 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOWL: A Large Language Model for IT Operations
Sep 17, 2023



With the rapid development of IT operations, it has become increasingly crucial to efficiently manage and analyze large volumes of data for practical applications. The techniques of Natural Language Processing (NLP) have shown remarkable capabilities for various tasks, including named entity recognition, machine translation and dialogue systems. Recently, Large Language Models (LLMs) have achieved significant improvements across various NLP downstream tasks. However, there is a lack of specialized LLMs for IT operations. In this paper, we introduce the OWL, a large language model trained on our collected OWL-Instruct dataset with a wide range of IT-related information, where the mixture-of-adapter strategy is proposed to improve the parameter-efficient tuning across different domains or tasks. Furthermore, we evaluate the performance of our OWL on the OWL-Bench established by us and open IT-related benchmarks. OWL demonstrates superior performance results on IT tasks, which outperforms existing models by significant margins. Moreover, we hope that the findings of our work will provide more insights to revolutionize the techniques of IT operations with specialized LLMs.
Rethinking Cross-Domain Pedestrian Detection: A Background-Focused Distribution Alignment Framework for Instance-Free One-Stage Detectors
Sep 15, 2023



Cross-domain pedestrian detection aims to generalize pedestrian detectors from one label-rich domain to another label-scarce domain, which is crucial for various real-world applications. Most recent works focus on domain alignment to train domain-adaptive detectors either at the instance level or image level. From a practical point of view, one-stage detectors are faster. Therefore, we concentrate on designing a cross-domain algorithm for rapid one-stage detectors that lacks instance-level proposals and can only perform image-level feature alignment. However, pure image-level feature alignment causes the foreground-background misalignment issue to arise, i.e., the foreground features in the source domain image are falsely aligned with background features in the target domain image. To address this issue, we systematically analyze the importance of foreground and background in image-level cross-domain alignment, and learn that background plays a more critical role in image-level cross-domain alignment. Therefore, we focus on cross-domain background feature alignment while minimizing the influence of foreground features on the cross-domain alignment stage. This paper proposes a novel framework, namely, background-focused distribution alignment (BFDA), to train domain adaptive onestage pedestrian detectors. Specifically, BFDA first decouples the background features from the whole image feature maps and then aligns them via a novel long-short-range discriminator.
* This paper published on IEEE Transactions on Image Processing on August 2023.See https://ieeexplore.ieee.org/document/10231122
Norm Tweaking: High-performance Low-bit Quantization of Large Language Models
Sep 06, 2023As the size of large language models (LLMs) continues to grow, model compression without sacrificing accuracy has become a crucial challenge for deployment. While some quantization methods, such as GPTQ, have made progress in achieving acceptable 4-bit weight-only quantization, attempts at lower bit quantization often result in severe performance degradation. In this paper, we introduce a technique called norm tweaking, which can be used as a plugin in current PTQ methods to achieve high precision while being cost-efficient. Our approach is inspired by the observation that rectifying the quantized activation distribution to match its float counterpart can readily restore accuracy for LLMs. To achieve this, we carefully design a tweaking strategy that includes calibration data generation and channel-wise distance constraint to update the weights of normalization layers for better generalization. We conduct extensive experiments on various datasets using several open-sourced LLMs. Our method demonstrates significant improvements in both weight-only quantization and joint quantization of weights and activations, surpassing existing PTQ methods. On GLM-130B and OPT-66B, our method even achieves the same level of accuracy at 2-bit quantization as their float ones. Our simple and effective approach makes it more practical for real-world applications.
FPTQ: Fine-grained Post-Training Quantization for Large Language Models
Aug 30, 2023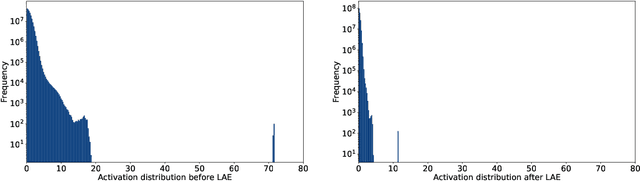



In the era of large-scale language models, the substantial parameter size poses significant challenges for deployment. Being a prevalent compression technique, quantization has emerged as the mainstream practice to tackle this issue, which is mainly centered on two recipes W8A8 and W4A16 (i.e. weights and activations in such bit widths). In this study, we propose a novel W4A8 post-training quantization method for the available open-sourced LLMs, which combines the advantages of both two recipes. Therefore, we can leverage the benefit in the I/O utilization of 4-bit weight quantization and the acceleration due to 8-bit matrix computation. Nevertheless, the W4A8 faces notorious performance degradation. As a remedy, we involve layerwise activation quantization strategies which feature a novel logarithmic equalization for most intractable layers, and we combine them with fine-grained weight quantization. Without whistles and bells, we eliminate the necessity for further fine-tuning and obtain the state-of-the-art W4A8 quantized performance on BLOOM, LLaMA, and LLaMA-2 on standard benchmarks. We confirm that the W4A8 quantization is achievable for the deployment of large language models, fostering their wide-spreading real-world applications.
ControlCom: Controllable Image Composition using Diffusion Model
Aug 19, 2023



Image composition targets at synthesizing a realistic composite image from a pair of foreground and background images. Recently, generative composition methods are built on large pretrained diffusion models to generate composite images, considering their great potential in image generation. However, they suffer from lack of controllability on foreground attributes and poor preservation of foreground identity. To address these challenges, we propose a controllable image composition method that unifies four tasks in one diffusion model: image blending, image harmonization, view synthesis, and generative composition. Meanwhile, we design a self-supervised training framework coupled with a tailored pipeline of training data preparation. Moreover, we propose a local enhancement module to enhance the foreground details in the diffusion model, improving the foreground fidelity of composite images. The proposed method is evaluated on both public benchmark and real-world data, which demonstrates that our method can generate more faithful and controllable composite images than existing approaches. The code and model will be available at https://github.com/bcmi/ControlCom-Image-Composition.
Foreground Object Search by Distilling Composite Image Feature
Aug 09, 2023Foreground object search (FOS) aims to find compatible foreground objects for a given background image, producing realistic composite image. We observe that competitive retrieval performance could be achieved by using a discriminator to predict the compatibility of composite image, but this approach has unaffordable time cost. To this end, we propose a novel FOS method via distilling composite feature (DiscoFOS). Specifically, the abovementioned discriminator serves as teacher network. The student network employs two encoders to extract foreground feature and background feature. Their interaction output is enforced to match the composite image feature from the teacher network. Additionally, previous works did not release their datasets, so we contribute two datasets for FOS task: S-FOSD dataset with synthetic composite images and R-FOSD dataset with real composite images. Extensive experiments on our two datasets demonstrate the superiority of the proposed method over previous approaches. The dataset and code are available at https://github.com/bcmi/Foreground-Object-Search-Dataset-FOSD.
ZRIGF: An Innovative Multimodal Framework for Zero-Resource Image-Grounded Dialogue Generation
Aug 02, 2023Image-grounded dialogue systems benefit greatly from integrating visual information, resulting in high-quality response generation. However, current models struggle to effectively utilize such information in zero-resource scenarios, mainly due to the disparity between image and text modalities. To overcome this challenge, we propose an innovative multimodal framework, called ZRIGF, which assimilates image-grounded information for dialogue generation in zero-resource situations. ZRIGF implements a two-stage learning strategy, comprising contrastive pre-training and generative pre-training. Contrastive pre-training includes a text-image matching module that maps images and texts into a unified encoded vector space, along with a text-assisted masked image modeling module that preserves pre-training visual features and fosters further multimodal feature alignment. Generative pre-training employs a multimodal fusion module and an information transfer module to produce insightful responses based on harmonized multimodal representations. Comprehensive experiments conducted on both text-based and image-grounded dialogue datasets demonstrate ZRIGF's efficacy in generating contextually pertinent and informative responses. Furthermore, we adopt a fully zero-resource scenario in the image-grounded dialogue dataset to demonstrate our framework's robust generalization capabilities in novel domains. The code is available at https://github.com/zhangbo-nlp/ZRIGF.
Large Language Models for Supply Chain Optimization
Jul 13, 2023Supply chain operations traditionally involve a variety of complex decision making problems. Over the last few decades, supply chains greatly benefited from advances in computation, which allowed the transition from manual processing to automation and cost-effective optimization. Nonetheless, business operators still need to spend substantial efforts in explaining and interpreting the optimization outcomes to stakeholders. Motivated by the recent advances in Large Language Models (LLMs), we study how this disruptive technology can help bridge the gap between supply chain automation and human comprehension and trust thereof. We design OptiGuide -- a framework that accepts as input queries in plain text, and outputs insights about the underlying optimization outcomes. Our framework does not forgo the state-of-the-art combinatorial optimization technology, but rather leverages it to quantitatively answer what-if scenarios (e.g., how would the cost change if we used supplier B instead of supplier A for a given demand?). Importantly, our design does not require sending proprietary data over to LLMs, which can be a privacy concern in some circumstances. We demonstrate the effectiveness of our framework on a real server placement scenario within Microsoft's cloud supply chain. Along the way, we develop a general evaluation benchmark, which can be used to evaluate the accuracy of the LLM output in other scenarios.
Physically Realizable Natural-Looking Clothing Textures Evade Person Detectors via 3D Modeling
Jul 04, 2023



Recent works have proposed to craft adversarial clothes for evading person detectors, while they are either only effective at limited viewing angles or very conspicuous to humans. We aim to craft adversarial texture for clothes based on 3D modeling, an idea that has been used to craft rigid adversarial objects such as a 3D-printed turtle. Unlike rigid objects, humans and clothes are non-rigid, leading to difficulties in physical realization. In order to craft natural-looking adversarial clothes that can evade person detectors at multiple viewing angles, we propose adversarial camouflage textures (AdvCaT) that resemble one kind of the typical textures of daily clothes, camouflage textures. We leverage the Voronoi diagram and Gumbel-softmax trick to parameterize the camouflage textures and optimize the parameters via 3D modeling. Moreover, we propose an efficient augmentation pipeline on 3D meshes combining topologically plausible projection (TopoProj) and Thin Plate Spline (TPS) to narrow the gap between digital and real-world objects. We printed the developed 3D texture pieces on fabric materials and tailored them into T-shirts and trousers. Experiments show high attack success rates of these clothes against multiple detectors.
Cross-Element Combinatorial Selection for Multi-Element Creative in Display Advertising
Jul 04, 2023



The effectiveness of ad creatives is greatly influenced by their visual appearance. Advertising platforms can generate ad creatives with different appearances by combining creative elements provided by advertisers. However, with the increasing number of ad creative elements, it becomes challenging to select a suitable combination from the countless possibilities. The industry's mainstream approach is to select individual creative elements independently, which often overlooks the importance of interaction between creative elements during the modeling process. In response, this paper proposes a Cross-Element Combinatorial Selection framework for multiple creative elements, termed CECS. In the encoder process, a cross-element interaction is adopted to dynamically adjust the expression of a single creative element based on the current candidate creatives. In the decoder process, the creative combination problem is transformed into a cascade selection problem of multiple creative elements. A pointer mechanism with a cascade design is used to model the associations among candidates. Comprehensive experiments on real-world datasets show that CECS achieved the SOTA score on offline metrics. Moreover, the CECS algorithm has been deployed in our industrial application, resulting in a significant 6.02% CTR and 10.37% GMV lift, which is beneficial to the business.