 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNot All Layers Need Tuning: Selective Layer Restoration Recovers Diversity
Feb 06, 2026Post-training improves instruction-following and helpfulness of large language models (LLMs) but often reduces generation diversity, which leads to repetitive outputs in open-ended settings, a phenomenon known as mode collapse. Motivated by evidence that LLM layers play distinct functional roles, we hypothesize that mode collapse can be localized to specific layers and that restoring a carefully chosen range of layers to their pre-trained weights can recover diversity while maintaining high output quality. To validate this hypothesis and decide which layers to restore, we design a proxy task -- Constrained Random Character(CRC) -- with an explicit validity set and a natural diversity objective. Results on CRC reveal a clear diversity-validity trade-off across restoration ranges and identify configurations that increase diversity with minimal quality loss. Based on these findings, we propose Selective Layer Restoration (SLR), a training-free method that restores selected layers in a post-trained model to their pre-trained weights, yielding a hybrid model with the same architecture and parameter count, incurring no additional inference cost. Across three different tasks (creative writing, open-ended question answering, and multi-step reasoning) and three different model families (Llama, Qwen, and Gemma), we find SLR can consistently and substantially improve output diversity while maintaining high output quality.
ERNIE 5.0 Technical Report
Feb 04, 2026In this report, we introduce ERNIE 5.0, a natively autoregressive foundation model desinged for unified multimodal understanding and generation across text, image, video, and audio. All modalities are trained from scratch under a unified next-group-of-tokens prediction objective, based on an ultra-sparse mixture-of-experts (MoE) architecture with modality-agnostic expert routing. To address practical challenges in large-scale deployment under diverse resource constraints, ERNIE 5.0 adopts a novel elastic training paradigm. Within a single pre-training run, the model learns a family of sub-models with varying depths, expert capacities, and routing sparsity, enabling flexible trade-offs among performance, model size, and inference latency in memory- or time-constrained scenarios. Moreover, we systematically address the challenges of scaling reinforcement learning to unified foundation models, thereby guaranteeing efficient and stable post-training under ultra-sparse MoE architectures and diverse multimodal settings. Extensive experiments demonstrate that ERNIE 5.0 achieves strong and balanced performance across multiple modalities. To the best of our knowledge, among publicly disclosed models, ERNIE 5.0 represents the first production-scale realization of a trillion-parameter unified autoregressive model that supports both multimodal understanding and generation. To facilitate further research, we present detailed visualizations of modality-agnostic expert routing in the unified model, alongside comprehensive empirical analysis of elastic training, aiming to offer profound insights to the community.
Audio ControlNet for Fine-Grained Audio Generation and Editing
Feb 04, 2026We study the fine-grained text-to-audio (T2A) generation task. While recent models can synthesize high-quality audio from text descriptions, they often lack precise control over attributes such as loudness, pitch, and sound events. Unlike prior approaches that retrain models for specific control types, we propose to train ControlNet models on top of pre-trained T2A backbones to achieve controllable generation over loudness, pitch, and event roll. We introduce two designs, T2A-ControlNet and T2A-Adapter, and show that the T2A-Adapter model offers a more efficient structure with strong control ability. With only 38M additional parameters, T2A-Adapter achieves state-of-the-art performance on the AudioSet-Strong in both event-level and segment-level F1 scores. We further extend this framework to audio editing, proposing T2A-Editor for removing and inserting audio events at time locations specified by instructions. Models, code, dataset pipelines, and benchmarks will be released to support future research on controllable audio generation and editing.
HY3D-Bench: Generation of 3D Assets
Feb 03, 2026While recent advances in neural representations and generative models have revolutionized 3D content creation, the field remains constrained by significant data processing bottlenecks. To address this, we introduce HY3D-Bench, an open-source ecosystem designed to establish a unified, high-quality foundation for 3D generation. Our contributions are threefold: (1) We curate a library of 250k high-fidelity 3D objects distilled from large-scale repositories, employing a rigorous pipeline to deliver training-ready artifacts, including watertight meshes and multi-view renderings; (2) We introduce structured part-level decomposition, providing the granularity essential for fine-grained perception and controllable editing; and (3) We bridge real-world distribution gaps via a scalable AIGC synthesis pipeline, contributing 125k synthetic assets to enhance diversity in long-tail categories. Validated empirically through the training of Hunyuan3D-2.1-Small, HY3D-Bench democratizes access to robust data resources, aiming to catalyze innovation across 3D perception, robotics, and digital content creation.
ToPT: Task-Oriented Prompt Tuning for Urban Region Representation Learning
Feb 02, 2026Learning effective region embeddings from heterogeneous urban data underpins key urban computing tasks (e.g., crime prediction, resource allocation). However, prevailing two-stage methods yield task-agnostic representations, decoupling them from downstream objectives. Recent prompt-based approaches attempt to fix this but introduce two challenges: they often lack explicit spatial priors, causing spatially incoherent inter-region modeling, and they lack robust mechanisms for explicit task-semantic alignment. We propose ToPT, a two-stage framework that delivers spatially consistent fusion and explicit task alignment. ToPT consists of two modules: spatial-aware region embedding learning (SREL) and task-aware prompting for region embeddings (Prompt4RE). SREL employs a Graphormer-based fusion module that injects spatial priors-distance and regional centrality-as learnable attention biases to capture coherent, interpretable inter-region interactions. Prompt4RE performs task-oriented prompting: a frozen multimodal large language model (MLLM) processes task-specific templates to obtain semantic vectors, which are aligned with region embeddings via multi-head cross-attention for stable task conditioning. Experiments across multiple tasks and cities show state-of-the-art performance, with improvements of up to 64.2\%, validating the necessity and complementarity of spatial priors and prompt-region alignment. The code is available at https://github.com/townSeven/Prompt4RE.git.
Improving Day-Ahead Grid Carbon Intensity Forecasting by Joint Modeling of Local-Temporal and Cross-Variable Dependencies Across Different Frequencies
Jan 10, 2026Accurate forecasting of the grid carbon intensity factor (CIF) is critical for enabling demand-side management and reducing emissions in modern electricity systems. Leveraging multiple interrelated time series, CIF prediction is typically formulated as a multivariate time series forecasting problem. Despite advances in deep learning-based methods, it remains challenging to capture the fine-grained local-temporal dependencies, dynamic higher-order cross-variable dependencies, and complex multi-frequency patterns for CIF forecasting. To address these issues, we propose a novel model that integrates two parallel modules: 1) one enhances the extraction of local-temporal dependencies under multi-frequency by applying multiple wavelet-based convolutional kernels to overlapping patches of varying lengths; 2) the other captures dynamic cross-variable dependencies under multi-frequency to model how inter-variable relationships evolve across the time-frequency domain. Evaluations on four representative electricity markets from Australia, featuring varying levels of renewable penetration, demonstrate that the proposed method outperforms the state-of-the-art models. An ablation study further validates the complementary benefits of the two proposed modules. Designed with built-in interpretability, the proposed model also enables better understanding of its predictive behavior, as shown in a case study where it adaptively shifts attention to relevant variables and time intervals during a disruptive event.
CLARITY: Contextual Linguistic Adaptation and Accent Retrieval for Dual-Bias Mitigation in Text-to-Speech Generation
Nov 14, 2025Instruction-guided text-to-speech (TTS) research has reached a maturity level where excellent speech generation quality is possible on demand, yet two coupled biases persist: accent bias, where models default to dominant phonetic patterns, and linguistic bias, where dialect-specific lexical and cultural cues are ignored. These biases are interdependent, as authentic accent generation requires both accent fidelity and localized text. We present Contextual Linguistic Adaptation and Retrieval for Inclusive TTS sYnthesis (CLARITY), a backbone-agnostic framework that addresses these biases through dual-signal optimization: (i) contextual linguistic adaptation that localizes input text to the target dialect, and (ii) retrieval-augmented accent prompting (RAAP) that supplies accent-consistent speech prompts. Across twelve English accents, CLARITY improves accent accuracy and fairness while maintaining strong perceptual quality.
MoETTA: Test-Time Adaptation Under Mixed Distribution Shifts with MoE-LayerNorm
Nov 14, 2025Test-Time adaptation (TTA) has proven effective in mitigating performance drops under single-domain distribution shifts by updating model parameters during inference. However, real-world deployments often involve mixed distribution shifts, where test samples are affected by diverse and potentially conflicting domain factors, posing significant challenges even for SOTA TTA methods. A key limitation in existing approaches is their reliance on a unified adaptation path, which fails to account for the fact that optimal gradient directions can vary significantly across different domains. Moreover, current benchmarks focus only on synthetic or homogeneous shifts, failing to capture the complexity of real-world heterogeneous mixed distribution shifts. To address this, we propose MoETTA, a novel entropy-based TTA framework that integrates the Mixture-of-Experts (MoE) architecture. Rather than enforcing a single parameter update rule for all test samples, MoETTA introduces a set of structurally decoupled experts, enabling adaptation along diverse gradient directions. This design allows the model to better accommodate heterogeneous shifts through flexible and disentangled parameter updates. To simulate realistic deployment conditions, we introduce two new benchmarks: potpourri and potpourri+. While classical settings focus solely on synthetic corruptions, potpourri encompasses a broader range of domain shifts--including natural, artistic, and adversarial distortions--capturing more realistic deployment challenges. Additionally, potpourri+ further includes source-domain samples to evaluate robustness against catastrophic forgetting. Extensive experiments across three mixed distribution shifts settings show that MoETTA consistently outperforms strong baselines, establishing SOTA performance and highlighting the benefit of modeling multiple adaptation directions via expert-level diversity.
Semantic-VAE: Semantic-Alignment Latent Representation for Better Speech Synthesis
Sep 26, 2025While mel-spectrograms have been widely utilized as intermediate representations in zero-shot text-to-speech (TTS), their inherent redundancy leads to inefficiency in learning text-speech alignment. Compact VAE-based latent representations have recently emerged as a stronger alternative, but they also face a fundamental optimization dilemma: higher-dimensional latent spaces improve reconstruction quality and speaker similarity, but degrade intelligibility, while lower-dimensional spaces improve intelligibility at the expense of reconstruction fidelity. To overcome this dilemma, we propose Semantic-VAE, a novel VAE framework that utilizes semantic alignment regularization in the latent space. This design alleviates the reconstruction-generation trade-off by capturing semantic structure in high-dimensional latent representations. Extensive experiments demonstrate that Semantic-VAE significantly improves synthesis quality and training efficiency. When integrated into F5-TTS, our method achieves 2.10% WER and 0.64 speaker similarity on LibriSpeech-PC, outperforming mel-based systems (2.23%, 0.60) and vanilla acoustic VAE baselines (2.65%, 0.59). We also release the code and models to facilitate further research.
MANZANO: A Simple and Scalable Unified Multimodal Model with a Hybrid Vision Tokenizer
Sep 19, 2025
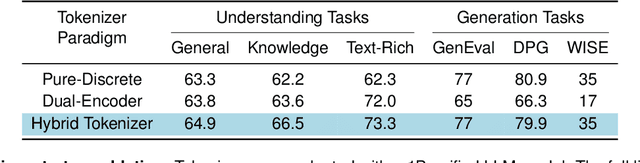
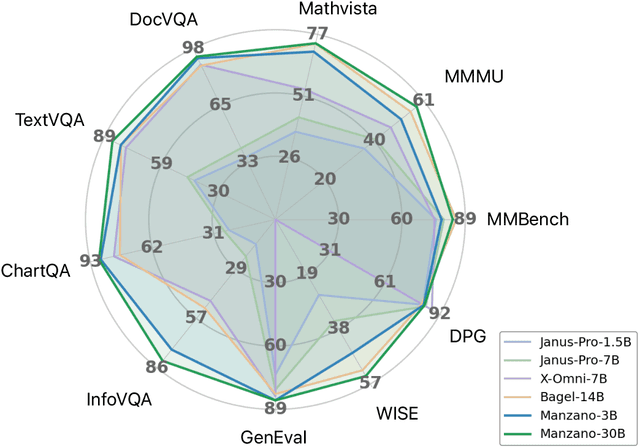
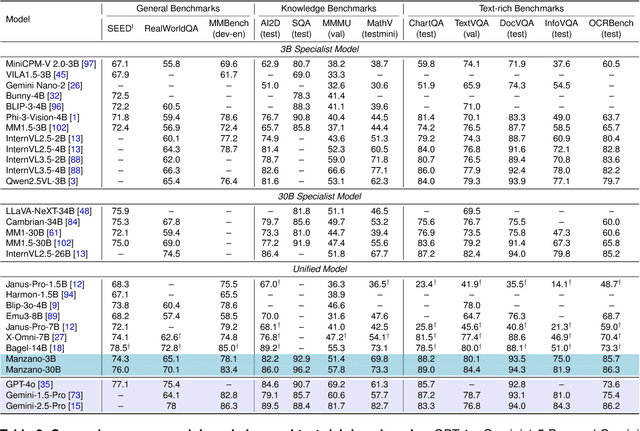
Unified multimodal Large Language Models (LLMs) that can both understand and generate visual content hold immense potential. However, existing open-source models often suffer from a performance trade-off between these capabilities. We present Manzano, a simple and scalable unified framework that substantially reduces this tension by coupling a hybrid image tokenizer with a well-curated training recipe. A single shared vision encoder feeds two lightweight adapters that produce continuous embeddings for image-to-text understanding and discrete tokens for text-to-image generation within a common semantic space. A unified autoregressive LLM predicts high-level semantics in the form of text and image tokens, with an auxiliary diffusion decoder subsequently translating the image tokens into pixels. The architecture, together with a unified training recipe over understanding and generation data, enables scalable joint learning of both capabilities. Manzano achieves state-of-the-art results among unified models, and is competitive with specialist models, particularly on text-rich evaluation. Our studies show minimal task conflicts and consistent gains from scaling model size, validating our design choice of a hybrid tokenizer.