 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePhysiologically Constrained Musculoskeletal Neural Network for Multi-DoF Joint Kinematics Estimation from Partially Observed sEMG
Jun 05, 2026This paper investigates multi-degrees of freedom (DoF) joint kinematics estimation under partially observed surface electromyography (sEMG), where only a subset of task-relevant muscles can be measured due to anatomical inaccessibility or sensor constraints. A novel musculoskeletal neural network (MSK-NN) is proposed to estimate multi-DoF joint angles while simultaneously inferring activations for both measured and unmeasured muscles. MSK-NN consists of a CNN-based muscle activation estimator and an embedded MSK forward dynamics module, forming a fully differentiable architecture. Unlike existing hybrid neural frameworks that require additional biomechanical labels (e.g., muscle-tendon forces, joint torques), MSK-NN is trained without direct supervision of internal biomechanical variables. A composite physics-physiology loss is designed by incorporating a joint kinematics loss, a data-driven muscle synergy loss, and an anatomy-guided trend loss. The proposed method is evaluated on two-DoF wrist kinematics estimation across three rhythmic motions with unconstrained speed and amplitude, and one random motion. Compared with CNN, Bi-LSTM, CNN-LSTM, and PET baselines, MSK-NN achieves lower normalized root mean square error (NRMSE) and higher coefficient of determination (R2), especially for the random motion. More importantly, the optimized MSK parameters remain within physiological limits, and the estimated activation of an input-excluded muscle exhibits strong temporal agreement with its recorded sEMG envelope, demonstrating the capability of musculoskeletal (MSK)-NN to recover physiologically plausible activations.
FiSeR: Fine-Grained Source Representations for Cross-Domain AI Image Detection
May 30, 2026Real-world synthetic image detectors often generalize poorly under domain shift despite strong in-domain performance. Using unsupervised UMAP projections, we find that natural and synthetic features remain partially separable on unseen datasets, yet performance still drops, suggesting that the classification head overfits to training-domain artifacts. Therefore, the key is to learn more transferable representations so that the decision criterion is more stable and robust to domain shifts. Based on the structural fact that synthetic images are produced by diverse generators, we propose a hierarchical contrastive learning framework that improves the separability between natural and synthetic images while preserving generator identity information. It jointly optimizes (i) a coarse contrastive objective between natural and synthetic images and (ii) a fine contrastive objective among synthetic images using generator identities. Trained on WildFake, our method achieves an average AUROC gain of +10.22 on cross-domain evaluation over Chameleon, AIGIBench, Community Forensics, and GenImage under the same settings as the strong baseline DIRE. For few-shot adaptation, we freeze the backbone and fit an SVM head on 10 labeled samples per class, improving AUROC by +10.64 on AIGIBench and +17.41 on Chameleon, averaged over 12 widely used detectors. Our code is publicly available at: https://github.com/heyongxin233/FiSeR.
Generative Auto-Bidding with Unified Modeling and Exploration
May 19, 2026Automated bidding is central to modern digital advertising. Early rule-based methods lacked adaptability, while subsequent Reinforcement Learning approaches modeled bidding as a Markov Decision Process but struggled with long-term dependencies. Recent generative models show promise, yet they lack explicit mechanisms to balance exploration and safety, relying solely on action perturbations or trajectory guidance without a safety fallback. This results in inefficient exploration and elevated financial risk for advertising platforms. To address this gap, we propose GUIDE (Generative Auto-Bidding with Unified Modeling and Exploration), a framework that synergistically integrates directed exploration with a safe fallback mechanism. GUIDE employs a Decision Transformer (DT) to jointly model historical bidding actions and environmental state transitions. A Q-value module guides the DT's exploration via regularization constraints, while an Inverse Dynamics Module (IDM) leverages DT-predicted future states to infer robust, behaviorally consistent actions as a safe policy fallback. The Q-value module then adaptively selects the final action between these two options, balancing exploration and safety. Together, these components form an integrated "explore-safeguard-select" pipeline that unifies efficiency and safety. We conduct extensive experiments on public datasets, in simulated auction environments, and through large-scale online deployment on Taobao, a leading Chinese advertising platform. Results show GUIDE consistently outperforms state-of-the-art baselines across all scenarios. In real-world deployment, GUIDE achieves notable gains: +4.10% ad GMV, +1.40% ad clicks, +1.66% ad cost, and +3.52% ad ROI, demonstrating its effectiveness and strong industrial applicability.
TabEmbed: Benchmarking and Learning Generalist Embeddings for Tabular Understanding
May 06, 2026Foundation models have established unified representations for natural language processing, yet this paradigm remains largely unexplored for tabular data. Existing methods face fundamental limitations: LLM-based approaches lack retrieval-compatible vector outputs, whereas text embedding models often fail to capture tabular structure and numerical semantics. To bridge this gap, we first introduce the Tabular Embedding Benchmark (TabBench), a comprehensive suite designed to evaluate the tabular understanding capability of embedding models. We then propose TabEmbed, the first generalist embedding model that unifies tabular classification and retrieval within a shared embedding space. By reformulating diverse tabular tasks as semantic matching problems, TabEmbed leverages large-scale contrastive learning with positive-aware hard negative mining to discern fine-grained structural and numerical nuances. Experimental results on TabBench demonstrate that TabEmbed significantly outperforms state-of-the-art text embedding models, establishing a new baseline for universal tabular representation learning. Code and datasets are publicly available at https://github.com/qiangminjie27/TabEmbed and https://huggingface.co/datasets/qiangminjie27/TabBench.
KMLP: A Scalable Hybrid Architecture for Web-Scale Tabular Data Modeling
Feb 26, 2026Predictive modeling on web-scale tabular data with billions of instances and hundreds of heterogeneous numerical features faces significant scalability challenges. These features exhibit anisotropy, heavy-tailed distributions, and non-stationarity, creating bottlenecks for models like Gradient Boosting Decision Trees and requiring laborious manual feature engineering. We introduce KMLP, a hybrid deep architecture integrating a shallow Kolmogorov-Arnold Network (KAN) front-end with a Gated Multilayer Perceptron (gMLP) backbone. The KAN front-end uses learnable activation functions to automatically model complex non-linear transformations for each feature, while the gMLP backbone captures high-order interactions. Experiments on public benchmarks and an industrial dataset with billions of samples show KMLP achieves state-of-the-art performance, with advantages over baselines like GBDTs increasing at larger scales, validating KMLP as a scalable deep learning paradigm for large-scale web tabular data.
Step 3.5 Flash: Open Frontier-Level Intelligence with 11B Active Parameters
Feb 11, 2026We introduce Step 3.5 Flash, a sparse Mixture-of-Experts (MoE) model that bridges frontier-level agentic intelligence and computational efficiency. We focus on what matters most when building agents: sharp reasoning and fast, reliable execution. Step 3.5 Flash pairs a 196B-parameter foundation with 11B active parameters for efficient inference. It is optimized with interleaved 3:1 sliding-window/full attention and Multi-Token Prediction (MTP-3) to reduce the latency and cost of multi-round agentic interactions. To reach frontier-level intelligence, we design a scalable reinforcement learning framework that combines verifiable signals with preference feedback, while remaining stable under large-scale off-policy training, enabling consistent self-improvement across mathematics, code, and tool use. Step 3.5 Flash demonstrates strong performance across agent, coding, and math tasks, achieving 85.4% on IMO-AnswerBench, 86.4% on LiveCodeBench-v6 (2024.08-2025.05), 88.2% on tau2-Bench, 69.0% on BrowseComp (with context management), and 51.0% on Terminal-Bench 2.0, comparable to frontier models such as GPT-5.2 xHigh and Gemini 3.0 Pro. By redefining the efficiency frontier, Step 3.5 Flash provides a high-density foundation for deploying sophisticated agents in real-world industrial environments.
Q-Regularized Generative Auto-Bidding: From Suboptimal Trajectories to Optimal Policies
Jan 06, 2026With the rapid development of e-commerce, auto-bidding has become a key asset in optimizing advertising performance under diverse advertiser environments. The current approaches focus on reinforcement learning (RL) and generative models. These efforts imitate offline historical behaviors by utilizing a complex structure with expensive hyperparameter tuning. The suboptimal trajectories further exacerbate the difficulty of policy learning. To address these challenges, we proposes QGA, a novel Q-value regularized Generative Auto-bidding method. In QGA, we propose to plug a Q-value regularization with double Q-learning strategy into the Decision Transformer backbone. This design enables joint optimization of policy imitation and action-value maximization, allowing the learned bidding policy to both leverage experience from the dataset and alleviate the adverse impact of the suboptimal trajectories. Furthermore, to safely explore the policy space beyond the data distribution, we propose a Q-value guided dual-exploration mechanism, in which the DT model is conditioned on multiple return-to-go targets and locally perturbed actions. This entire exploration process is dynamically guided by the aforementioned Q-value module, which provides principled evaluation for each candidate action. Experiments on public benchmarks and simulation environments demonstrate that QGA consistently achieves superior or highly competitive results compared to existing alternatives. Notably, in large-scale real-world A/B testing, QGA achieves a 3.27% increase in Ad GMV and a 2.49% improvement in Ad ROI.
COMPARE: Clinical Optimization with Modular Planning and Assessment via RAG-Enhanced AI-OCT: Superior Decision Support for Percutaneous Coronary Intervention Compared to ChatGPT-5 and Junior Operators
Dec 11, 2025Background: While intravascular imaging, particularly optical coherence tomography (OCT), improves percutaneous coronary intervention (PCI) outcomes, its interpretation is operator-dependent. General-purpose artificial intelligence (AI) shows promise but lacks domain-specific reliability. We evaluated the performance of CA-GPT, a novel large model deployed on an AI-OCT system, against that of the general-purpose ChatGPT-5 and junior physicians for OCT-guided PCI planning and assessment. Methods: In this single-center analysis of 96 patients who underwent OCT-guided PCI, the procedural decisions generated by the CA-GPT, ChatGPT-5, and junior physicians were compared with an expert-derived procedural record. Agreement was assessed using ten pre-specified metrics across pre-PCI and post-PCI phases. Results: For pre-PCI planning, CA-GPT demonstrated significantly higher median agreement scores (5[IQR 3.75-5]) compared to both ChatGPT-5 (3[2-4], P<0.001) and junior physicians (4[3-4], P<0.001). CA-GPT significantly outperformed ChatGPT-5 across all individual pre-PCI metrics and showed superior performance to junior physicians in stent diameter (90.3% vs. 72.2%, P<0.05) and length selection (80.6% vs. 52.8%, P<0.01). In post-PCI assessment, CA-GPT maintained excellent overall agreement (5[4.75-5]), significantly higher than both ChatGPT-5 (4[4-5], P<0.001) and junior physicians (5[4-5], P<0.05). Subgroup analysis confirmed CA-GPT's robust performance advantage in complex scenarios. Conclusion: The CA-GPT-based AI-OCT system achieved superior decision-making agreement versus a general-purpose large language model and junior physicians across both PCI planning and assessment phases. This approach provides a standardized and reliable method for intravascular imaging interpretation, demonstrating significant potential to augment operator expertise and optimize OCT-guided PCI.
A Survey on Remote Sensing Foundation Models: From Vision to Multimodality
Mar 28, 2025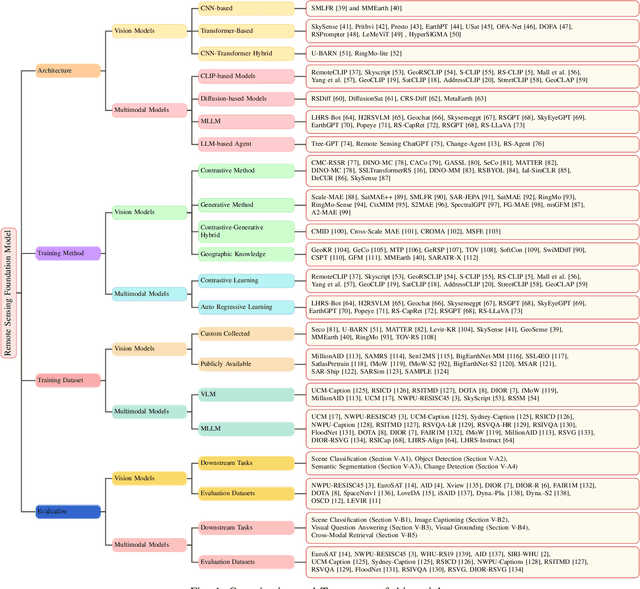
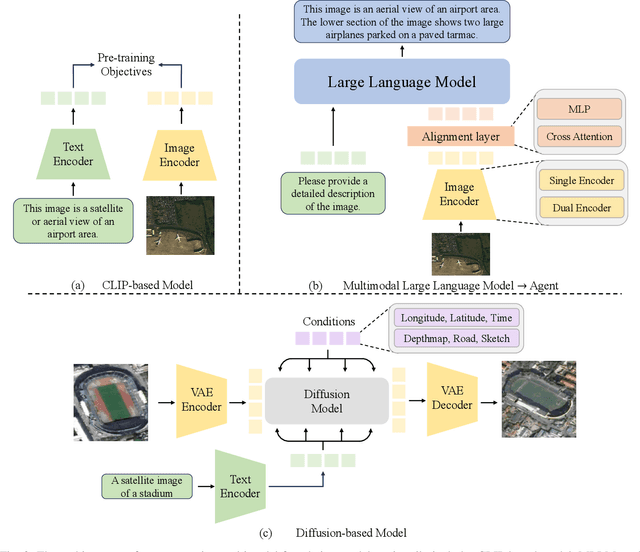

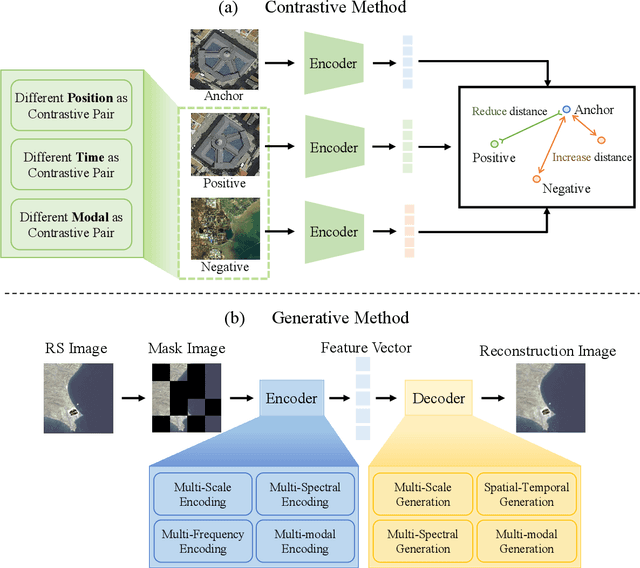
The rapid advancement of remote sensing foundation models, particularly vision and multimodal models, has significantly enhanced the capabilities of intelligent geospatial data interpretation. These models combine various data modalities, such as optical, radar, and LiDAR imagery, with textual and geographic information, enabling more comprehensive analysis and understanding of remote sensing data. The integration of multiple modalities allows for improved performance in tasks like object detection, land cover classification, and change detection, which are often challenged by the complex and heterogeneous nature of remote sensing data. However, despite these advancements, several challenges remain. The diversity in data types, the need for large-scale annotated datasets, and the complexity of multimodal fusion techniques pose significant obstacles to the effective deployment of these models. Moreover, the computational demands of training and fine-tuning multimodal models require significant resources, further complicating their practical application in remote sensing image interpretation tasks. This paper provides a comprehensive review of the state-of-the-art in vision and multimodal foundation models for remote sensing, focusing on their architecture, training methods, datasets and application scenarios. We discuss the key challenges these models face, such as data alignment, cross-modal transfer learning, and scalability, while also identifying emerging research directions aimed at overcoming these limitations. Our goal is to provide a clear understanding of the current landscape of remote sensing foundation models and inspire future research that can push the boundaries of what these models can achieve in real-world applications. The list of resources collected by the paper can be found in the https://github.com/IRIP-BUAA/A-Review-for-remote-sensing-vision-language-models.
Pushing DSP-Free Coherent Interconnect to the Last Inch by Optically Analog Signal Processing
Mar 14, 2025



To support the boosting interconnect capacity of the AI-related data centers, novel techniques enabled high-speed and low-cost optics are continuously emerging. When the baud rate approaches 200 GBaud per lane, the bottle-neck of traditional intensity modulation direct detection (IM-DD) architectures becomes increasingly evident. The simplified coherent solutions are widely discussed and considered as one of the most promising candidates. In this paper, a novel coherent architecture based on self-homodyne coherent detection and optically analog signal processing (OASP) is demonstrated. Proved by experiment, the first DSP-free baud-rate sampled 64-GBaud QPSK/16-QAM receptions are achieved, with BERs of 1e-6 and 2e-2, respectively. Even with 1-km fiber link propagation, the BER for QPSK reception remains at 3.6e-6. When an ultra-simple 1-sps SISO filter is utilized, the performance degradation of the proposed scheme is less than 1 dB compared to legacy DSP-based coherent reception. The proposed results pave the way for the ultra-high-speed coherent optical interconnections, offering high power and cost efficiency.