 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStructure-Preserving Nonlinear Sufficient Dimension Reduction for Tensors
Dec 23, 2025We introduce two nonlinear sufficient dimension reduction methods for regressions with tensor-valued predictors. Our goal is two-fold: the first is to preserve the tensor structure when performing dimension reduction, particularly the meaning of the tensor modes, for improved interpretation; the second is to substantially reduce the number of parameters in dimension reduction, thereby achieving model parsimony and enhancing estimation accuracy. Our two tensor dimension reduction methods echo the two commonly used tensor decomposition mechanisms: one is the Tucker decomposition, which reduces a larger tensor to a smaller one; the other is the CP-decomposition, which represents an arbitrary tensor as a sequence of rank-one tensors. We developed the Fisher consistency of our methods at the population level and established their consistency and convergence rates. Both methods are easy to implement numerically: the Tucker-form can be implemented through a sequence of least-squares steps, and the CP-form can be implemented through a sequence of singular value decompositions. We investigated the finite-sample performance of our methods and showed substantial improvement in accuracy over existing methods in simulations and two data applications.
MMhops-R1: Multimodal Multi-hop Reasoning
Dec 16, 2025


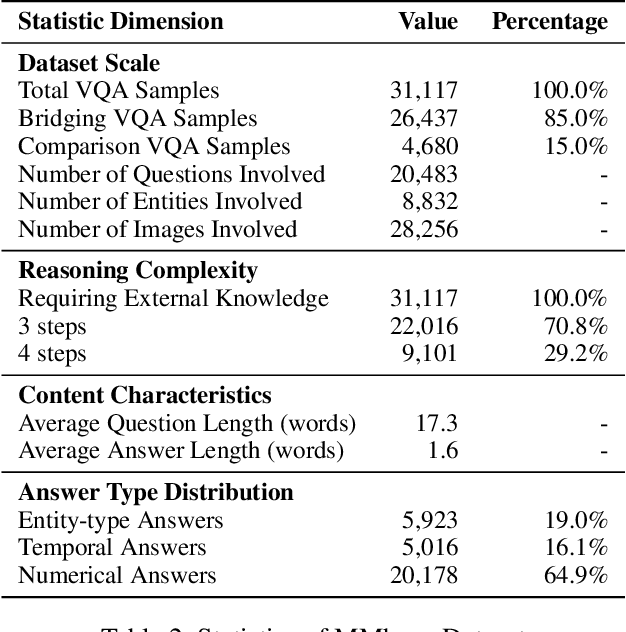
The ability to perform multi-modal multi-hop reasoning by iteratively integrating information across various modalities and external knowledge is critical for addressing complex real-world challenges. However, existing Multi-modal Large Language Models (MLLMs) are predominantly limited to single-step reasoning, as existing benchmarks lack the complexity needed to evaluate and drive multi-hop abilities. To bridge this gap, we introduce MMhops, a novel, large-scale benchmark designed to systematically evaluate and foster multi-modal multi-hop reasoning. MMhops dataset comprises two challenging task formats, Bridging and Comparison, which necessitate that models dynamically construct complex reasoning chains by integrating external knowledge. To tackle the challenges posed by MMhops, we propose MMhops-R1, a novel multi-modal Retrieval-Augmented Generation (mRAG) framework for dynamic reasoning. Our framework utilizes reinforcement learning to optimize the model for autonomously planning reasoning paths, formulating targeted queries, and synthesizing multi-level information. Comprehensive experiments demonstrate that MMhops-R1 significantly outperforms strong baselines on MMhops, highlighting that dynamic planning and multi-modal knowledge integration are crucial for complex reasoning. Moreover, MMhops-R1 demonstrates strong generalization to tasks requiring fixed-hop reasoning, underscoring the robustness of our dynamic planning approach. In conclusion, our work contributes a challenging new benchmark and a powerful baseline model, and we will release the associated code, data, and weights to catalyze future research in this critical area.
OBJVanish: Physically Realizable Text-to-3D Adv. Generation of LiDAR-Invisible Objects
Oct 08, 2025LiDAR-based 3D object detectors are fundamental to autonomous driving, where failing to detect objects poses severe safety risks. Developing effective 3D adversarial attacks is essential for thoroughly testing these detection systems and exposing their vulnerabilities before real-world deployment. However, existing adversarial attacks that add optimized perturbations to 3D points have two critical limitations: they rarely cause complete object disappearance and prove difficult to implement in physical environments. We introduce the text-to-3D adversarial generation method, a novel approach enabling physically realizable attacks that can generate 3D models of objects truly invisible to LiDAR detectors and be easily realized in the real world. Specifically, we present the first empirical study that systematically investigates the factors influencing detection vulnerability by manipulating the topology, connectivity, and intensity of individual pedestrian 3D models and combining pedestrians with multiple objects within the CARLA simulation environment. Building on the insights, we propose the physically-informed text-to-3D adversarial generation (Phy3DAdvGen) that systematically optimizes text prompts by iteratively refining verbs, objects, and poses to produce LiDAR-invisible pedestrians. To ensure physical realizability, we construct a comprehensive object pool containing 13 3D models of real objects and constrain Phy3DAdvGen to generate 3D objects based on combinations of objects in this set. Extensive experiments demonstrate that our approach can generate 3D pedestrians that evade six state-of-the-art (SOTA) LiDAR 3D detectors in both CARLA simulation and physical environments, thereby highlighting vulnerabilities in safety-critical applications.
Large Language Models (LLMs) for Electronic Design Automation (EDA)
Aug 27, 2025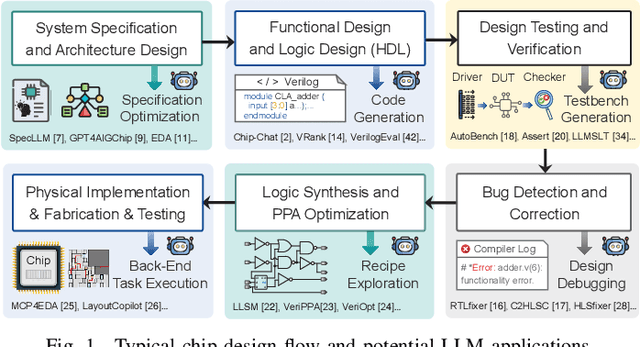

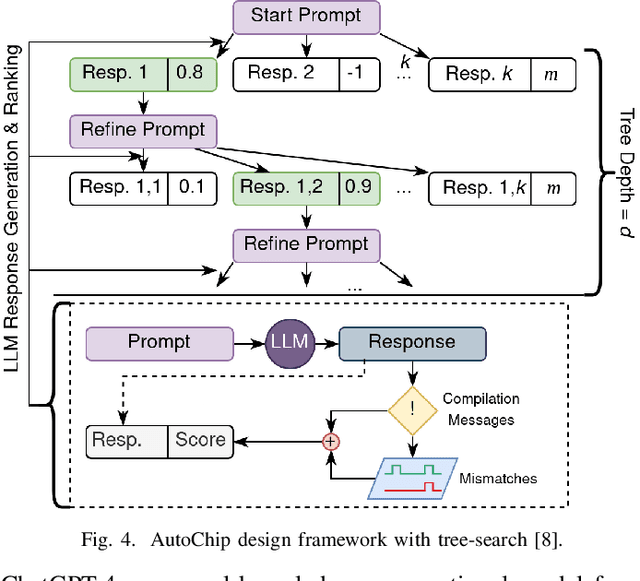
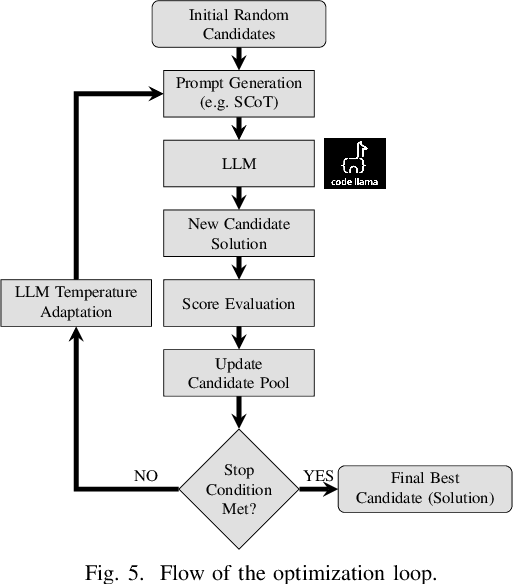
With the growing complexity of modern integrated circuits, hardware engineers are required to devote more effort to the full design-to-manufacturing workflow. This workflow involves numerous iterations, making it both labor-intensive and error-prone. Therefore, there is an urgent demand for more efficient Electronic Design Automation (EDA) solutions to accelerate hardware development. Recently, large language models (LLMs) have shown remarkable advancements in contextual comprehension, logical reasoning, and generative capabilities. Since hardware designs and intermediate scripts can be represented as text, integrating LLM for EDA offers a promising opportunity to simplify and even automate the entire workflow. Accordingly, this paper provides a comprehensive overview of incorporating LLMs into EDA, with emphasis on their capabilities, limitations, and future opportunities. Three case studies, along with their outlook, are introduced to demonstrate the capabilities of LLMs in hardware design, testing, and optimization. Finally, future directions and challenges are highlighted to further explore the potential of LLMs in shaping the next-generation EDA, providing valuable insights for researchers interested in leveraging advanced AI technologies for EDA.
EEvAct: Early Event-Based Action Recognition with High-Rate Two-Stream Spiking Neural Networks
Jul 10, 2025Recognizing human activities early is crucial for the safety and responsiveness of human-robot and human-machine interfaces. Due to their high temporal resolution and low latency, event-based vision sensors are a perfect match for this early recognition demand. However, most existing processing approaches accumulate events to low-rate frames or space-time voxels which limits the early prediction capabilities. In contrast, spiking neural networks (SNNs) can process the events at a high-rate for early predictions, but most works still fall short on final accuracy. In this work, we introduce a high-rate two-stream SNN which closes this gap by outperforming previous work by 2% in final accuracy on the large-scale THU EACT-50 dataset. We benchmark the SNNs within a novel early event-based recognition framework by reporting Top-1 and Top-5 recognition scores for growing observation time. Finally, we exemplify the impact of these methods on a real-world task of early action triggering for human motion capture in sports.
Pay Less Attention to Deceptive Artifacts: Robust Detection of Compressed Deepfakes on Online Social Networks
Jun 25, 2025



With the rapid advancement of deep learning, particularly through generative adversarial networks (GANs) and diffusion models (DMs), AI-generated images, or ``deepfakes", have become nearly indistinguishable from real ones. These images are widely shared across Online Social Networks (OSNs), raising concerns about their misuse. Existing deepfake detection methods overlook the ``block effects" introduced by compression in OSNs, which obscure deepfake artifacts, and primarily focus on raw images, rarely encountered in real-world scenarios. To address these challenges, we propose PLADA (Pay Less Attention to Deceptive Artifacts), a novel framework designed to tackle the lack of paired data and the ineffective use of compressed images. PLADA consists of two core modules: Block Effect Eraser (B2E), which uses a dual-stage attention mechanism to handle block effects, and Open Data Aggregation (ODA), which processes both paired and unpaired data to improve detection. Extensive experiments across 26 datasets demonstrate that PLADA achieves a remarkable balance in deepfake detection, outperforming SoTA methods in detecting deepfakes on OSNs, even with limited paired data and compression. More importantly, this work introduces the ``block effect" as a critical factor in deepfake detection, providing a robust solution for open-world scenarios. Our code is available at https://github.com/ManyiLee/PLADA.
A Comprehensive Survey on Video Scene Parsing:Advances, Challenges, and Prospects
Jun 16, 2025



Video Scene Parsing (VSP) has emerged as a cornerstone in computer vision, facilitating the simultaneous segmentation, recognition, and tracking of diverse visual entities in dynamic scenes. In this survey, we present a holistic review of recent advances in VSP, covering a wide array of vision tasks, including Video Semantic Segmentation (VSS), Video Instance Segmentation (VIS), Video Panoptic Segmentation (VPS), as well as Video Tracking and Segmentation (VTS), and Open-Vocabulary Video Segmentation (OVVS). We systematically analyze the evolution from traditional hand-crafted features to modern deep learning paradigms -- spanning from fully convolutional networks to the latest transformer-based architectures -- and assess their effectiveness in capturing both local and global temporal contexts. Furthermore, our review critically discusses the technical challenges, ranging from maintaining temporal consistency to handling complex scene dynamics, and offers a comprehensive comparative study of datasets and evaluation metrics that have shaped current benchmarking standards. By distilling the key contributions and shortcomings of state-of-the-art methodologies, this survey highlights emerging trends and prospective research directions that promise to further elevate the robustness and adaptability of VSP in real-world applications.
Integer Binary-Range Alignment Neuron for Spiking Neural Networks
Jun 06, 2025Spiking Neural Networks (SNNs) are noted for their brain-like computation and energy efficiency, but their performance lags behind Artificial Neural Networks (ANNs) in tasks like image classification and object detection due to the limited representational capacity. To address this, we propose a novel spiking neuron, Integer Binary-Range Alignment Leaky Integrate-and-Fire to exponentially expand the information expression capacity of spiking neurons with only a slight energy increase. This is achieved through Integer Binary Leaky Integrate-and-Fire and range alignment strategy. The Integer Binary Leaky Integrate-and-Fire allows integer value activation during training and maintains spike-driven dynamics with binary conversion expands virtual timesteps during inference. The range alignment strategy is designed to solve the spike activation limitation problem where neurons fail to activate high integer values. Experiments show our method outperforms previous SNNs, achieving 74.19% accuracy on ImageNet and 66.2% mAP@50 and 49.1% mAP@50:95 on COCO, surpassing previous bests with the same architecture by +3.45% and +1.6% and +1.8%, respectively. Notably, our SNNs match or exceed ANNs' performance with the same architecture, and the energy efficiency is improved by 6.3${\times}$.
An Empirical Study of Federated Prompt Learning for Vision Language Model
May 29, 2025The Vision Language Model (VLM) excels in aligning vision and language representations, and prompt learning has emerged as a key technique for adapting such models to downstream tasks. However, the application of prompt learning with VLM in federated learning (\fl{}) scenarios remains underexplored. This paper systematically investigates the behavioral differences between language prompt learning (LPT) and vision prompt learning (VPT) under data heterogeneity challenges, including label skew and domain shift. We conduct extensive experiments to evaluate the impact of various \fl{} and prompt configurations, such as client scale, aggregation strategies, and prompt length, to assess the robustness of Federated Prompt Learning (FPL). Furthermore, we explore strategies for enhancing prompt learning in complex scenarios where label skew and domain shift coexist, including leveraging both prompt types when computational resources allow. Our findings offer practical insights into optimizing prompt learning in federated settings, contributing to the broader deployment of VLMs in privacy-preserving environments.
OmniResponse: Online Multimodal Conversational Response Generation in Dyadic Interactions
May 27, 2025



In this paper, we introduce Online Multimodal Conversational Response Generation (OMCRG), a novel task that aims to online generate synchronized verbal and non-verbal listener feedback, conditioned on the speaker's multimodal input. OMCRG reflects natural dyadic interactions and poses new challenges in achieving synchronization between the generated audio and facial responses of the listener. To address these challenges, we innovatively introduce text as an intermediate modality to bridge the audio and facial responses. We hence propose OmniResponse, a Multimodal Large Language Model (MLLM) that autoregressively generates high-quality multi-modal listener responses. OmniResponse leverages a pretrained LLM enhanced with two novel components: Chrono-Text, which temporally anchors generated text tokens, and TempoVoice, a controllable online TTS module that produces speech synchronized with facial reactions. To support further OMCRG research, we present ResponseNet, a new dataset comprising 696 high-quality dyadic interactions featuring synchronized split-screen videos, multichannel audio, transcripts, and facial behavior annotations. Comprehensive evaluations conducted on ResponseNet demonstrate that OmniResponse significantly outperforms baseline models in terms of semantic speech content, audio-visual synchronization, and generation quality.