 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Game of Bundle Adjustment -- Learning Efficient Convergence
Aug 25, 2023



Bundle adjustment is the common way to solve localization and mapping. It is an iterative process in which a system of non-linear equations is solved using two optimization methods, weighted by a damping factor. In the classic approach, the latter is chosen heuristically by the Levenberg-Marquardt algorithm on each iteration. This might take many iterations, making the process computationally expensive, which might be harmful to real-time applications. We propose to replace this heuristic by viewing the problem in a holistic manner, as a game, and formulating it as a reinforcement-learning task. We set an environment which solves the non-linear equations and train an agent to choose the damping factor in a learned manner. We demonstrate that our approach considerably reduces the number of iterations required to reach the bundle adjustment's convergence, on both synthetic and real-life scenarios. We show that this reduction benefits the classic approach and can be integrated with other bundle adjustment acceleration methods.
Can Q-learning solve Multi Armed Bantids?
Oct 21, 2021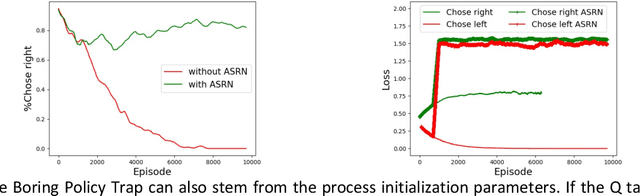
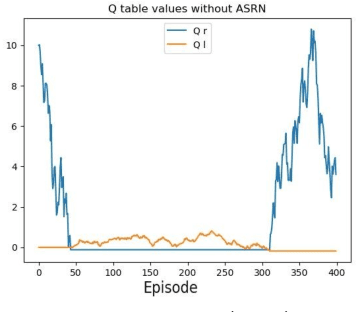
When a reinforcement learning (RL) method has to decide between several optional policies by solely looking at the received reward, it has to implicitly optimize a Multi-Armed-Bandit (MAB) problem. This arises the question: are current RL algorithms capable of solving MAB problems? We claim that the surprising answer is no. In our experiments we show that in some situations they fail to solve a basic MAB problem, and in many common situations they have a hard time: They suffer from regression in results during training, sensitivity to initialization and high sample complexity. We claim that this stems from variance differences between policies, which causes two problems: The first problem is the "Boring Policy Trap" where each policy have a different implicit exploration depends on its rewards variance, and leaving a boring, or low variance, policy is less likely due to its low implicit exploration. The second problem is the "Manipulative Consultant" problem, where value-estimation functions used in deep RL algorithms such as DQN or deep Actor Critic methods, maximize estimation precision rather than mean rewards, and have a better loss in low-variance policies, which cause the network to converge to a sub-optimal policy. Cognitive experiments on humans showed that noised reward signals may paradoxically improve performance. We explain this using the aforementioned problems, claiming that both humans and algorithms may share similar challenges in decision making. Inspired by this result, we propose the Adaptive Symmetric Reward Noising (ASRN) method, by which we mean equalizing the rewards variance across different policies, thus avoiding the two problems without affecting the environment's mean rewards behavior. We demonstrate that the ASRN scheme can dramatically improve the results.
Adaptive Symmetric Reward Noising for Reinforcement Learning
May 24, 2019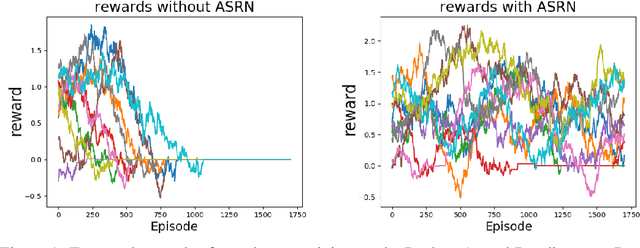
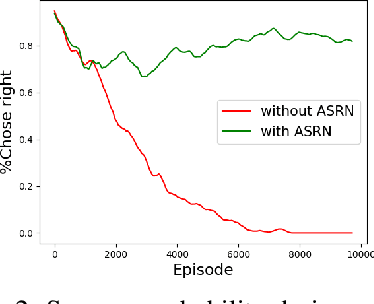
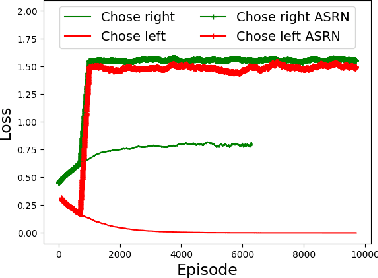
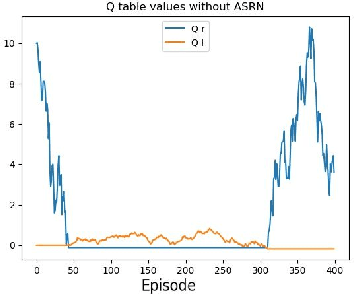
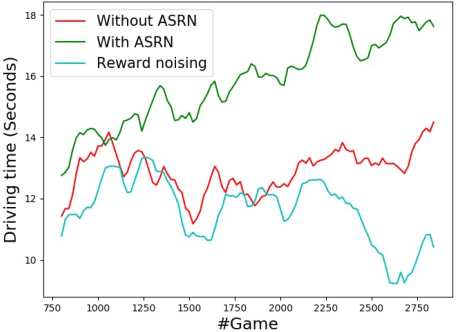
Recent reinforcement learning algorithms, though achieving impressive results in various fields, suffer from brittle training effects such as regression in results and high sensitivity to initialization and parameters. We claim that some of the brittleness stems from variance differences, i.e. when different environment areas - states and/or actions - have different rewards variance. This causes two problems: First, the "Boring Areas Trap" in algorithms such as Q-learning, where moving between areas depends on the current area variance, and getting out of a boring area is hard due to its low variance. Second, the "Manipulative Consultant" problem, when value-estimation functions used in DQN and Actor-Critic algorithms influence the agent to prefer boring areas, regardless of the mean rewards return, as they maximize estimation precision rather than rewards. This sheds a new light on how exploration contribute to training, as it helps with both challenges. Cognitive experiments in humans showed that noised reward signals may paradoxically improve performance. We explain this using the two mentioned problems, claiming that both humans and algorithms may share similar challenges. Inspired by this result, we propose the Adaptive Symmetric Reward Noising (ASRN), by which we mean adding Gaussian noise to rewards according to their states' estimated variance, thus avoiding the two problems while not affecting the environment's mean rewards behavior. We conduct our experiments in a Multi Armed Bandit problem with variance differences. We demonstrate that a Q-learning algorithm shows the brittleness effect in this problem, and that the ASRN scheme can dramatically improve the results. We show that ASRN helps a DQN algorithm training process reach better results in an end to end autonomous driving task using the AirSim driving simulator.
The Liver Tumor Segmentation Benchmark (LiTS)
Jan 13, 2019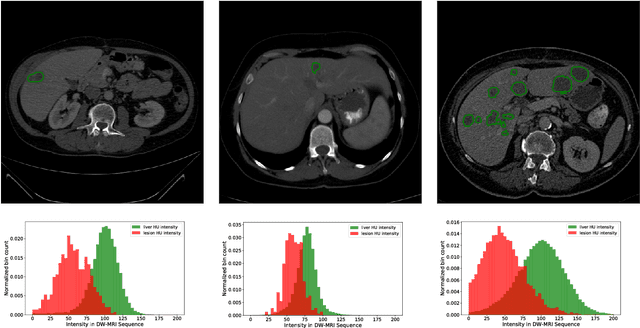

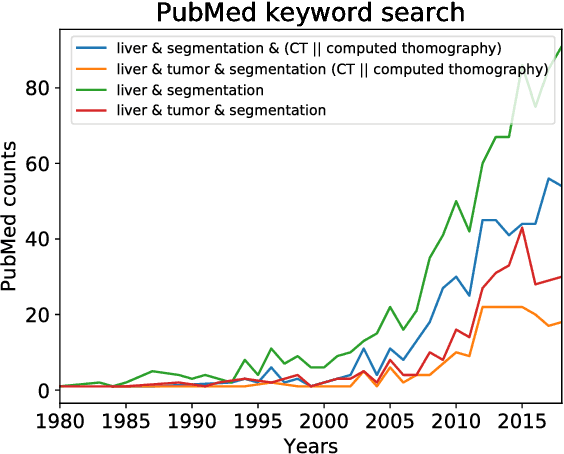

In this work, we report the set-up and results of the Liver Tumor Segmentation Benchmark (LITS) organized in conjunction with the IEEE International Symposium on Biomedical Imaging (ISBI) 2016 and International Conference On Medical Image Computing Computer Assisted Intervention (MICCAI) 2017. Twenty four valid state-of-the-art liver and liver tumor segmentation algorithms were applied to a set of 131 computed tomography (CT) volumes with different types of tumor contrast levels (hyper-/hypo-intense), abnormalities in tissues (metastasectomie) size and varying amount of lesions. The submitted algorithms have been tested on 70 undisclosed volumes. The dataset is created in collaboration with seven hospitals and research institutions and manually reviewed by independent three radiologists. We found that not a single algorithm performed best for liver and tumors. The best liver segmentation algorithm achieved a Dice score of 0.96(MICCAI) whereas for tumor segmentation the best algorithm evaluated at 0.67(ISBI) and 0.70(MICCAI). The LITS image data and manual annotations continue to be publicly available through an online evaluation system as an ongoing benchmarking resource.