 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGraphOmni: A Comprehensive and Extendable Benchmark Framework for Large Language Models on Graph-theoretic Tasks
Apr 17, 2025



In this paper, we presented GraphOmni, a comprehensive benchmark framework for systematically evaluating the graph reasoning capabilities of LLMs. By analyzing critical dimensions, including graph types, serialization formats, and prompt schemes, we provided extensive insights into the strengths and limitations of current LLMs. Our empirical findings emphasize that no single serialization or prompting strategy consistently outperforms others. Motivated by these insights, we propose a reinforcement learning-based approach that dynamically selects the best serialization-prompt pairings, resulting in significant accuracy improvements. GraphOmni's modular and extensible design establishes a robust foundation for future research, facilitating advancements toward general-purpose graph reasoning models.
EduPlanner: LLM-Based Multi-Agent Systems for Customized and Intelligent Instructional Design
Apr 07, 2025Large Language Models (LLMs) have significantly advanced smart education in the Artificial General Intelligence (AGI) era. A promising application lies in the automatic generalization of instructional design for curriculum and learning activities, focusing on two key aspects: (1) Customized Generation: generating niche-targeted teaching content based on students' varying learning abilities and states, and (2) Intelligent Optimization: iteratively optimizing content based on feedback from learning effectiveness or test scores. Currently, a single large LLM cannot effectively manage the entire process, posing a challenge for designing intelligent teaching plans. To address these issues, we developed EduPlanner, an LLM-based multi-agent system comprising an evaluator agent, an optimizer agent, and a question analyst, working in adversarial collaboration to generate customized and intelligent instructional design for curriculum and learning activities. Taking mathematics lessons as our example, EduPlanner employs a novel Skill-Tree structure to accurately model the background mathematics knowledge of student groups, personalizing instructional design for curriculum and learning activities according to students' knowledge levels and learning abilities. Additionally, we introduce the CIDDP, an LLM-based five-dimensional evaluation module encompassing clarity, Integrity, Depth, Practicality, and Pertinence, to comprehensively assess mathematics lesson plan quality and bootstrap intelligent optimization. Experiments conducted on the GSM8K and Algebra datasets demonstrate that EduPlanner excels in evaluating and optimizing instructional design for curriculum and learning activities. Ablation studies further validate the significance and effectiveness of each component within the framework. Our code is publicly available at https://github.com/Zc0812/Edu_Planner
IAP: Improving Continual Learning of Vision-Language Models via Instance-Aware Prompting
Mar 26, 2025



Recent pre-trained vision-language models (PT-VLMs) often face a Multi-Domain Class-Incremental Learning (MCIL) scenario in practice, where several classes and domains of multi-modal tasks are incrementally arrived. Without access to previously learned tasks and unseen tasks, memory-constrained MCIL suffers from forward and backward forgetting. To alleviate the above challenges, parameter-efficient fine-tuning techniques (PEFT), such as prompt tuning, are employed to adapt the PT-VLM to the diverse incrementally learned tasks. To achieve effective new task adaptation, existing methods only consider the effect of PEFT strategy selection, but neglect the influence of PEFT parameter setting (e.g., prompting). In this paper, we tackle the challenge of optimizing prompt designs for diverse tasks in MCIL and propose an Instance-Aware Prompting (IAP) framework. Specifically, our Instance-Aware Gated Prompting (IA-GP) module enhances adaptation to new tasks while mitigating forgetting by dynamically assigning prompts across transformer layers at the instance level. Our Instance-Aware Class-Distribution-Driven Prompting (IA-CDDP) improves the task adaptation process by determining an accurate task-label-related confidence score for each instance. Experimental evaluations across 11 datasets, using three performance metrics, demonstrate the effectiveness of our proposed method. Code can be found at https://github.com/FerdinandZJU/IAP.
QualiSpeech: A Speech Quality Assessment Dataset with Natural Language Reasoning and Descriptions
Mar 26, 2025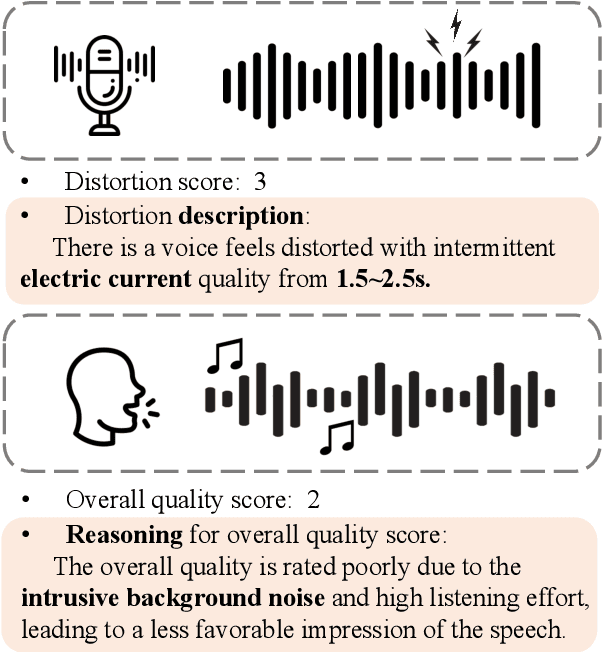
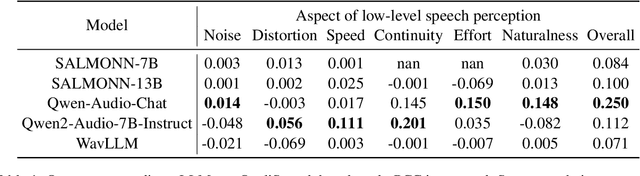
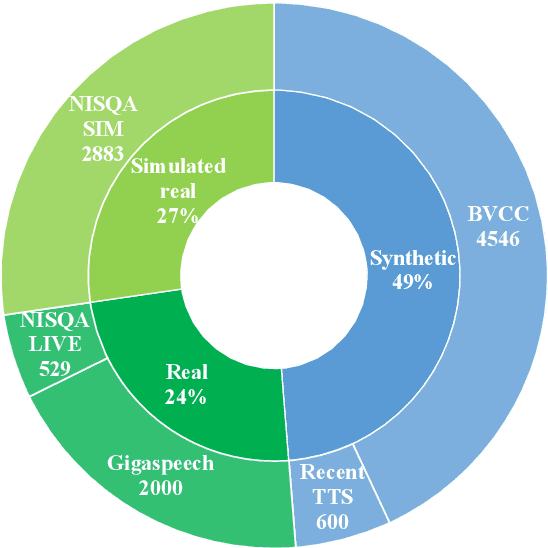
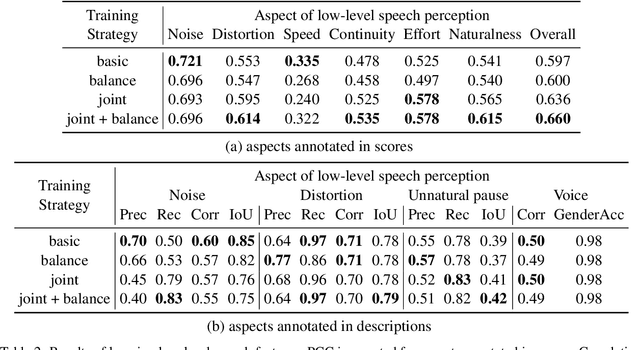
This paper explores a novel perspective to speech quality assessment by leveraging natural language descriptions, offering richer, more nuanced insights than traditional numerical scoring methods. Natural language feedback provides instructive recommendations and detailed evaluations, yet existing datasets lack the comprehensive annotations needed for this approach. To bridge this gap, we introduce QualiSpeech, a comprehensive low-level speech quality assessment dataset encompassing 11 key aspects and detailed natural language comments that include reasoning and contextual insights. Additionally, we propose the QualiSpeech Benchmark to evaluate the low-level speech understanding capabilities of auditory large language models (LLMs). Experimental results demonstrate that finetuned auditory LLMs can reliably generate detailed descriptions of noise and distortion, effectively identifying their types and temporal characteristics. The results further highlight the potential for incorporating reasoning to enhance the accuracy and reliability of quality assessments. The dataset will be released at https://huggingface.co/datasets/tsinghua-ee/QualiSpeech.
ACVUBench: Audio-Centric Video Understanding Benchmark
Mar 25, 2025



Audio often serves as an auxiliary modality in video understanding tasks of audio-visual large language models (LLMs), merely assisting in the comprehension of visual information. However, a thorough understanding of videos significantly depends on auditory information, as audio offers critical context, emotional cues, and semantic meaning that visual data alone often lacks. This paper proposes an audio-centric video understanding benchmark (ACVUBench) to evaluate the video comprehension capabilities of multimodal LLMs with a particular focus on auditory information. Specifically, ACVUBench incorporates 2,662 videos spanning 18 different domains with rich auditory information, together with over 13k high-quality human annotated or validated question-answer pairs. Moreover, ACVUBench introduces a suite of carefully designed audio-centric tasks, holistically testing the understanding of both audio content and audio-visual interactions in videos. A thorough evaluation across a diverse range of open-source and proprietary multimodal LLMs is performed, followed by the analyses of deficiencies in audio-visual LLMs. Demos are available at https://github.com/lark-png/ACVUBench.
Language Model Uncertainty Quantification with Attention Chain
Mar 24, 2025Accurately quantifying a large language model's (LLM) predictive uncertainty is crucial for judging the reliability of its answers. While most existing research focuses on short, directly answerable questions with closed-form outputs (e.g., multiple-choice), involving intermediate reasoning steps in LLM responses is increasingly important. This added complexity complicates uncertainty quantification (UQ) because the probabilities assigned to answer tokens are conditioned on a vast space of preceding reasoning tokens. Direct marginalization is infeasible, and the dependency inflates probability estimates, causing overconfidence in UQ. To address this, we propose UQAC, an efficient method that narrows the reasoning space to a tractable size for marginalization. UQAC iteratively constructs an "attention chain" of tokens deemed "semantically crucial" to the final answer via a backtracking procedure. Starting from the answer tokens, it uses attention weights to identify the most influential predecessors, then iterates this process until reaching the input tokens. Similarity filtering and probability thresholding further refine the resulting chain, allowing us to approximate the marginal probabilities of the answer tokens, which serve as the LLM's confidence. We validate UQAC on multiple reasoning benchmarks with advanced open-source LLMs, demonstrating that it consistently delivers reliable UQ estimates with high computational efficiency.
Improving LLM Video Understanding with 16 Frames Per Second
Mar 18, 2025



Human vision is dynamic and continuous. However, in video understanding with multimodal large language models (LLMs), existing methods primarily rely on static features extracted from images sampled at a fixed low frame rate of frame-per-second (FPS) $\leqslant$2, leading to critical visual information loss. In this paper, we introduce F-16, the first multimodal LLM designed for high-frame-rate video understanding. By increasing the frame rate to 16 FPS and compressing visual tokens within each 1-second clip, F-16 efficiently captures dynamic visual features while preserving key semantic information. Experimental results demonstrate that higher frame rates considerably enhance video understanding across multiple benchmarks, providing a new approach to improving video LLMs beyond scaling model size or training data. F-16 achieves state-of-the-art performance among 7-billion-parameter video LLMs on both general and fine-grained video understanding benchmarks, such as Video-MME and TemporalBench. Furthermore, F-16 excels in complex spatiotemporal tasks, including high-speed sports analysis (\textit{e.g.}, basketball, football, gymnastics, and diving), outperforming SOTA proprietary visual models like GPT-4o and Gemini-1.5-pro. Additionally, we introduce a novel decoding method for F-16 that enables highly efficient low-frame-rate inference without requiring model retraining. Upon acceptance, we will release the source code, model checkpoints, and data.
YuE: Scaling Open Foundation Models for Long-Form Music Generation
Mar 11, 2025We tackle the task of long-form music generation--particularly the challenging \textbf{lyrics-to-song} problem--by introducing YuE, a family of open foundation models based on the LLaMA2 architecture. Specifically, YuE scales to trillions of tokens and generates up to five minutes of music while maintaining lyrical alignment, coherent musical structure, and engaging vocal melodies with appropriate accompaniment. It achieves this through (1) track-decoupled next-token prediction to overcome dense mixture signals, (2) structural progressive conditioning for long-context lyrical alignment, and (3) a multitask, multiphase pre-training recipe to converge and generalize. In addition, we redesign the in-context learning technique for music generation, enabling versatile style transfer (e.g., converting Japanese city pop into an English rap while preserving the original accompaniment) and bidirectional generation. Through extensive evaluation, we demonstrate that YuE matches or even surpasses some of the proprietary systems in musicality and vocal agility. In addition, fine-tuning YuE enables additional controls and enhanced support for tail languages. Furthermore, beyond generation, we show that YuE's learned representations can perform well on music understanding tasks, where the results of YuE match or exceed state-of-the-art methods on the MARBLE benchmark. Keywords: lyrics2song, song generation, long-form, foundation model, music generation
EvolvingGS: High-Fidelity Streamable Volumetric Video via Evolving 3D Gaussian Representation
Mar 07, 2025



We have recently seen great progress in 3D scene reconstruction through explicit point-based 3D Gaussian Splatting (3DGS), notable for its high quality and fast rendering speed. However, reconstructing dynamic scenes such as complex human performances with long durations remains challenging. Prior efforts fall short of modeling a long-term sequence with drastic motions, frequent topology changes or interactions with props, and resort to segmenting the whole sequence into groups of frames that are processed independently, which undermines temporal stability and thereby leads to an unpleasant viewing experience and inefficient storage footprint. In view of this, we introduce EvolvingGS, a two-stage strategy that first deforms the Gaussian model to coarsely align with the target frame, and then refines it with minimal point addition/subtraction, particularly in fast-changing areas. Owing to the flexibility of the incrementally evolving representation, our method outperforms existing approaches in terms of both per-frame and temporal quality metrics while maintaining fast rendering through its purely explicit representation. Moreover, by exploiting temporal coherence between successive frames, we propose a simple yet effective compression algorithm that achieves over 50x compression rate. Extensive experiments on both public benchmarks and challenging custom datasets demonstrate that our method significantly advances the state-of-the-art in dynamic scene reconstruction, particularly for extended sequences with complex human performances.
Every FLOP Counts: Scaling a 300B Mixture-of-Experts LING LLM without Premium GPUs
Mar 07, 2025



In this technical report, we tackle the challenges of training large-scale Mixture of Experts (MoE) models, focusing on overcoming cost inefficiency and resource limitations prevalent in such systems. To address these issues, we present two differently sized MoE large language models (LLMs), namely Ling-Lite and Ling-Plus (referred to as "Bailing" in Chinese, spelled B\v{a}il\'ing in Pinyin). Ling-Lite contains 16.8 billion parameters with 2.75 billion activated parameters, while Ling-Plus boasts 290 billion parameters with 28.8 billion activated parameters. Both models exhibit comparable performance to leading industry benchmarks. This report offers actionable insights to improve the efficiency and accessibility of AI development in resource-constrained settings, promoting more scalable and sustainable technologies. Specifically, to reduce training costs for large-scale MoE models, we propose innovative methods for (1) optimization of model architecture and training processes, (2) refinement of training anomaly handling, and (3) enhancement of model evaluation efficiency. Additionally, leveraging high-quality data generated from knowledge graphs, our models demonstrate superior capabilities in tool use compared to other models. Ultimately, our experimental findings demonstrate that a 300B MoE LLM can be effectively trained on lower-performance devices while achieving comparable performance to models of a similar scale, including dense and MoE models. Compared to high-performance devices, utilizing a lower-specification hardware system during the pre-training phase demonstrates significant cost savings, reducing computing costs by approximately 20%. The models can be accessed at https://huggingface.co/inclusionAI.