 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAxiomOcean: Forecasting the Three-Dimensional Structure of the Upper Ocean
May 11, 2026Short-term ocean forecast skill depends strongly on the three-dimensional ocean structure of the upper ocean, which governs stratification, subsurface heat storage, and the response of the ocean to atmospheric forcing. However, AI ocean forecasting models often fail to preserve this vertical structure, resulting in over-smoothed subsurface features and weak physical consistency under strong forcing. Here, we present AxiomOcean, a global AI ocean forecasting model that explicitly represents vertical hierarchy and cross-layer dependence within the water column. By combining a fully three-dimensional encoder-backbone-decoder architecture with surface atmospheric forcing, AxiomOcean jointly predicts upper-ocean temperature, salinity, and three-dimensional currents at global 1/12° resolution down to 643 m depth. In 10-day forecasts, AxiomOcean outperforms an advanced AI comparison model across variables and lead times, reducing day-1 RMSE by approximately 20 to 35% while maintaining higher anomaly correlation. The gain is not achieved through excessive smoothing: AxiomOcean better preserves eddy kinetic energy, temperature and salinity variance. Its advantage also extends through the water column and remains evident across the equatorial Pacific, Kuroshio Extension, and Southern Ocean, yielding a more realistic reconstruction of upper-ocean heat content. These results show that explicitly preserving upper-ocean three-dimensional structure can improve both forecast accuracy and physical fidelity in AI ocean prediction.
Weak-PDE-Net: Discovering Open-Form PDEs via Differentiable Symbolic Networks and Weak Formulation
Mar 24, 2026Discovering governing Partial Differential Equations (PDEs) from sparse and noisy data is a challenging issue in data-driven scientific computing. Conventional sparse regression methods often suffer from two major limitations: (i) the instability of numerical differentiation under sparse and noisy data, and (ii) the restricted flexibility of a pre-defined candidate library. We propose Weak-PDE-Net, an end-to-end differentiable framework that can robustly identify open-form PDEs. Weak-PDE-Net consists of two interconnected modules: a forward response learner and a weak-form PDE generator. The learner embeds learnable Gaussian kernels within a lightweight MLP, serving as a surrogate model that adaptively captures system dynamics from sparse observations. Meanwhile, the generator integrates a symbolic network with an integral module to construct weak-form PDEs, avoiding explicit numerical differentiation and improving robustness to noise. To relax the constraints of the pre-defined library, we leverage Differentiable Neural Architecture Search strategy during training to explore the functional space, which enables the efficient discovery of open-form PDEs. The capability of Weak-PDE-Net in multivariable systems discovery is further enhanced by incorporating Galilean Invariance constraints and symmetry equivariance hypotheses to ensure physical consistency. Experiments on several challenging PDE benchmarks demonstrate that Weak-PDE-Net accurately recovers governing equations, even under highly sparse and noisy observations.
Hybrid Consistency Policy: Decoupling Multi-Modal Diversity and Real-Time Efficiency in Robotic Manipulation
Oct 30, 2025In visuomotor policy learning, diffusion-based imitation learning has become widely adopted for its ability to capture diverse behaviors. However, approaches built on ordinary and stochastic denoising processes struggle to jointly achieve fast sampling and strong multi-modality. To address these challenges, we propose the Hybrid Consistency Policy (HCP). HCP runs a short stochastic prefix up to an adaptive switch time, and then applies a one-step consistency jump to produce the final action. To align this one-jump generation, HCP performs time-varying consistency distillation that combines a trajectory-consistency objective to keep neighboring predictions coherent and a denoising-matching objective to improve local fidelity. In both simulation and on a real robot, HCP with 25 SDE steps plus one jump approaches the 80-step DDPM teacher in accuracy and mode coverage while significantly reducing latency. These results show that multi-modality does not require slow inference, and a switch time decouples mode retention from speed. It yields a practical accuracy efficiency trade-off for robot policies.
Fragility-aware Classification for Understanding Risk and Improving Generalization
Feb 18, 2025Classification models play a critical role in data-driven decision-making applications such as medical diagnosis, user profiling, recommendation systems, and default detection. Traditional performance metrics, such as accuracy, focus on overall error rates but fail to account for the confidence of incorrect predictions, thereby overlooking the risk of confident misjudgments. This risk is particularly significant in cost-sensitive and safety-critical domains like medical diagnosis and autonomous driving, where overconfident false predictions may cause severe consequences. To address this issue, we introduce the Fragility Index (FI), a novel metric that evaluates classification performance from a risk-averse perspective by explicitly capturing the tail risk of confident misjudgments. To enhance generalizability, we define FI within the robust satisficing (RS) framework, incorporating data uncertainty. We further develop a model training approach that optimizes FI while maintaining tractability for common loss functions. Specifically, we derive exact reformulations for cross-entropy loss, hinge-type loss, and Lipschitz loss, and extend the approach to deep learning models. Through synthetic experiments and real-world medical diagnosis tasks, we demonstrate that FI effectively identifies misjudgment risk and FI-based training improves model robustness and generalizability. Finally, we extend our framework to deep neural network training, further validating its effectiveness in enhancing deep learning models.
Swin-X2S: Reconstructing 3D Shape from 2D Biplanar X-ray with Swin Transformers
Jan 10, 2025



The conversion from 2D X-ray to 3D shape holds significant potential for improving diagnostic efficiency and safety. However, existing reconstruction methods often rely on hand-crafted features, manual intervention, and prior knowledge, resulting in unstable shape errors and additional processing costs. In this paper, we introduce Swin-X2S, an end-to-end deep learning method for directly reconstructing 3D segmentation and labeling from 2D biplanar orthogonal X-ray images. Swin-X2S employs an encoder-decoder architecture: the encoder leverages 2D Swin Transformer for X-ray information extraction, while the decoder employs 3D convolution with cross-attention to integrate structural features from orthogonal views. A dimension-expanding module is introduced to bridge the encoder and decoder, ensuring a smooth conversion from 2D pixels to 3D voxels. We evaluate proposed method through extensive qualitative and quantitative experiments across nine publicly available datasets covering four anatomies (femur, hip, spine, and rib), with a total of 54 categories. Significant improvements over previous methods have been observed not only in the segmentation and labeling metrics but also in the clinically relevant parameters that are of primary concern in practical applications, which demonstrates the promise of Swin-X2S to provide an effective option for anatomical shape reconstruction in clinical scenarios. Code implementation is available at: \url{https://github.com/liukuan5625/Swin-X2S}.
Multi-modal Multi-label Facial Action Unit Detection with Transformer
Mar 28, 2022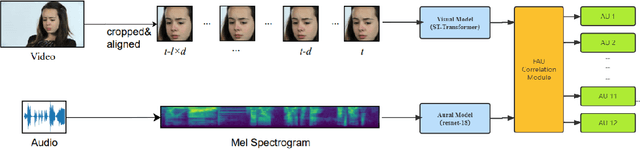
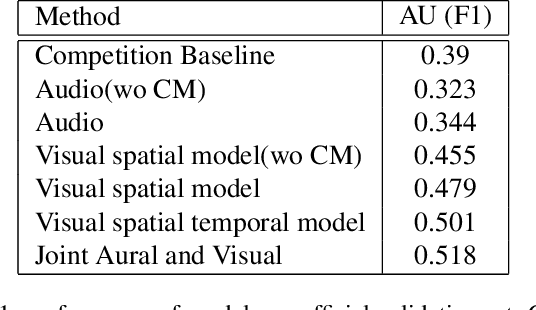
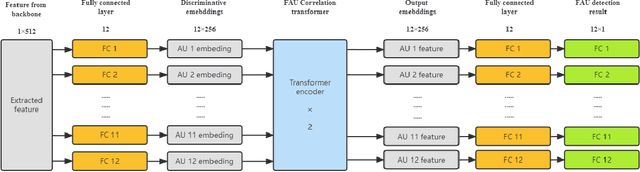
Facial Action Coding System is an important approach of facial expression analysis.This paper describes our submission to the third Affective Behavior Analysis (ABAW) 2022 competition. We proposed a transfomer based model to detect facial action unit (FAU) in video. To be specific, we firstly trained a multi-modal model to extract both audio and visual feature. After that, we proposed a action units correlation module to learn relationships between each action unit labels and refine action unit detection result. Experimental results on validation dataset shows that our method achieves better performance than baseline model, which verifies that the effectiveness of proposed network.
Suction Grasp Region Prediction using Self-supervised Learning for Object Picking in Dense Clutter
Apr 24, 2019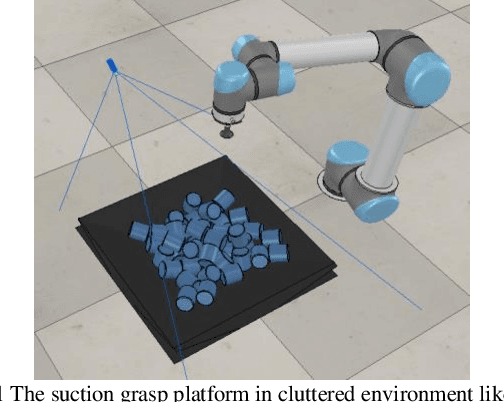
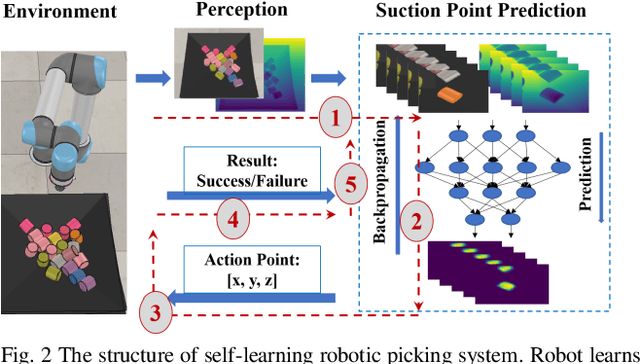
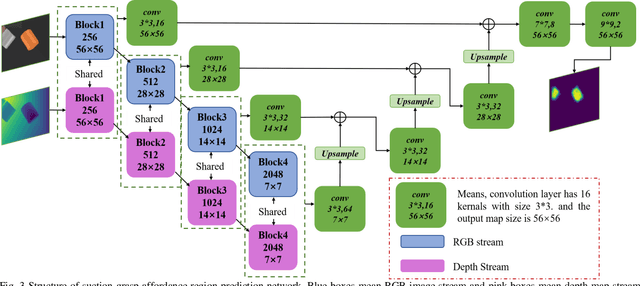

This paper focuses on robotic picking tasks in cluttered scenario. Because of the diversity of poses, types of stack and complicated background in bin picking situation, it is much difficult to recognize and estimate their pose before grasping them. Here, this paper combines Resnet with U-net structure, a special framework of Convolution Neural Networks (CNN), to predict picking region without recognition and pose estimation. And it makes robotic picking system learn picking skills from scratch. At the same time, we train the network end to end with online samples. In the end of this paper, several experiments are conducted to demonstrate the performance of our methods.
The Liver Tumor Segmentation Benchmark (LiTS)
Jan 13, 2019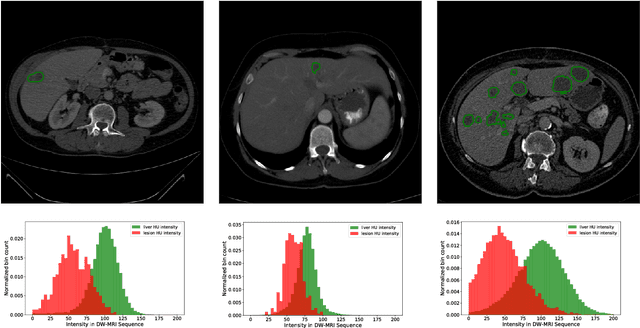


In this work, we report the set-up and results of the Liver Tumor Segmentation Benchmark (LITS) organized in conjunction with the IEEE International Symposium on Biomedical Imaging (ISBI) 2016 and International Conference On Medical Image Computing Computer Assisted Intervention (MICCAI) 2017. Twenty four valid state-of-the-art liver and liver tumor segmentation algorithms were applied to a set of 131 computed tomography (CT) volumes with different types of tumor contrast levels (hyper-/hypo-intense), abnormalities in tissues (metastasectomie) size and varying amount of lesions. The submitted algorithms have been tested on 70 undisclosed volumes. The dataset is created in collaboration with seven hospitals and research institutions and manually reviewed by independent three radiologists. We found that not a single algorithm performed best for liver and tumors. The best liver segmentation algorithm achieved a Dice score of 0.96(MICCAI) whereas for tumor segmentation the best algorithm evaluated at 0.67(ISBI) and 0.70(MICCAI). The LITS image data and manual annotations continue to be publicly available through an online evaluation system as an ongoing benchmarking resource.
Global and Local Information Based Deep Network for Skin Lesion Segmentation
Mar 16, 2017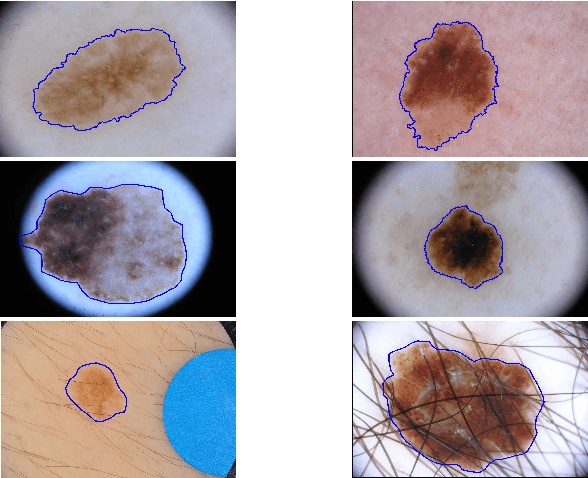
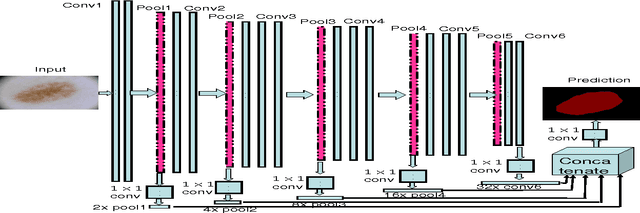
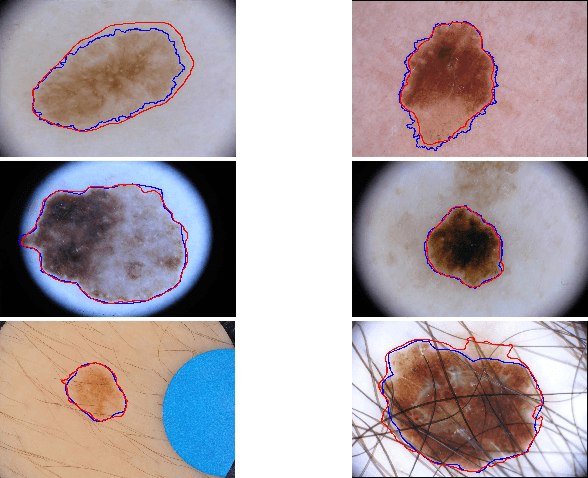
With a large influx of dermoscopy images and a growing shortage of dermatologists, automatic dermoscopic image analysis plays an essential role in skin cancer diagnosis. In this paper, a new deep fully convolutional neural network (FCNN) is proposed to automatically segment melanoma out of skin images by end-to-end learning with only pixels and labels as inputs. Our proposed FCNN is capable of using both local and global information to segment melanoma by adopting skipping layers. The public benchmark database consisting of 150 validation images, 600 test images and 2000 training images in the melanoma detection challenge 2017 at International Symposium Biomedical Imaging 2017 is used to test the performance of our algorithm. All large size images (for example, $4000\times 6000$ pixels) are reduced to much smaller images with $384\times 384$ pixels (more than 10 times smaller). We got and submitted preliminary results to the challenge without any pre or post processing. The performance of our proposed method could be further improved by data augmentation and by avoiding image size reduction.