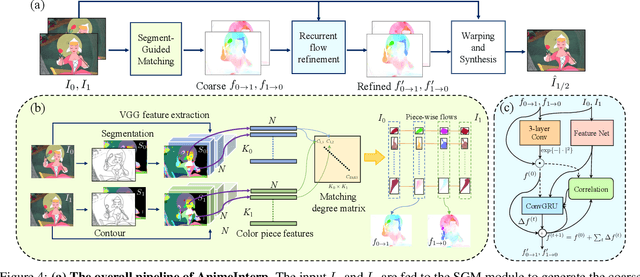
In the animation industry, cartoon videos are usually produced at low frame rate since hand drawing of such frames is costly and time-consuming. Therefore, it is desirable to develop computational models that can automatically interpolate the in-between animation frames. However, existing video interpolation methods fail to produce satisfying results on animation data. Compared to natural videos, animation videos possess two unique characteristics that make frame interpolation difficult: 1) cartoons comprise lines and smooth color pieces. The smooth areas lack textures and make it difficult to estimate accurate motions on animation videos. 2) cartoons express stories via exaggeration. Some of the motions are non-linear and extremely large. In this work, we formally define and study the animation video interpolation problem for the first time. To address the aforementioned challenges, we propose an effective framework, AnimeInterp, with two dedicated modules in a coarse-to-fine manner. Specifically, 1) Segment-Guided Matching resolves the "lack of textures" challenge by exploiting global matching among color pieces that are piece-wise coherent. 2) Recurrent Flow Refinement resolves the "non-linear and extremely large motion" challenge by recurrent predictions using a transformer-like architecture. To facilitate comprehensive training and evaluations, we build a large-scale animation triplet dataset, ATD-12K, which comprises 12,000 triplets with rich annotations. Extensive experiments demonstrate that our approach outperforms existing state-of-the-art interpolation methods for animation videos. Notably, AnimeInterp shows favorable perceptual quality and robustness for animation scenarios in the wild. The proposed dataset and code are available at https://github.com/lisiyao21/AnimeInterp/.
Enhanced Quadratic Video Interpolation
Sep 10, 2020
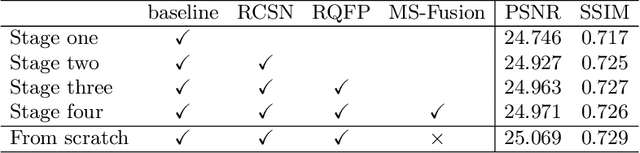
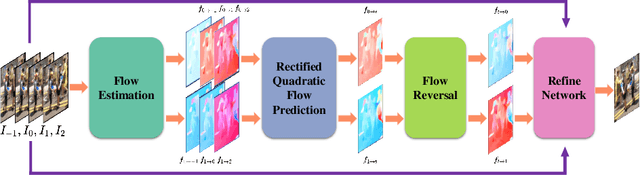
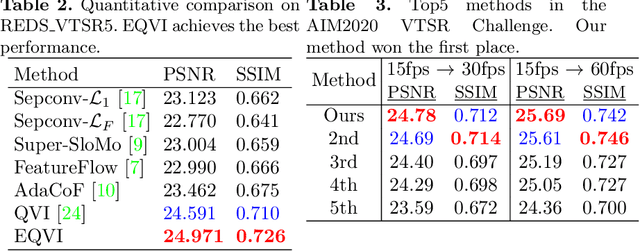
With the prosperity of digital video industry, video frame interpolation has arisen continuous attention in computer vision community and become a new upsurge in industry. Many learning-based methods have been proposed and achieved progressive results. Among them, a recent algorithm named quadratic video interpolation (QVI) achieves appealing performance. It exploits higher-order motion information (e.g. acceleration) and successfully models the estimation of interpolated flow. However, its produced intermediate frames still contain some unsatisfactory ghosting, artifacts and inaccurate motion, especially when large and complex motion occurs. In this work, we further improve the performance of QVI from three facets and propose an enhanced quadratic video interpolation (EQVI) model. In particular, we adopt a rectified quadratic flow prediction (RQFP) formulation with least squares method to estimate the motion more accurately. Complementary with image pixel-level blending, we introduce a residual contextual synthesis network (RCSN) to employ contextual information in high-dimensional feature space, which could help the model handle more complicated scenes and motion patterns. Moreover, to further boost the performance, we devise a novel multi-scale fusion network (MS-Fusion) which can be regarded as a learnable augmentation process. The proposed EQVI model won the first place in the AIM2020 Video Temporal Super-Resolution Challenge.
Quadratic video interpolation
Nov 02, 2019
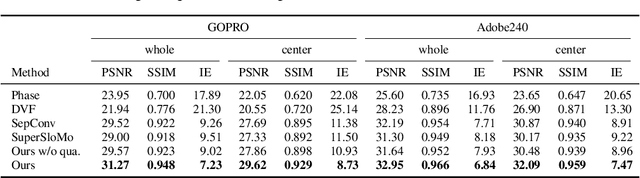
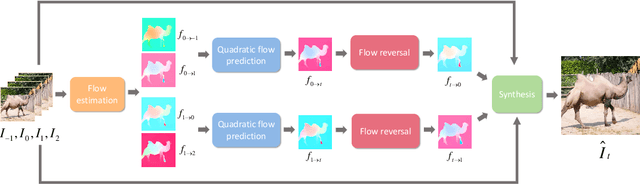

Video interpolation is an important problem in computer vision, which helps overcome the temporal limitation of camera sensors. Existing video interpolation methods usually assume uniform motion between consecutive frames and use linear models for interpolation, which cannot well approximate the complex motion in the real world. To address these issues, we propose a quadratic video interpolation method which exploits the acceleration information in videos. This method allows prediction with curvilinear trajectory and variable velocity, and generates more accurate interpolation results. For high-quality frame synthesis, we develop a flow reversal layer to estimate flow fields starting from the unknown target frame to the source frame. In addition, we present techniques for flow refinement. Extensive experiments demonstrate that our approach performs favorably against the existing linear models on a wide variety of video datasets.