 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Risk to Resilience: Towards Assessing and Mitigating the Risk of Data Reconstruction Attacks in Federated Learning
Dec 17, 2025Data Reconstruction Attacks (DRA) pose a significant threat to Federated Learning (FL) systems by enabling adversaries to infer sensitive training data from local clients. Despite extensive research, the question of how to characterize and assess the risk of DRAs in FL systems remains unresolved due to the lack of a theoretically-grounded risk quantification framework. In this work, we address this gap by introducing Invertibility Loss (InvLoss) to quantify the maximum achievable effectiveness of DRAs for a given data instance and FL model. We derive a tight and computable upper bound for InvLoss and explore its implications from three perspectives. First, we show that DRA risk is governed by the spectral properties of the Jacobian matrix of exchanged model updates or feature embeddings, providing a unified explanation for the effectiveness of defense methods. Second, we develop InvRE, an InvLoss-based DRA risk estimator that offers attack method-agnostic, comprehensive risk evaluation across data instances and model architectures. Third, we propose two adaptive noise perturbation defenses that enhance FL privacy without harming classification accuracy. Extensive experiments on real-world datasets validate our framework, demonstrating its potential for systematic DRA risk evaluation and mitigation in FL systems.
SCS-SupCon: Sigmoid-based Common and Style Supervised Contrastive Learning with Adaptive Decision Boundaries
Dec 17, 2025Image classification is hindered by subtle inter-class differences and substantial intra-class variations, which limit the effectiveness of existing contrastive learning methods. Supervised contrastive approaches based on the InfoNCE loss suffer from negative-sample dilution and lack adaptive decision boundaries, thereby reducing discriminative power in fine-grained recognition tasks. To address these limitations, we propose Sigmoid-based Common and Style Supervised Contrastive Learning (SCS-SupCon). Our framework introduces a sigmoid-based pairwise contrastive loss with learnable temperature and bias parameters to enable adaptive decision boundaries. This formulation emphasizes hard negatives, mitigates negative-sample dilution, and more effectively exploits supervision. In addition, an explicit style-distance constraint further disentangles style and content representations, leading to more robust feature learning. Comprehensive experiments on six benchmark datasets, including CUB200-2011 and Stanford Dogs, demonstrate that SCS-SupCon achieves state-of-the-art performance across both CNN and Transformer backbones. On CIFAR-100 with ResNet-50, SCS-SupCon improves top-1 accuracy over SupCon by approximately 3.9 percentage points and over CS-SupCon by approximately 1.7 points under five-fold cross-validation. On fine-grained datasets, it outperforms CS-SupCon by 0.4--3.0 points. Extensive ablation studies and statistical analyses further confirm the robustness and generalization of the proposed framework, with Friedman tests and Nemenyi post-hoc evaluations validating the stability of the observed improvements.
COMPARE: Clinical Optimization with Modular Planning and Assessment via RAG-Enhanced AI-OCT: Superior Decision Support for Percutaneous Coronary Intervention Compared to ChatGPT-5 and Junior Operators
Dec 11, 2025Background: While intravascular imaging, particularly optical coherence tomography (OCT), improves percutaneous coronary intervention (PCI) outcomes, its interpretation is operator-dependent. General-purpose artificial intelligence (AI) shows promise but lacks domain-specific reliability. We evaluated the performance of CA-GPT, a novel large model deployed on an AI-OCT system, against that of the general-purpose ChatGPT-5 and junior physicians for OCT-guided PCI planning and assessment. Methods: In this single-center analysis of 96 patients who underwent OCT-guided PCI, the procedural decisions generated by the CA-GPT, ChatGPT-5, and junior physicians were compared with an expert-derived procedural record. Agreement was assessed using ten pre-specified metrics across pre-PCI and post-PCI phases. Results: For pre-PCI planning, CA-GPT demonstrated significantly higher median agreement scores (5[IQR 3.75-5]) compared to both ChatGPT-5 (3[2-4], P<0.001) and junior physicians (4[3-4], P<0.001). CA-GPT significantly outperformed ChatGPT-5 across all individual pre-PCI metrics and showed superior performance to junior physicians in stent diameter (90.3% vs. 72.2%, P<0.05) and length selection (80.6% vs. 52.8%, P<0.01). In post-PCI assessment, CA-GPT maintained excellent overall agreement (5[4.75-5]), significantly higher than both ChatGPT-5 (4[4-5], P<0.001) and junior physicians (5[4-5], P<0.05). Subgroup analysis confirmed CA-GPT's robust performance advantage in complex scenarios. Conclusion: The CA-GPT-based AI-OCT system achieved superior decision-making agreement versus a general-purpose large language model and junior physicians across both PCI planning and assessment phases. This approach provides a standardized and reliable method for intravascular imaging interpretation, demonstrating significant potential to augment operator expertise and optimize OCT-guided PCI.
DOCR-Inspector: Fine-Grained and Automated Evaluation of Document Parsing with VLM
Dec 11, 2025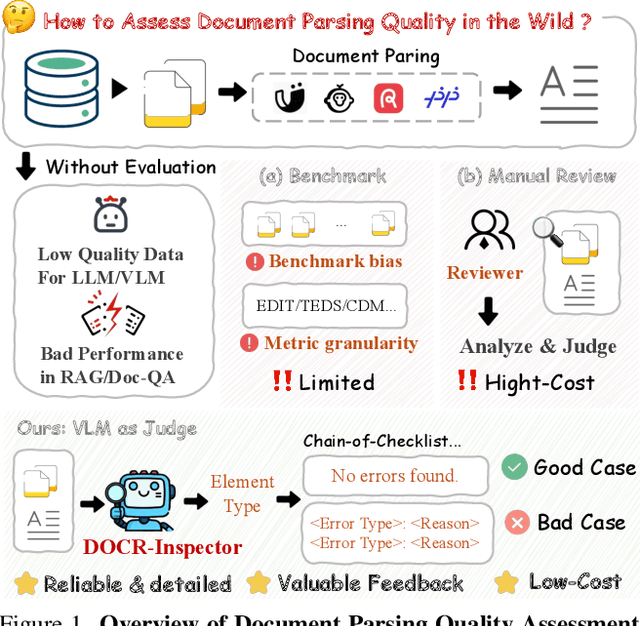
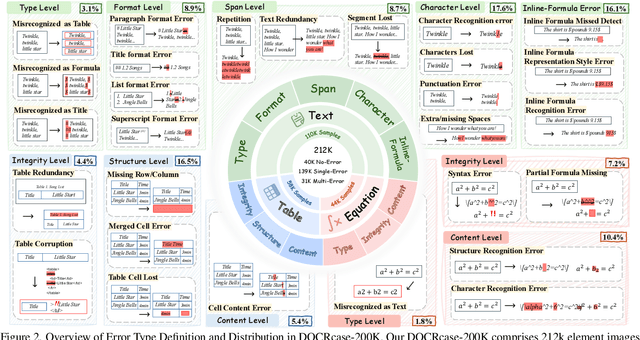

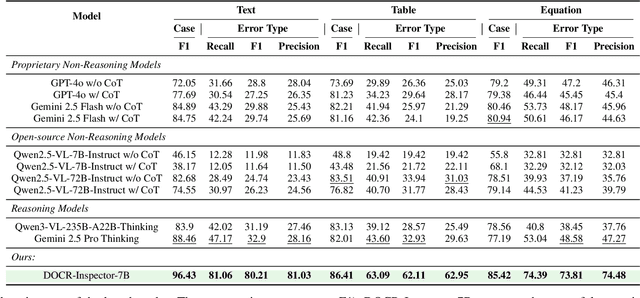
Document parsing aims to transform unstructured PDF images into semi-structured data, facilitating the digitization and utilization of information in diverse domains. While vision language models (VLMs) have significantly advanced this task, achieving reliable, high-quality parsing in real-world scenarios remains challenging. Common practice often selects the top-performing model on standard benchmarks. However, these benchmarks may carry dataset-specific biases, leading to inconsistent model rankings and limited correlation with real-world performance. Moreover, benchmark metrics typically provide only overall scores, which can obscure distinct error patterns in output. This raises a key challenge: how can we reliably and comprehensively assess document parsing quality in the wild? We address this problem with DOCR-Inspector, which formalizes document parsing assessment as fine-grained error detection and analysis. Leveraging VLM-as-a-Judge, DOCR-Inspector analyzes a document image and its parsed output, identifies all errors, assigns them to one of 28 predefined types, and produces a comprehensive quality assessment. To enable this capability, we construct DOCRcase-200K for training and propose the Chain-of-Checklist reasoning paradigm to enable the hierarchical structure of parsing quality assessment. For empirical validation, we introduce DOCRcaseBench, a set of 882 real-world document parsing cases with manual annotations. On this benchmark, DOCR-Inspector-7B outperforms commercial models like Gemini 2.5 Pro, as well as leading open-source models. Further experiments demonstrate that its quality assessments provide valuable guidance for parsing results refinement, making DOCR-Inspector both a practical evaluator and a driver for advancing document parsing systems at scale. Model and code are released at: https://github.com/ZZZZZQT/DOCR-Inspector.
Argus: A Multi-Agent Sensitive Information Leakage Detection Framework Based on Hierarchical Reference Relationships
Dec 09, 2025Sensitive information leakage in code repositories has emerged as a critical security challenge. Traditional detection methods that rely on regular expressions, fingerprint features, and high-entropy calculations often suffer from high false-positive rates. This not only reduces detection efficiency but also significantly increases the manual screening burden on developers. Recent advances in large language models (LLMs) and multi-agent collaborative architectures have demonstrated remarkable potential for tackling complex tasks, offering a novel technological perspective for sensitive information detection. In response to these challenges, we propose Argus, a multi-agent collaborative framework for detecting sensitive information. Argus employs a three-tier detection mechanism that integrates key content, file context, and project reference relationships to effectively reduce false positives and enhance overall detection accuracy. To comprehensively evaluate Argus in real-world repository environments, we developed two new benchmarks, one to assess genuine leak detection capabilities and another to evaluate false-positive filtering performance. Experimental results show that Argus achieves up to 94.86% accuracy in leak detection, with a precision of 96.36%, recall of 94.64%, and an F1 score of 0.955. Moreover, the analysis of 97 real repositories incurred a total cost of only 2.2$. All code implementations and related datasets are publicly available at https://github.com/TheBinKing/Argus-Guard for further research and application.
MiroThinker: Pushing the Performance Boundaries of Open-Source Research Agents via Model, Context, and Interactive Scaling
Nov 18, 2025We present MiroThinker v1.0, an open-source research agent designed to advance tool-augmented reasoning and information-seeking capabilities. Unlike previous agents that only scale up model size or context length, MiroThinker explores interaction scaling at the model level, systematically training the model to handle deeper and more frequent agent-environment interactions as a third dimension of performance improvement. Unlike LLM test-time scaling, which operates in isolation and risks degradation with longer reasoning chains, interactive scaling leverages environment feedback and external information acquisition to correct errors and refine trajectories. Through reinforcement learning, the model achieves efficient interaction scaling: with a 256K context window, it can perform up to 600 tool calls per task, enabling sustained multi-turn reasoning and complex real-world research workflows. Across four representative benchmarks-GAIA, HLE, BrowseComp, and BrowseComp-ZH-the 72B variant achieves up to 81.9%, 37.7%, 47.1%, and 55.6% accuracy respectively, surpassing previous open-source agents and approaching commercial counterparts such as GPT-5-high. Our analysis reveals that MiroThinker benefits from interactive scaling consistently: research performance improves predictably as the model engages in deeper and more frequent agent-environment interactions, demonstrating that interaction depth exhibits scaling behaviors analogous to model size and context length. These findings establish interaction scaling as a third critical dimension for building next-generation open research agents, complementing model capacity and context windows.
Beyond Pixels: Semantic-aware Typographic Attack for Geo-Privacy Protection
Nov 16, 2025Large Visual Language Models (LVLMs) now pose a serious yet overlooked privacy threat, as they can infer a social media user's geolocation directly from shared images, leading to unintended privacy leakage. While adversarial image perturbations provide a potential direction for geo-privacy protection, they require relatively strong distortions to be effective against LVLMs, which noticeably degrade visual quality and diminish an image's value for sharing. To overcome this limitation, we identify typographical attacks as a promising direction for protecting geo-privacy by adding text extension outside the visual content. We further investigate which textual semantics are effective in disrupting geolocation inference and design a two-stage, semantics-aware typographical attack that generates deceptive text to protect user privacy. Extensive experiments across three datasets demonstrate that our approach significantly reduces geolocation prediction accuracy of five state-of-the-art commercial LVLMs, establishing a practical and visually-preserving protection strategy against emerging geo-privacy threats.
Dynamic Gaussian Scene Reconstruction from Unsynchronized Videos
Nov 14, 2025Multi-view video reconstruction plays a vital role in computer vision, enabling applications in film production, virtual reality, and motion analysis. While recent advances such as 4D Gaussian Splatting (4DGS) have demonstrated impressive capabilities in dynamic scene reconstruction, they typically rely on the assumption that input video streams are temporally synchronized. However, in real-world scenarios, this assumption often fails due to factors like camera trigger delays or independent recording setups, leading to temporal misalignment across views and reduced reconstruction quality. To address this challenge, a novel temporal alignment strategy is proposed for high-quality 4DGS reconstruction from unsynchronized multi-view videos. Our method features a coarse-to-fine alignment module that estimates and compensates for each camera's time shift. The method first determines a coarse, frame-level offset and then refines it to achieve sub-frame accuracy. This strategy can be integrated as a readily integrable module into existing 4DGS frameworks, enhancing their robustness when handling asynchronous data. Experiments show that our approach effectively processes temporally misaligned videos and significantly enhances baseline methods.
Enhancing the Medical Context-Awareness Ability of LLMs via Multifaceted Self-Refinement Learning
Nov 14, 2025Large language models (LLMs) have shown great promise in the medical domain, achieving strong performance on several benchmarks. However, they continue to underperform in real-world medical scenarios, which often demand stronger context-awareness, i.e., the ability to recognize missing or critical details (e.g., user identity, medical history, risk factors) and provide safe, helpful, and contextually appropriate responses. To address this issue, we propose Multifaceted Self-Refinement (MuSeR), a data-driven approach that enhances LLMs' context-awareness along three key facets (decision-making, communication, and safety) through self-evaluation and refinement. Specifically, we first design a attribute-conditioned query generator that simulates diverse real-world user contexts by varying attributes such as role, geographic region, intent, and degree of information ambiguity. An LLM then responds to these queries, self-evaluates its answers along three key facets, and refines its responses to better align with the requirements of each facet. Finally, the queries and refined responses are used for supervised fine-tuning to reinforce the model's context-awareness ability. Evaluation results on the latest HealthBench dataset demonstrate that our method significantly improves LLM performance across multiple aspects, with particularly notable gains in the context-awareness axis. Furthermore, by incorporating knowledge distillation with the proposed method, the performance of a smaller backbone LLM (e.g., Qwen3-32B) surpasses its teacher model, achieving a new SOTA across all open-source LLMs on HealthBench (63.8%) and its hard subset (43.1%). Code and dataset will be released at https://muser-llm.github.io.
Mixture-of-Channels: Exploiting Sparse FFNs for Efficient LLMs Pre-Training and Inference
Nov 12, 2025Large language models (LLMs) have demonstrated remarkable success across diverse artificial intelligence tasks, driven by scaling laws that correlate model size and training data with performance improvements. However, this scaling paradigm incurs substantial memory overhead, creating significant challenges for both training and inference. While existing research has primarily addressed parameter and optimizer state memory reduction, activation memory-particularly from feed-forward networks (FFNs)-has become the critical bottleneck, especially when FlashAttention is implemented. In this work, we conduct a detailed memory profiling of LLMs and identify FFN activations as the predominant source to activation memory overhead. Motivated by this, we introduce Mixture-of-Channels (MoC), a novel FFN architecture that selectively activates only the Top-K most relevant channels per token determined by SwiGLU's native gating mechanism. MoC substantially reduces activation memory during pre-training and improves inference efficiency by reducing memory access through partial weight loading into GPU SRAM. Extensive experiments validate that MoC delivers significant memory savings and throughput gains while maintaining competitive model performance.