 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLLMs for Secure Hardware Design and Related Problems: Opportunities and Challenges
May 11, 2026The integration of Large Language Models (LLMs) into Electronic Design Automation (EDA) and hardware security is rapidly reshaping the semiconductor industry. While LLMs offer unprecedented capabilities in generating Register Transfer Level (RTL) code, automating testbenches, and bridging the semantic gap between high-level specifications and silicon, they simultaneously introduce severe vulnerabilities. This comprehensive review provides an in-depth analysis of the state-of-the-art in LLM-driven hardware design, organized around key advancements in EDA synthesis, hardware trust, design for security, and education. We systematically expand on the methodologies of recent breakthroughs -- from reasoning-driven synthesis and multi-agent vulnerability extraction to data contamination and adversarial machine learning (ML) evasion. We integrate general discussions on critical countermeasures, such as dynamic benchmarking to combat data memorization and aggressive red-teaming for robust security assessment. Finally, we synthesize cross-cutting lessons learned to guide future research toward secure, trustworthy, and autonomous design ecosystems.
RESCORE: LLM-Driven Simulation Recovery in Control Systems Research Papers
Apr 06, 2026Reconstructing numerical simulations from control systems research papers is often hindered by underspecified parameters and ambiguous implementation details. We define the task of Paper to Simulation Recoverability, the ability of an automated system to generate executable code that faithfully reproduces a paper's results. We curate a benchmark of 500 papers from the IEEE Conference on Decision and Control (CDC) and propose RESCORE, a three component LLM agentic framework, Analyzer, Coder, and Verifier. RESCORE uses iterative execution feedback and visual comparison to improve reconstruction fidelity. Our method successfully recovers task coherent simulations for 40.7% of benchmark instances, outperforming single pass generation. Notably, the RESCORE automated pipeline achieves an estimated 10X speedup over manual human replication, drastically cutting the time and effort required to verify published control methodologies. We will release our benchmark and agents to foster community progress in automated research replication.
GUIDE: GenAI Units In Digital Design Education
Mar 18, 2026GenAI Units In Digital Design Education (GUIDE) is an open courseware repository with runnable Google Colab labs and other materials. We describe the repository's architecture and educational approach based on standardized teaching units comprising slides, short videos, runnable labs, and related papers. This organization enables consistency for both the students' learning experience and the reuse and grading by instructors. We demonstrate GUIDE in practice with three representative units: VeriThoughts for reasoning and formal-verification-backed RTL generation, enhanced LLM-aided testbench generation, and LLMPirate for IP Piracy. We also provide details for four example course instances (GUIDE4ChipDesign, Build your ASIC, GUIDE4HardwareSecurity, and Hardware Design) that assemble GUIDE units into full semester offerings, learning outcomes, and capstone projects, all based on proven materials. For example, the GUIDE4HardwareSecurity course includes a project on LLM-aided hardware Trojan insertion that has been successfully deployed in the classroom and in Cybersecurity Games and Conference (CSAW), a student competition and academic conference for cybersecurity. We also organized an NYU Cognichip Hackathon, engaging students across 24 international teams in AI-assisted RTL design workflows. The GUIDE repository is open for contributions and available at: https://github.com/FCHXWH823/LLM4ChipDesign.
GroundCount: Grounding Vision-Language Models with Object Detection for Mitigating Counting Hallucinations
Mar 11, 2026Vision Language Models (VLMs) exhibit persistent hallucinations in counting tasks, with accuracy substantially lower than other visual reasoning tasks (excluding sentiment). This phenomenon persists even in state-of-the-art reasoning-capable VLMs. Conversely, CNN-based object detection models (ODMs) such as YOLO excel at spatial localization and instance counting with minimal computational overhead. We propose GroundCount, a framework that augments VLMs with explicit spatial grounding from ODMs to mitigate counting hallucinations. In the best case, our prompt-based augmentation strategy achieves 81.3% counting accuracy on the best-performing model (Ovis2.5-2B) - a 6.6pp improvement - while reducing inference time by 22% through elimination of hallucination-driven reasoning loops for stronger models. We conduct comprehensive ablation studies demonstrating that positional encoding is a critical component, being beneficial for stronger models but detrimental for weaker ones. Confidence scores, by contrast, introduce noise for most architectures and their removal improves performance in four of five evaluated models. We further evaluate feature-level fusion architectures, finding that explicit symbolic grounding via structured prompts outperforms implicit feature fusion despite sophisticated cross-attention mechanisms. Our approach yields consistent improvements across four of five evaluated VLM architectures (6.2--7.5pp), with one architecture exhibiting degraded performance due to incompatibility between its iterative reflection mechanisms and structured prompts. These results suggest that counting failures stem from fundamental spatial-semantic integration limitations rather than architecture-specific deficiencies, while highlighting the importance of architectural compatibility in augmentation strategies.
CyberExplorer: Benchmarking LLM Offensive Security Capabilities in a Real-World Attacking Simulation Environment
Feb 08, 2026Real-world offensive security operations are inherently open-ended: attackers explore unknown attack surfaces, revise hypotheses under uncertainty, and operate without guaranteed success. Existing LLM-based offensive agent evaluations rely on closed-world settings with predefined goals and binary success criteria. To address this gap, we introduce CyberExplorer, an evaluation suite with two core components: (1) an open-environment benchmark built on a virtual machine hosting 40 vulnerable web services derived from real-world CTF challenges, where agents autonomously perform reconnaissance, target selection, and exploitation without prior knowledge of vulnerability locations; and (2) a reactive multi-agent framework supporting dynamic exploration without predefined plans. CyberExplorer enables fine-grained evaluation beyond flag recovery, capturing interaction dynamics, coordination behavior, failure modes, and vulnerability discovery signals-bridging the gap between benchmarks and realistic multi-target attack scenarios.
TrojanGYM: A Detector-in-the-Loop LLM for Adaptive RTL Hardware Trojan Insertion
Jan 23, 2026Hardware Trojans (HTs) remain a critical threat because learning-based detectors often overfit to narrow trigger/payload patterns and small, stylized benchmarks. We introduce TrojanGYM, an agentic, LLM-driven framework that automatically curates HT insertions to expose detector blind spots while preserving design correctness. Given high-level HT specifications, a suite of cooperating LLM agents (instantiated with GPT-4, LLaMA-3.3-70B, and Gemini-2.5Pro) proposes and refines RTL modifications that realize diverse triggers and payloads without impacting normal functionality. TrojanGYM implements a feedback-driven benchmark generation loop co-designed with HT detectors, in which constraint-aware syntactic checking and GNN-based HT detectors provide feedback that iteratively refines HT specifications and insertion strategies to better surface detector blind spots. We further propose Robust-GNN4TJ, a new implementation of the GNN4TJ with improved graph extraction, training robustness, and prediction reliability, especially on LLM-generated HT designs. On the most challenging TrojanGYM-generated benchmarks, Robust-GNN4TJ raises HT detection rates from 0% to 60% relative to a prior GNN-based detector. We instantiate TrojanGYM on SRAM, AES-128, and UART designs at RTL level, and show that it systematically produces diverse, functionally correct HTs that reach up to 83.33% evasion rates against modern GNN-based detectors, revealing robustness gaps that are not apparent when these detectors are evaluated solely on existing TrustHub-style benchmarks. Post peer-review, we will release all codes and artifacts.
Large Language Models (LLMs) for Electronic Design Automation (EDA)
Aug 27, 2025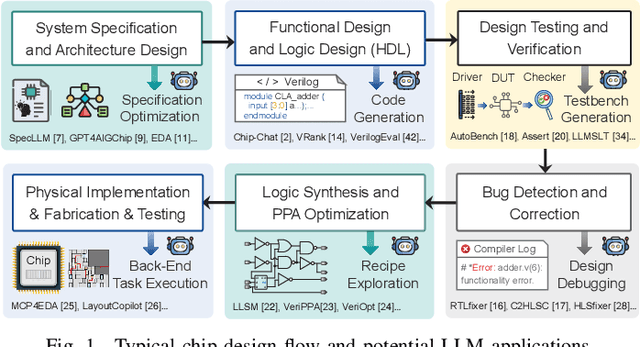

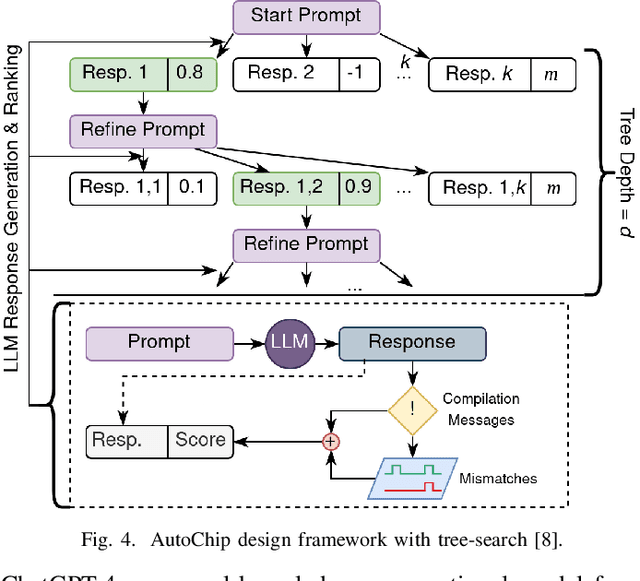
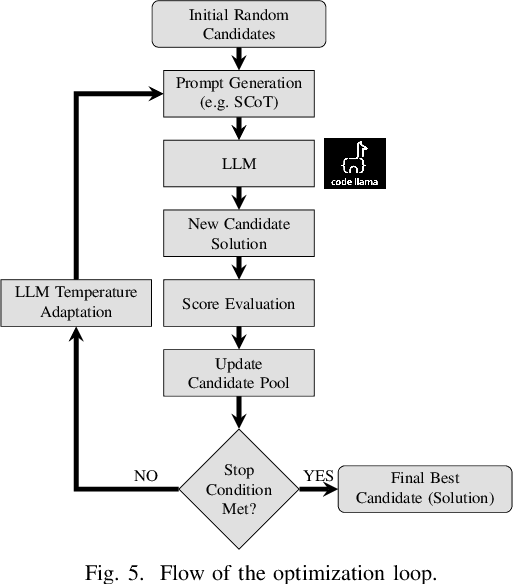
With the growing complexity of modern integrated circuits, hardware engineers are required to devote more effort to the full design-to-manufacturing workflow. This workflow involves numerous iterations, making it both labor-intensive and error-prone. Therefore, there is an urgent demand for more efficient Electronic Design Automation (EDA) solutions to accelerate hardware development. Recently, large language models (LLMs) have shown remarkable advancements in contextual comprehension, logical reasoning, and generative capabilities. Since hardware designs and intermediate scripts can be represented as text, integrating LLM for EDA offers a promising opportunity to simplify and even automate the entire workflow. Accordingly, this paper provides a comprehensive overview of incorporating LLMs into EDA, with emphasis on their capabilities, limitations, and future opportunities. Three case studies, along with their outlook, are introduced to demonstrate the capabilities of LLMs in hardware design, testing, and optimization. Finally, future directions and challenges are highlighted to further explore the potential of LLMs in shaping the next-generation EDA, providing valuable insights for researchers interested in leveraging advanced AI technologies for EDA.
VeriLoC: Line-of-Code Level Prediction of Hardware Design Quality from Verilog Code
Jun 08, 2025



Modern chip design is complex, and there is a crucial need for early-stage prediction of key design-quality metrics like timing and routing congestion directly from Verilog code (a commonly used programming language for hardware design). It is especially important yet complex to predict individual lines of code that cause timing violations or downstream routing congestion. Prior works have tried approaches like converting Verilog into an intermediate graph representation and using LLM embeddings alongside other features to predict module-level quality, but did not consider line-level quality prediction. We propose VeriLoC, the first method that predicts design quality directly from Verilog at both the line- and module-level. To this end, VeriLoC leverages recent Verilog code-generation LLMs to extract local line-level and module-level embeddings, and train downstream classifiers/regressors on concatenations of these embeddings. VeriLoC achieves high F1-scores of 0.86-0.95 for line-level congestion and timing prediction, and reduces the mean average percentage error from 14% - 18% for SOTA methods down to only 4%. We believe that VeriLoC embeddings and insights from our work will also be of value for other predictive and optimization tasks for complex hardware design.
MapleGrasp: Mask-guided Feature Pooling for Language-driven Efficient Robotic Grasping
Jun 06, 2025Robotic manipulation of unseen objects via natural language commands remains challenging. Language driven robotic grasping (LDRG) predicts stable grasp poses from natural language queries and RGB-D images. Here we introduce Mask-guided feature pooling, a lightweight enhancement to existing LDRG methods. Our approach employs a two-stage training strategy: first, a vision-language model generates feature maps from CLIP-fused embeddings, which are upsampled and weighted by text embeddings to produce segmentation masks. Next, the decoder generates separate feature maps for grasp prediction, pooling only token features within these masked regions to efficiently predict grasp poses. This targeted pooling approach reduces computational complexity, accelerating both training and inference. Incorporating mask pooling results in a 12% improvement over prior approaches on the OCID-VLG benchmark. Furthermore, we introduce RefGraspNet, an open-source dataset eight times larger than existing alternatives, significantly enhancing model generalization for open-vocabulary grasping. By extending 2D grasp predictions to 3D via depth mapping and inverse kinematics, our modular method achieves performance comparable to recent Vision-Language-Action (VLA) models on the LIBERO simulation benchmark, with improved generalization across different task suites. Real-world experiments on a 7 DoF Franka robotic arm demonstrate a 57% success rate with unseen objects, surpassing competitive baselines by 7%. Code will be released post publication.
CRAKEN: Cybersecurity LLM Agent with Knowledge-Based Execution
May 21, 2025



Large Language Model (LLM) agents can automate cybersecurity tasks and can adapt to the evolving cybersecurity landscape without re-engineering. While LLM agents have demonstrated cybersecurity capabilities on Capture-The-Flag (CTF) competitions, they have two key limitations: accessing latest cybersecurity expertise beyond training data, and integrating new knowledge into complex task planning. Knowledge-based approaches that incorporate technical understanding into the task-solving automation can tackle these limitations. We present CRAKEN, a knowledge-based LLM agent framework that improves cybersecurity capability through three core mechanisms: contextual decomposition of task-critical information, iterative self-reflected knowledge retrieval, and knowledge-hint injection that transforms insights into adaptive attack strategies. Comprehensive evaluations with different configurations show CRAKEN's effectiveness in multi-stage vulnerability detection and exploitation compared to previous approaches. Our extensible architecture establishes new methodologies for embedding new security knowledge into LLM-driven cybersecurity agentic systems. With a knowledge database of CTF writeups, CRAKEN obtained an accuracy of 22% on NYU CTF Bench, outperforming prior works by 3% and achieving state-of-the-art results. On evaluation of MITRE ATT&CK techniques, CRAKEN solves 25-30% more techniques than prior work, demonstrating improved cybersecurity capabilities via knowledge-based execution. We make our framework open source to public https://github.com/NYU-LLM-CTF/nyuctf_agents_craken.