 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring the Agentic Frontier of Verilog Code Generation
Mar 19, 2026Large language models (LLMs) have made rapid advancements in code generation for popular languages such as Python and C++. Many of these recent gains can be attributed to the use of ``agents'' that wrap domain-relevant tools alongside LLMs. Hardware design languages such as Verilog have also seen improved code generation in recent years, but the impact of agentic frameworks on Verilog code generation tasks remains unclear. In this work, we present the first systematic evaluation of agentic LLMs for Verilog generation, using the recently introduced CVDP benchmark. We also introduce several open-source hardware design agent harnesses, providing a model-agnostic baseline for future work. Through controlled experiments across frontier models, we study how structured prompting and tool design affect performance, analyze agent failure modes and tool usage patterns, compare open-source and closed-source models, and provide qualitative examples of successful and failed agent runs. Our results show that naive agentic wrapping around frontier models can degrade performance (relative to standard forward passes with optimized prompts), but that structured harnesses meaningfully match and in some cases exceed non-agentic baselines. We find that the performance gap between open and closed source models is driven by both higher crash rates and weaker tool output interpretation. Our exploration illuminates the path towards designing special-purpose agents for verilog generation in the future.
GUIDE: GenAI Units In Digital Design Education
Mar 18, 2026GenAI Units In Digital Design Education (GUIDE) is an open courseware repository with runnable Google Colab labs and other materials. We describe the repository's architecture and educational approach based on standardized teaching units comprising slides, short videos, runnable labs, and related papers. This organization enables consistency for both the students' learning experience and the reuse and grading by instructors. We demonstrate GUIDE in practice with three representative units: VeriThoughts for reasoning and formal-verification-backed RTL generation, enhanced LLM-aided testbench generation, and LLMPirate for IP Piracy. We also provide details for four example course instances (GUIDE4ChipDesign, Build your ASIC, GUIDE4HardwareSecurity, and Hardware Design) that assemble GUIDE units into full semester offerings, learning outcomes, and capstone projects, all based on proven materials. For example, the GUIDE4HardwareSecurity course includes a project on LLM-aided hardware Trojan insertion that has been successfully deployed in the classroom and in Cybersecurity Games and Conference (CSAW), a student competition and academic conference for cybersecurity. We also organized an NYU Cognichip Hackathon, engaging students across 24 international teams in AI-assisted RTL design workflows. The GUIDE repository is open for contributions and available at: https://github.com/FCHXWH823/LLM4ChipDesign.
GroundCount: Grounding Vision-Language Models with Object Detection for Mitigating Counting Hallucinations
Mar 11, 2026Vision Language Models (VLMs) exhibit persistent hallucinations in counting tasks, with accuracy substantially lower than other visual reasoning tasks (excluding sentiment). This phenomenon persists even in state-of-the-art reasoning-capable VLMs. Conversely, CNN-based object detection models (ODMs) such as YOLO excel at spatial localization and instance counting with minimal computational overhead. We propose GroundCount, a framework that augments VLMs with explicit spatial grounding from ODMs to mitigate counting hallucinations. In the best case, our prompt-based augmentation strategy achieves 81.3% counting accuracy on the best-performing model (Ovis2.5-2B) - a 6.6pp improvement - while reducing inference time by 22% through elimination of hallucination-driven reasoning loops for stronger models. We conduct comprehensive ablation studies demonstrating that positional encoding is a critical component, being beneficial for stronger models but detrimental for weaker ones. Confidence scores, by contrast, introduce noise for most architectures and their removal improves performance in four of five evaluated models. We further evaluate feature-level fusion architectures, finding that explicit symbolic grounding via structured prompts outperforms implicit feature fusion despite sophisticated cross-attention mechanisms. Our approach yields consistent improvements across four of five evaluated VLM architectures (6.2--7.5pp), with one architecture exhibiting degraded performance due to incompatibility between its iterative reflection mechanisms and structured prompts. These results suggest that counting failures stem from fundamental spatial-semantic integration limitations rather than architecture-specific deficiencies, while highlighting the importance of architectural compatibility in augmentation strategies.
Large Language Models (LLMs) for Electronic Design Automation (EDA)
Aug 27, 2025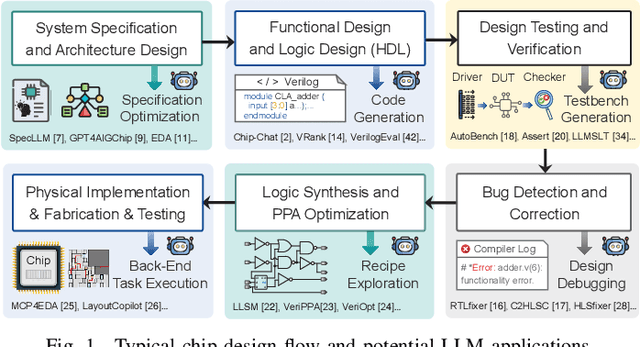

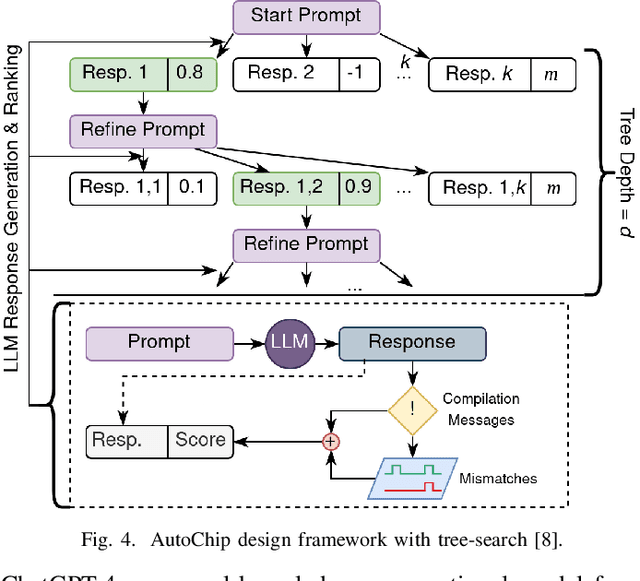
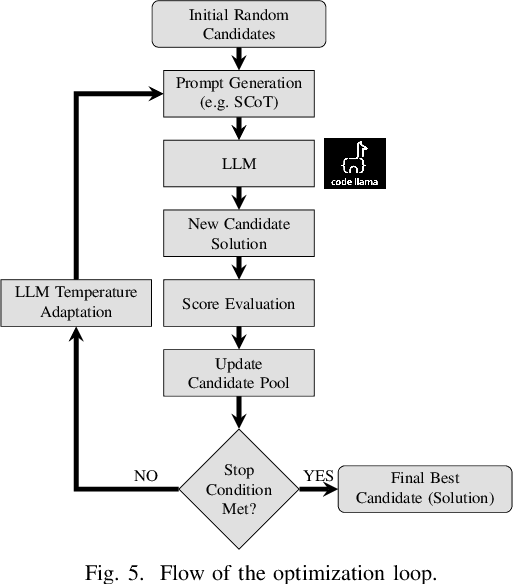
With the growing complexity of modern integrated circuits, hardware engineers are required to devote more effort to the full design-to-manufacturing workflow. This workflow involves numerous iterations, making it both labor-intensive and error-prone. Therefore, there is an urgent demand for more efficient Electronic Design Automation (EDA) solutions to accelerate hardware development. Recently, large language models (LLMs) have shown remarkable advancements in contextual comprehension, logical reasoning, and generative capabilities. Since hardware designs and intermediate scripts can be represented as text, integrating LLM for EDA offers a promising opportunity to simplify and even automate the entire workflow. Accordingly, this paper provides a comprehensive overview of incorporating LLMs into EDA, with emphasis on their capabilities, limitations, and future opportunities. Three case studies, along with their outlook, are introduced to demonstrate the capabilities of LLMs in hardware design, testing, and optimization. Finally, future directions and challenges are highlighted to further explore the potential of LLMs in shaping the next-generation EDA, providing valuable insights for researchers interested in leveraging advanced AI technologies for EDA.
VeriLoC: Line-of-Code Level Prediction of Hardware Design Quality from Verilog Code
Jun 08, 2025



Modern chip design is complex, and there is a crucial need for early-stage prediction of key design-quality metrics like timing and routing congestion directly from Verilog code (a commonly used programming language for hardware design). It is especially important yet complex to predict individual lines of code that cause timing violations or downstream routing congestion. Prior works have tried approaches like converting Verilog into an intermediate graph representation and using LLM embeddings alongside other features to predict module-level quality, but did not consider line-level quality prediction. We propose VeriLoC, the first method that predicts design quality directly from Verilog at both the line- and module-level. To this end, VeriLoC leverages recent Verilog code-generation LLMs to extract local line-level and module-level embeddings, and train downstream classifiers/regressors on concatenations of these embeddings. VeriLoC achieves high F1-scores of 0.86-0.95 for line-level congestion and timing prediction, and reduces the mean average percentage error from 14% - 18% for SOTA methods down to only 4%. We believe that VeriLoC embeddings and insights from our work will also be of value for other predictive and optimization tasks for complex hardware design.
Can Reasoning Models Reason about Hardware? An Agentic HLS Perspective
Mar 17, 2025



Recent Large Language Models (LLMs) such as OpenAI o3-mini and DeepSeek-R1 use enhanced reasoning through Chain-of-Thought (CoT). Their potential in hardware design, which relies on expert-driven iterative optimization, remains unexplored. This paper investigates whether reasoning LLMs can address challenges in High-Level Synthesis (HLS) design space exploration and optimization. During HLS, engineers manually define pragmas/directives to balance performance and resource constraints. We propose an LLM-based optimization agentic framework that automatically restructures code, inserts pragmas, and identifies optimal design points via feedback from HLs tools and access to integer-linear programming (ILP) solvers. Experiments compare reasoning models against conventional LLMs on benchmarks using success rate, efficiency, and design quality (area/latency) metrics, and provide the first-ever glimpse into the CoTs produced by a powerful open-source reasoning model like DeepSeek-R1.
Huff-LLM: End-to-End Lossless Compression for Efficient LLM Inference
Feb 02, 2025



As they become more capable, large language models (LLMs) have continued to rapidly increase in size. This has exacerbated the difficulty in running state of the art LLMs on small, edge devices. Standard techniques advocate solving this problem through lossy compression techniques such as quantization or pruning. However, such compression techniques are lossy, and have been shown to change model behavior in unpredictable manners. We propose Huff-LLM, an \emph{end-to-end, lossless} model compression method that lets users store LLM weights in compressed format \emph{everywhere} -- cloud, disk, main memory, and even in on-chip memory/buffers. This allows us to not only load larger models in main memory, but also reduces bandwidth required to load weights on chip, and makes more efficient use of on-chip weight buffers. In addition to the memory savings achieved via compression, we also show latency and energy efficiency improvements when performing inference with the compressed model.
Towards Unified Benchmark and Models for Multi-Modal Perceptual Metrics
Dec 13, 2024



Human perception of similarity across uni- and multimodal inputs is highly complex, making it challenging to develop automated metrics that accurately mimic it. General purpose vision-language models, such as CLIP and large multi-modal models (LMMs), can be applied as zero-shot perceptual metrics, and several recent works have developed models specialized in narrow perceptual tasks. However, the extent to which existing perceptual metrics align with human perception remains unclear. To investigate this question, we introduce UniSim-Bench, a benchmark encompassing 7 multi-modal perceptual similarity tasks, with a total of 25 datasets. Our evaluation reveals that while general-purpose models perform reasonably well on average, they often lag behind specialized models on individual tasks. Conversely, metrics fine-tuned for specific tasks fail to generalize well to unseen, though related, tasks. As a first step towards a unified multi-task perceptual similarity metric, we fine-tune both encoder-based and generative vision-language models on a subset of the UniSim-Bench tasks. This approach yields the highest average performance, and in some cases, even surpasses taskspecific models. Nevertheless, these models still struggle with generalization to unseen tasks, highlighting the ongoing challenge of learning a robust, unified perceptual similarity metric capable of capturing the human notion of similarity. The code and models are available at https://github.com/SaraGhazanfari/UniSim.
Out-of-Distribution Detection with Overlap Index
Dec 09, 2024



Out-of-distribution (OOD) detection is crucial for the deployment of machine learning models in the open world. While existing OOD detectors are effective in identifying OOD samples that deviate significantly from in-distribution (ID) data, they often come with trade-offs. For instance, deep OOD detectors usually suffer from high computational costs, require tuning hyperparameters, and have limited interpretability, whereas traditional OOD detectors may have a low accuracy on large high-dimensional datasets. To address these limitations, we propose a novel effective OOD detection approach that employs an overlap index (OI)-based confidence score function to evaluate the likelihood of a given input belonging to the same distribution as the available ID samples. The proposed OI-based confidence score function is non-parametric, lightweight, and easy to interpret, hence providing strong flexibility and generality. Extensive empirical evaluations indicate that our OI-based OOD detector is competitive with state-of-the-art OOD detectors in terms of detection accuracy on a wide range of datasets while requiring less computation and memory costs. Lastly, we show that the proposed OI-based confidence score function inherits nice properties from OI (e.g., insensitivity to small distributional variations and robustness against Huber $\epsilon$-contamination) and is a versatile tool for estimating OI and model accuracy in specific contexts.
PrefixLLM: LLM-aided Prefix Circuit Design
Dec 03, 2024



Prefix circuits are fundamental components in digital adders, widely used in digital systems due to their efficiency in calculating carry signals. Synthesizing prefix circuits with minimized area and delay is crucial for enhancing the performance of modern computing systems. Recently, large language models (LLMs) have demonstrated a surprising ability to perform text generation tasks. We propose PrefixLLM, that leverages LLMs for prefix circuit synthesis. PrefixLLM transforms the prefix circuit synthesis task into a structured text generation problem, termed the Structured Prefix Circuit Representation (SPCR), and introduces an iterative framework to automatically and accurately generate valid SPCRs. We further present a design space exploration (DSE) framework that uses LLMs to iteratively search for area and delay optimized prefix circuits. Compared to state-of-the-art, PrefixLLM can reduce the area by 3.70% under the same delay constraint. This work highlights the use of LLMs in the synthesis of arithmetic circuits, which can be transformed into the structured text generation.