 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGANs for Medical Image Analysis
Sep 13, 2018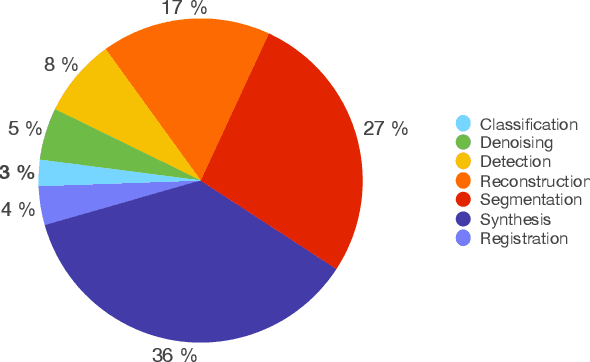

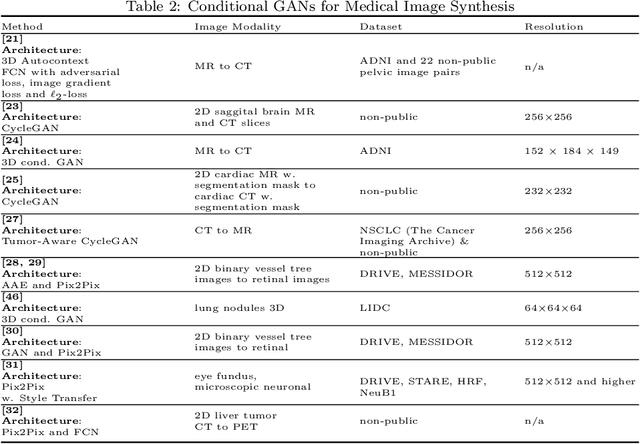
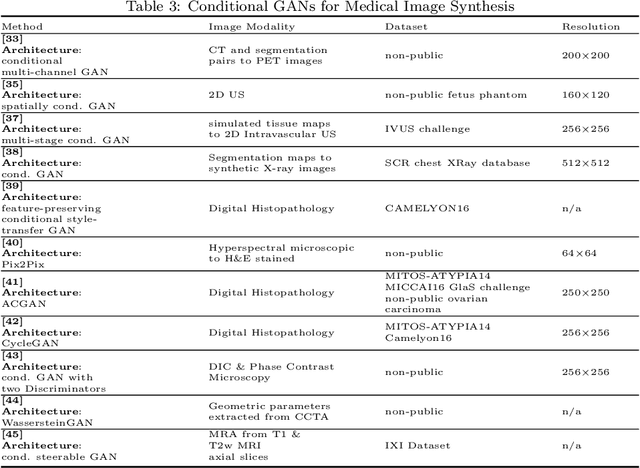
Generative Adversarial Networks (GANs) and their extensions have carved open many exciting ways to tackle well known and challenging medical image analysis problems such as medical image denoising, reconstruction, segmentation, data simulation, detection or classification. Furthermore, their ability to synthesize images at unprecedented levels of realism also gives hope that the chronic scarcity of labeled data in the medical field can be resolved with the help of these generative models. In this review paper, a broad overview of recent literature on GANs for medical applications is given, the shortcomings and opportunities of the proposed methods are thoroughly discussed and potential future work is elaborated. A total of 63 papers published until end of July 2018 are reviewed. For quick access, the papers and important details such as the underlying method, datasets and performance are summarized in tables.
Chest X-ray Inpainting with Deep Generative Models
Aug 29, 2018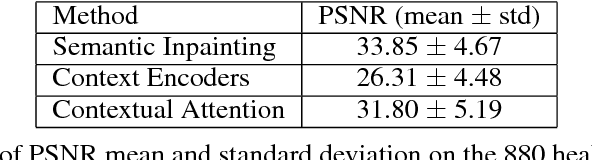
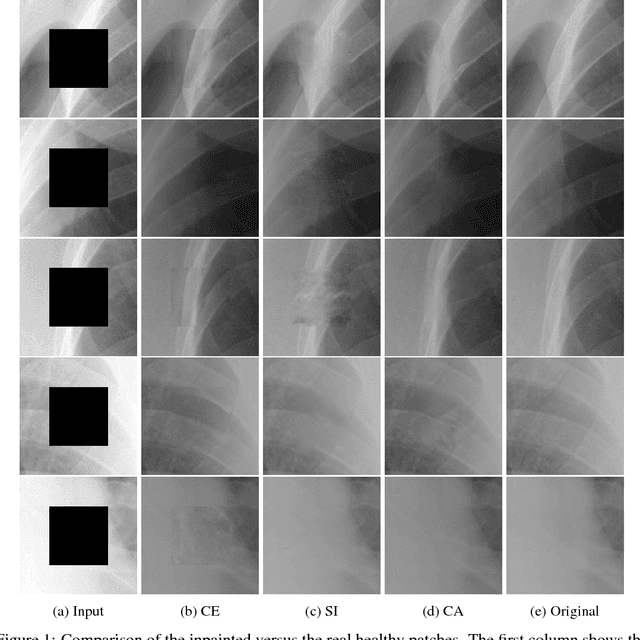
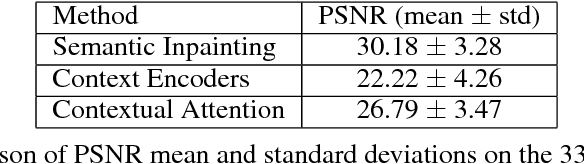

Generative adversarial networks have been successfully applied to inpainting in natural images. However, the current state-of-the-art models have not yet been widely adopted in the medical imaging domain. In this paper, we investigate the performance of three recently published deep learning based inpainting models: context encoders, semantic image inpainting, and the contextual attention model, applied to chest x-rays, as the chest exam is the most commonly performed radiological procedure. We train these generative models on 1.2M 128 $\times$ 128 patches from 60K healthy x-rays, and learn to predict the center 64 $\times$ 64 region in each patch. We test the models on both the healthy and abnormal radiographs. We evaluate the results by visual inspection and comparing the PSNR scores. The outputs of the models are in most cases highly realistic. We show that the methods have potential to enhance and detect abnormalities. In addition, we perform a 2AFC observer study and show that an experienced human observer performs poorly in detecting inpainted regions, particularly those generated by the contextual attention model.
Epithelium segmentation using deep learning in H&E-stained prostate specimens with immunohistochemistry as reference standard
Aug 17, 2018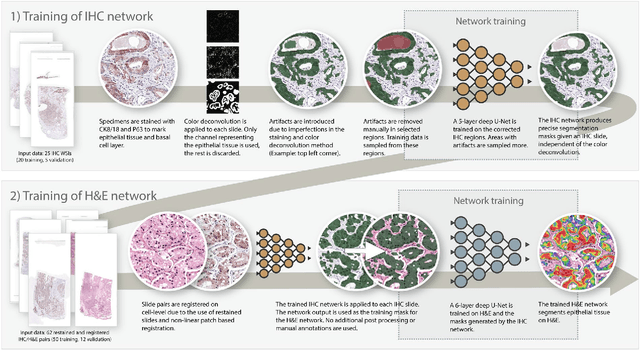
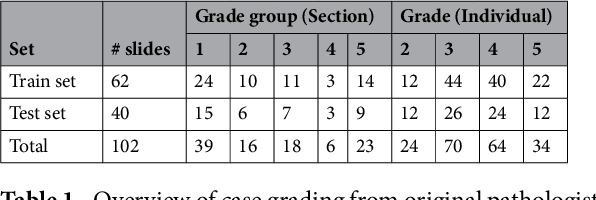
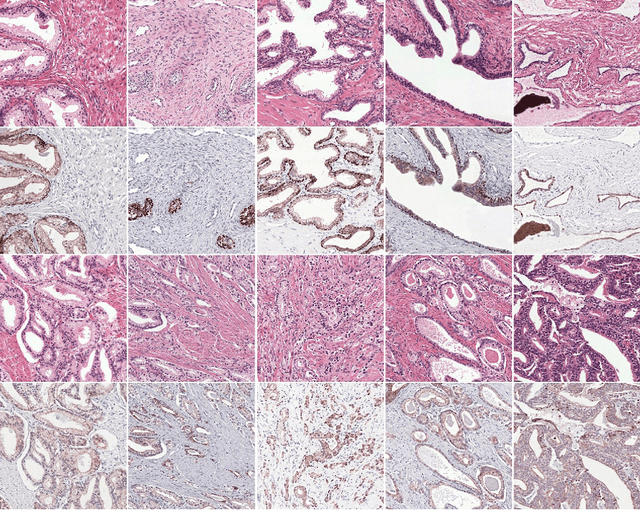
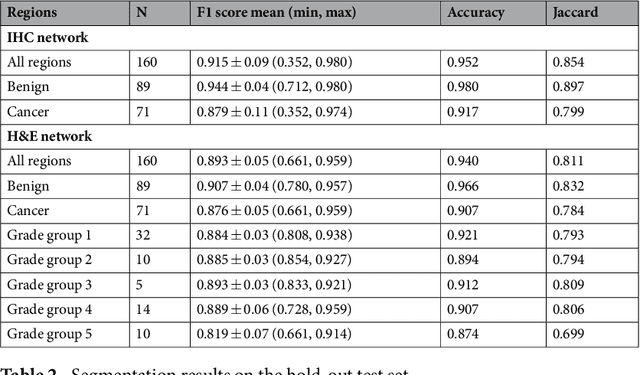
Prostate cancer (PCa) is graded by pathologists by examining the architectural pattern of cancerous epithelial tissue on hematoxylin and eosin (H&E) stained slides. Given the importance of gland morphology, automatically differentiating between glandular epithelial tissue and other tissues is an important prerequisite for the development of automated methods for detecting PCa. We propose a new method, using deep learning, for automatically segmenting epithelial tissue in digitized prostatectomy slides. We employed immunohistochemistry (IHC) to render the ground truth less subjective and more precise compared to manual outlining on H&E slides, especially in areas with high-grade and poorly differentiated PCa. Our dataset consisted of 102 tissue blocks, including both low and high grade PCa. From each block a single new section was cut, stained with H&E, scanned, restained using P63 and CK8/18 to highlight the epithelial structure, and scanned again. The H&E slides were co-registered to the IHC slides. On a subset of the IHC slides we applied color deconvolution, corrected stain errors manually, and trained a U-Net to perform segmentation of epithelial structures. Whole-slide segmentation masks generated by the IHC U-Net were used to train a second U-Net on H&E. Our system makes precise cell-level segmentations and segments both intact glands as well as individual (tumor) epithelial cells. We achieved an F1-score of 0.895 on a hold-out test set and 0.827 on an external reference set from a different center. We envision this segmentation as being the first part of a fully automated prostate cancer detection and grading pipeline.
Is the winner really the best? A critical analysis of common research practice in biomedical image analysis competitions
Jun 06, 2018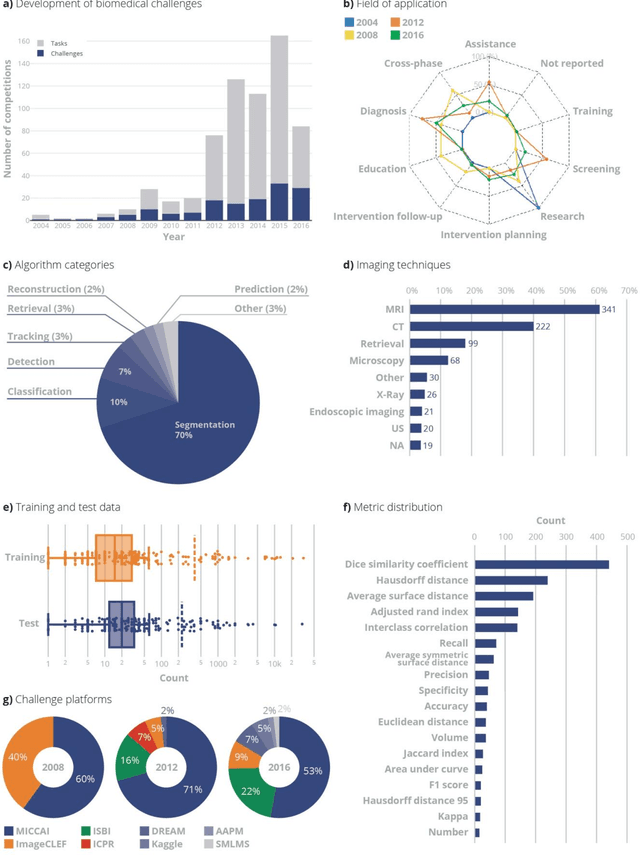
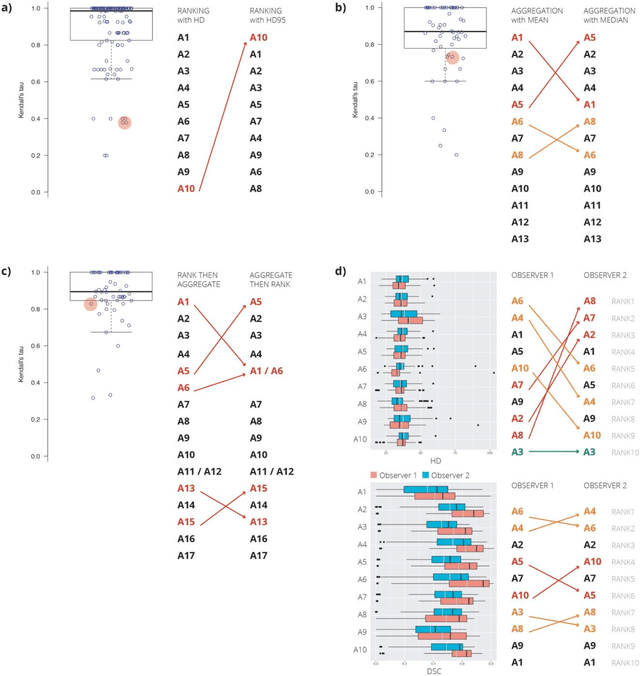
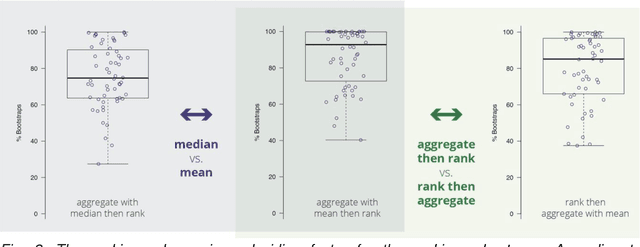
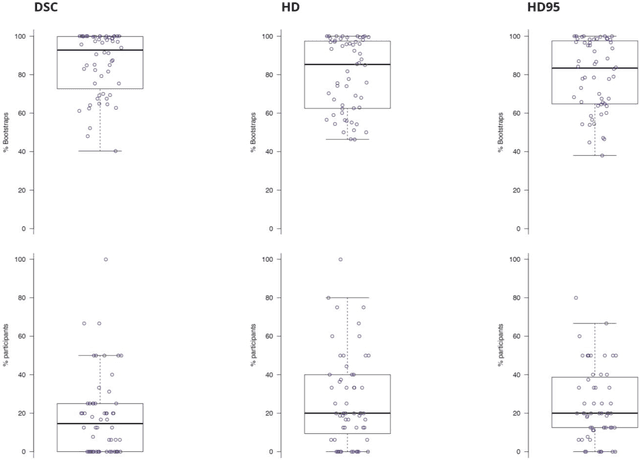
International challenges have become the standard for validation of biomedical image analysis methods. Given their scientific impact, it is surprising that a critical analysis of common practices related to the organization of challenges has not yet been performed. In this paper, we present a comprehensive analysis of biomedical image analysis challenges conducted up to now. We demonstrate the importance of challenges and show that the lack of quality control has critical consequences. First, reproducibility and interpretation of the results is often hampered as only a fraction of relevant information is typically provided. Second, the rank of an algorithm is generally not robust to a number of variables such as the test data used for validation, the ranking scheme applied and the observers that make the reference annotations. To overcome these problems, we recommend best practice guidelines and define open research questions to be addressed in the future.
Iterative fully convolutional neural networks for automatic vertebra segmentation
Apr 12, 2018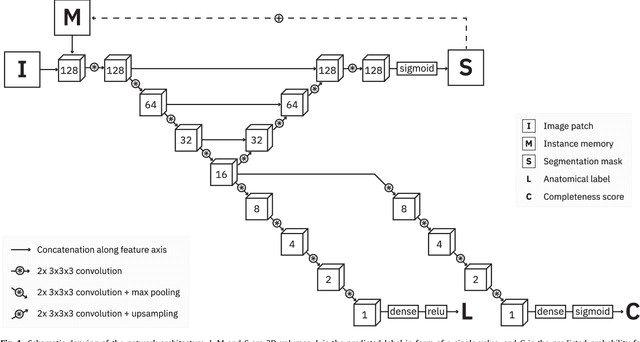
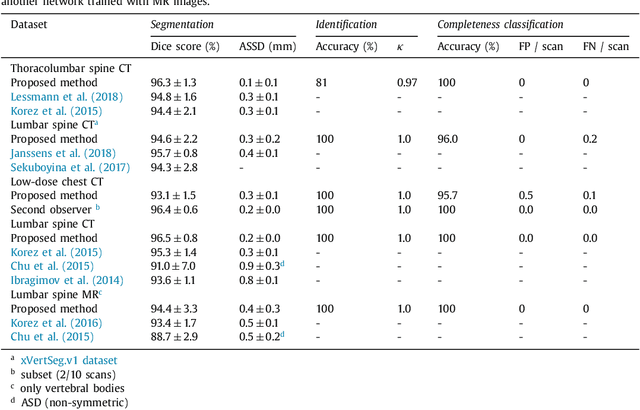
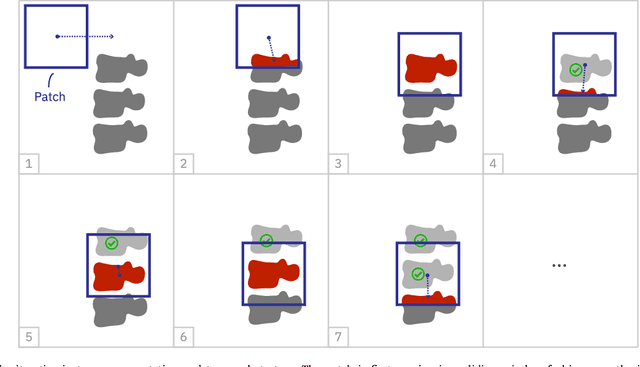
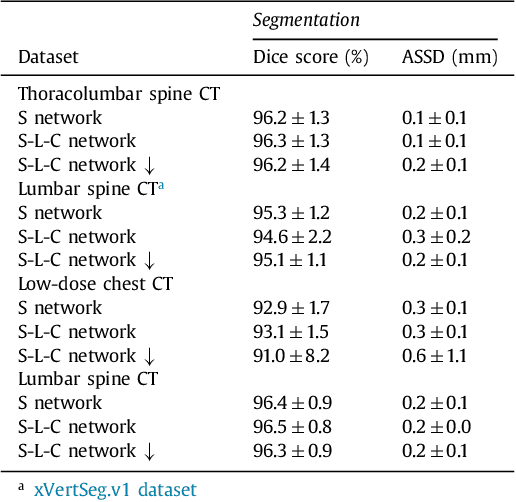
Precise segmentation of the vertebrae is often required for automatic detection of vertebral abnormalities. This especially enables incidental detection of abnormalities such as compression fractures in images that were acquired for other diagnostic purposes. While many CT and MR scans of the chest and abdomen cover a section of the spine, they often do not cover the entire spine. Additionally, the first and last visible vertebrae are likely only partially included in such scans. In this paper, we therefore approach vertebra segmentation as an instance segmentation problem. A fully convolutional neural network is combined with an instance memory that retains information about already segmented vertebrae. This network iteratively analyzes image patches, using the instance memory to search for and segment the first not yet segmented vertebra. At the same time, each vertebra is classified as completely or partially visible, so that partially visible vertebrae can be excluded from further analyses. We evaluated this method on spine CT scans from a vertebra segmentation challenge and on low-dose chest CT scans. The method achieved an average Dice score of 95.8% and 92.1%, respectively, and a mean absolute surface distance of 0.194 mm and 0.344 mm.
Student Beats the Teacher: Deep Neural Networks for Lateral Ventricles Segmentation in Brain MR
Mar 03, 2018Ventricular volume and its progression are known to be linked to several brain diseases such as dementia and schizophrenia. Therefore accurate measurement of ventricle volume is vital for longitudinal studies on these disorders, making automated ventricle segmentation algorithms desirable. In the past few years, deep neural networks have shown to outperform the classical models in many imaging domains. However, the success of deep networks is dependent on manually labeled data sets, which are expensive to acquire especially for higher dimensional data in the medical domain. In this work, we show that deep neural networks can be trained on much-cheaper-to-acquire pseudo-labels (e.g., generated by other automated less accurate methods) and still produce more accurate segmentations compared to the quality of the labels. To show this, we use noisy segmentation labels generated by a conventional region growing algorithm to train a deep network for lateral ventricle segmentation. Then on a large manually annotated test set, we show that the network significantly outperforms the conventional region growing algorithm which was used to produce the training labels for the network. Our experiments report a Dice Similarity Coefficient (DSC) of $0.874$ for the trained network compared to $0.754$ for the conventional region growing algorithm ($p < 0.001$).
* 7 pages, 4 figures, SPIE Medical Imaging 2018 Conference paper
Automatic calcium scoring in low-dose chest CT using deep neural networks with dilated convolutions
Feb 01, 2018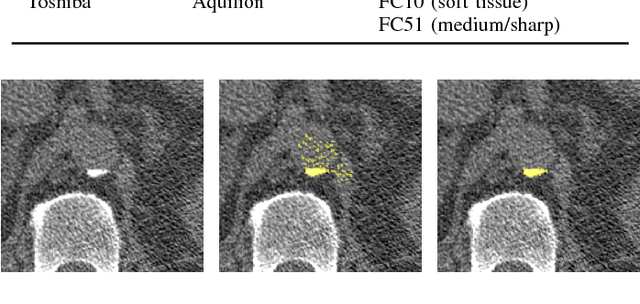
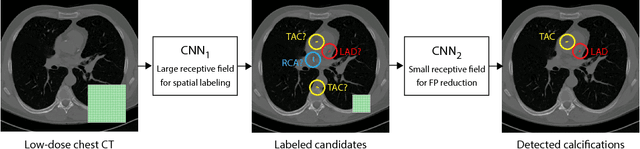
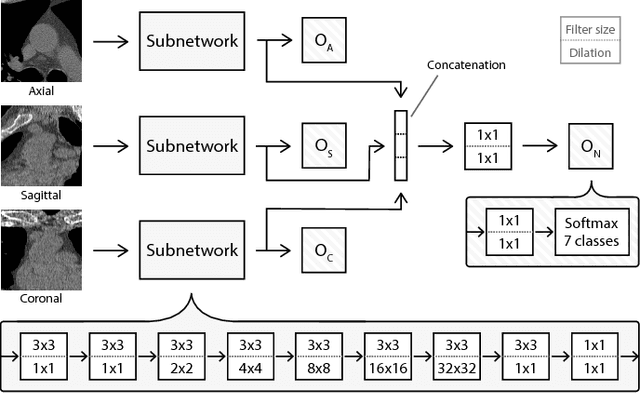
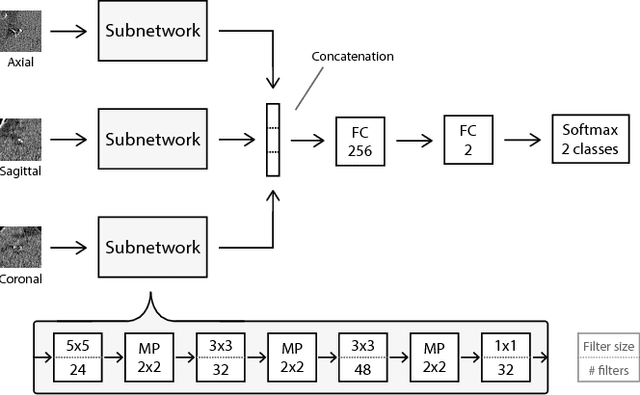
Heavy smokers undergoing screening with low-dose chest CT are affected by cardiovascular disease as much as by lung cancer. Low-dose chest CT scans acquired in screening enable quantification of atherosclerotic calcifications and thus enable identification of subjects at increased cardiovascular risk. This paper presents a method for automatic detection of coronary artery, thoracic aorta and cardiac valve calcifications in low-dose chest CT using two consecutive convolutional neural networks. The first network identifies and labels potential calcifications according to their anatomical location and the second network identifies true calcifications among the detected candidates. This method was trained and evaluated on a set of 1744 CT scans from the National Lung Screening Trial. To determine whether any reconstruction or only images reconstructed with soft tissue filters can be used for calcification detection, we evaluated the method on soft and medium/sharp filter reconstructions separately. On soft filter reconstructions, the method achieved F1 scores of 0.89, 0.89, 0.67, and 0.55 for coronary artery, thoracic aorta, aortic valve and mitral valve calcifications, respectively. On sharp filter reconstructions, the F1 scores were 0.84, 0.81, 0.64, and 0.66, respectively. Linearly weighted kappa coefficients for risk category assignment based on per subject coronary artery calcium were 0.91 and 0.90 for soft and sharp filter reconstructions, respectively. These results demonstrate that the presented method enables reliable automatic cardiovascular risk assessment in all low-dose chest CT scans acquired for lung cancer screening.
Validation, comparison, and combination of algorithms for automatic detection of pulmonary nodules in computed tomography images: the LUNA16 challenge
Jul 15, 2017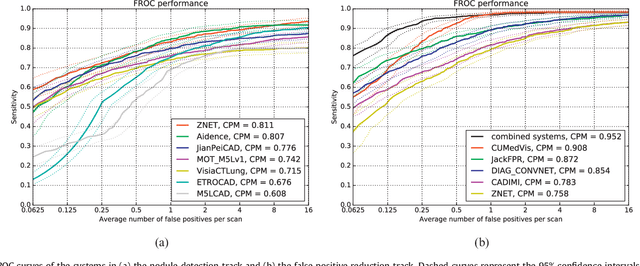
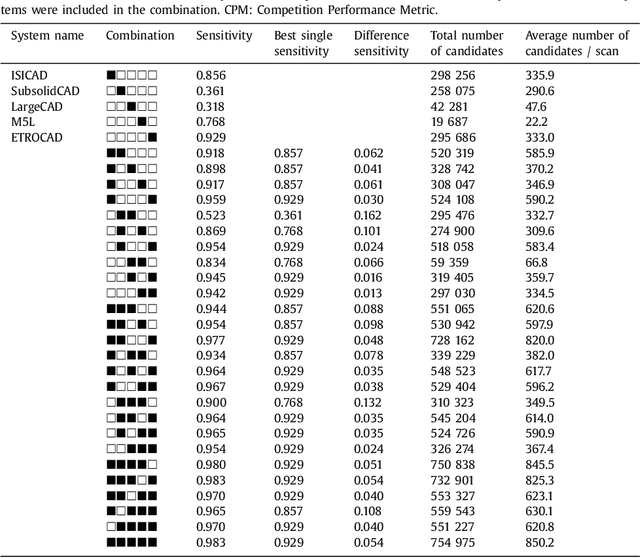

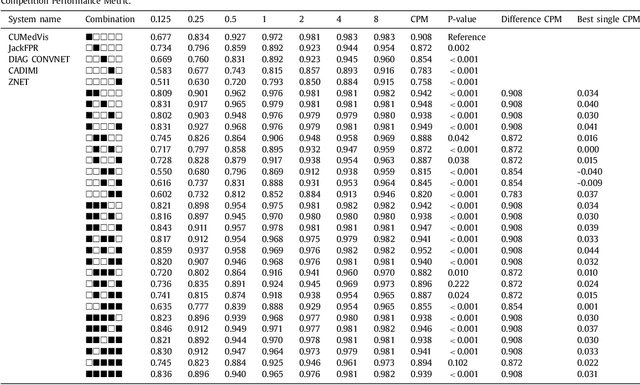
Automatic detection of pulmonary nodules in thoracic computed tomography (CT) scans has been an active area of research for the last two decades. However, there have only been few studies that provide a comparative performance evaluation of different systems on a common database. We have therefore set up the LUNA16 challenge, an objective evaluation framework for automatic nodule detection algorithms using the largest publicly available reference database of chest CT scans, the LIDC-IDRI data set. In LUNA16, participants develop their algorithm and upload their predictions on 888 CT scans in one of the two tracks: 1) the complete nodule detection track where a complete CAD system should be developed, or 2) the false positive reduction track where a provided set of nodule candidates should be classified. This paper describes the setup of LUNA16 and presents the results of the challenge so far. Moreover, the impact of combining individual systems on the detection performance was also investigated. It was observed that the leading solutions employed convolutional networks and used the provided set of nodule candidates. The combination of these solutions achieved an excellent sensitivity of over 95% at fewer than 1.0 false positives per scan. This highlights the potential of combining algorithms to improve the detection performance. Our observer study with four expert readers has shown that the best system detects nodules that were missed by expert readers who originally annotated the LIDC-IDRI data. We released this set of additional nodules for further development of CAD systems.
A Survey on Deep Learning in Medical Image Analysis
Jun 04, 2017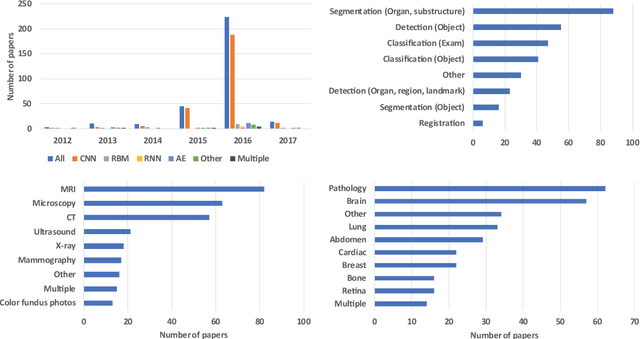
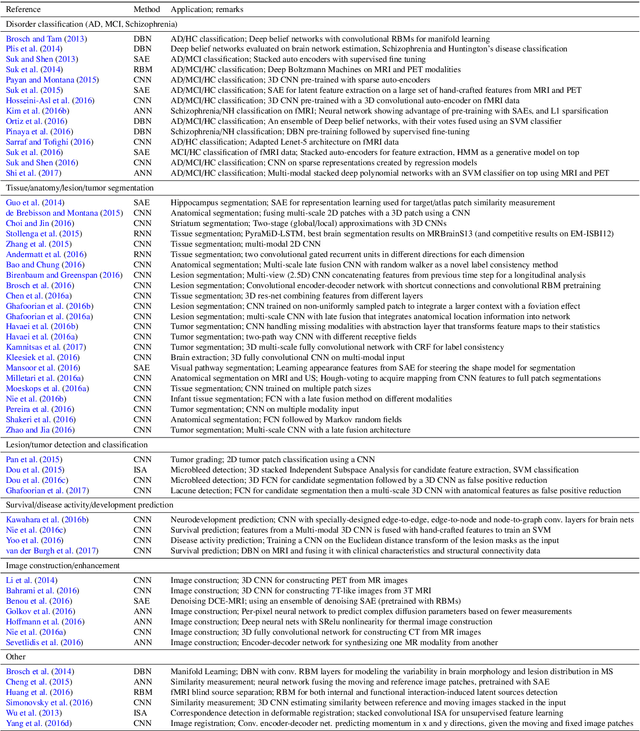
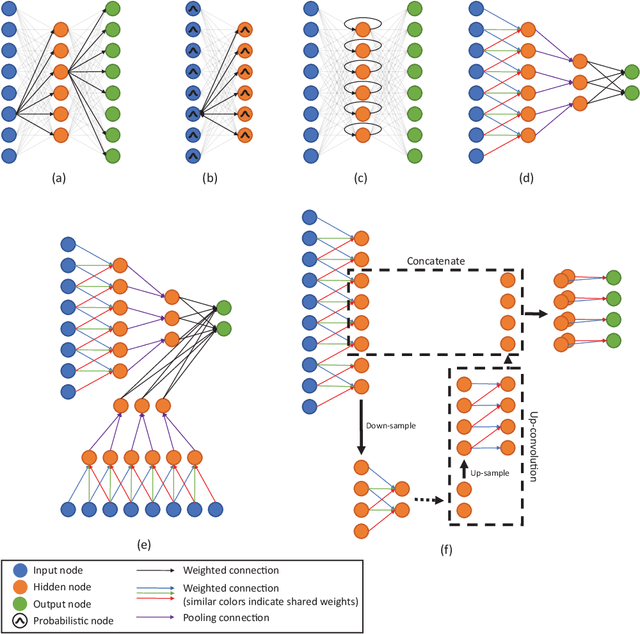

Deep learning algorithms, in particular convolutional networks, have rapidly become a methodology of choice for analyzing medical images. This paper reviews the major deep learning concepts pertinent to medical image analysis and summarizes over 300 contributions to the field, most of which appeared in the last year. We survey the use of deep learning for image classification, object detection, segmentation, registration, and other tasks and provide concise overviews of studies per application area. Open challenges and directions for future research are discussed.
Towards automatic pulmonary nodule management in lung cancer screening with deep learning
May 23, 2017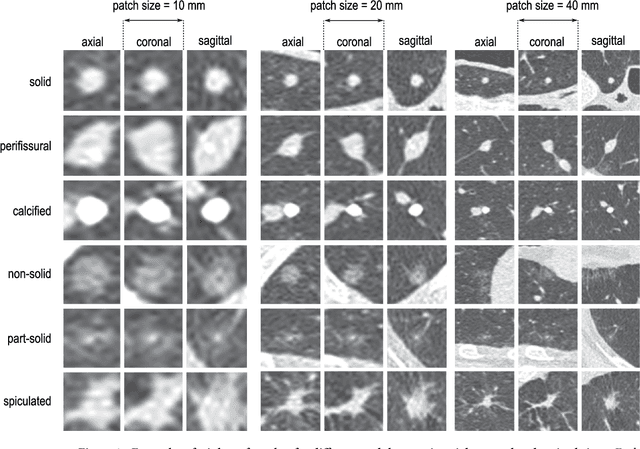
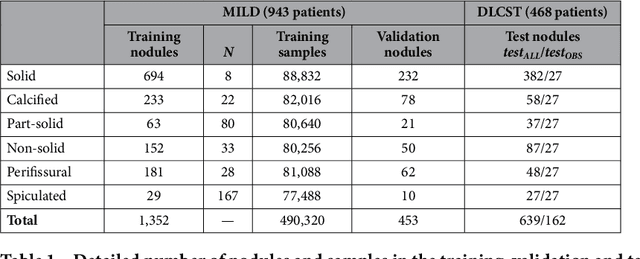
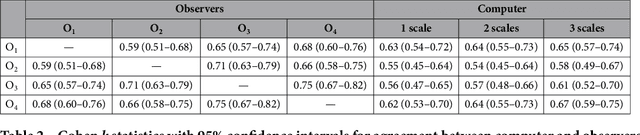

The introduction of lung cancer screening programs will produce an unprecedented amount of chest CT scans in the near future, which radiologists will have to read in order to decide on a patient follow-up strategy. According to the current guidelines, the workup of screen-detected nodules strongly relies on nodule size and nodule type. In this paper, we present a deep learning system based on multi-stream multi-scale convolutional networks, which automatically classifies all nodule types relevant for nodule workup. The system processes raw CT data containing a nodule without the need for any additional information such as nodule segmentation or nodule size and learns a representation of 3D data by analyzing an arbitrary number of 2D views of a given nodule. The deep learning system was trained with data from the Italian MILD screening trial and validated on an independent set of data from the Danish DLCST screening trial. We analyze the advantage of processing nodules at multiple scales with a multi-stream convolutional network architecture, and we show that the proposed deep learning system achieves performance at classifying nodule type that surpasses the one of classical machine learning approaches and is within the inter-observer variability among four experienced human observers.
* Published on Scientific Reports