 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCoLa: Chinese Character Decomposition with Compositional Latent Components
Jun 04, 2025Humans can decompose Chinese characters into compositional components and recombine them to recognize unseen characters. This reflects two cognitive principles: Compositionality, the idea that complex concepts are built on simpler parts; and Learning-to-learn, the ability to learn strategies for decomposing and recombining components to form new concepts. These principles provide inductive biases that support efficient generalization. They are critical to Chinese character recognition (CCR) in solving the zero-shot problem, which results from the common long-tail distribution of Chinese character datasets. Existing methods have made substantial progress in modeling compositionality via predefined radical or stroke decomposition. However, they often ignore the learning-to-learn capability, limiting their ability to generalize beyond human-defined schemes. Inspired by these principles, we propose a deep latent variable model that learns Compositional Latent components of Chinese characters (CoLa) without relying on human-defined decomposition schemes. Recognition and matching can be performed by comparing compositional latent components in the latent space, enabling zero-shot character recognition. The experiments illustrate that CoLa outperforms previous methods in both character the radical zero-shot CCR. Visualization indicates that the learned components can reflect the structure of characters in an interpretable way. Moreover, despite being trained on historical documents, CoLa can analyze components of oracle bone characters, highlighting its cross-dataset generalization ability.
When Large Multimodal Models Confront Evolving Knowledge:Challenges and Pathways
May 30, 2025Large language/multimodal models (LLMs/LMMs) store extensive pre-trained knowledge but struggle to maintain consistency with real-world updates, making it difficult to avoid catastrophic forgetting while acquiring evolving knowledge. Previous work focused on constructing textual knowledge datasets and exploring knowledge injection in LLMs, lacking exploration of multimodal evolving knowledge injection in LMMs. To address this, we propose the EVOKE benchmark to evaluate LMMs' ability to inject multimodal evolving knowledge in real-world scenarios. Meanwhile, a comprehensive evaluation of multimodal evolving knowledge injection revealed two challenges: (1) Existing knowledge injection methods perform terribly on evolving knowledge. (2) Supervised fine-tuning causes catastrophic forgetting, particularly instruction following ability is severely compromised. Additionally, we provide pathways and find that: (1) Text knowledge augmentation during the training phase improves performance, while image augmentation cannot achieve it. (2) Continual learning methods, especially Replay and MoELoRA, effectively mitigate forgetting. Our findings indicate that current knowledge injection methods have many limitations on evolving knowledge, which motivates further research on more efficient and stable knowledge injection methods.
Autoregressive Meta-Actions for Unified Controllable Trajectory Generation
May 29, 2025



Controllable trajectory generation guided by high-level semantic decisions, termed meta-actions, is crucial for autonomous driving systems. A significant limitation of existing frameworks is their reliance on invariant meta-actions assigned over fixed future time intervals, causing temporal misalignment with the actual behavior trajectories. This misalignment leads to irrelevant associations between the prescribed meta-actions and the resulting trajectories, disrupting task coherence and limiting model performance. To address this challenge, we introduce Autoregressive Meta-Actions, an approach integrated into autoregressive trajectory generation frameworks that provides a unified and precise definition for meta-action-conditioned trajectory prediction. Specifically, We decompose traditional long-interval meta-actions into frame-level meta-actions, enabling a sequential interplay between autoregressive meta-action prediction and meta-action-conditioned trajectory generation. This decomposition ensures strict alignment between each trajectory segment and its corresponding meta-action, achieving a consistent and unified task formulation across the entire trajectory span and significantly reducing complexity. Moreover, we propose a staged pre-training process to decouple the learning of basic motion dynamics from the integration of high-level decision control, which offers flexibility, stability, and modularity. Experimental results validate our framework's effectiveness, demonstrating improved trajectory adaptivity and responsiveness to dynamic decision-making scenarios. We provide the video document and dataset, which are available at https://arma-traj.github.io/.
Wireless Communication for Low-Altitude Economy with UAV Swarm Enabled Two-Level Movable Antenna System
May 28, 2025Unmanned aerial vehicle (UAV) is regarded as a key enabling platform for low-altitude economy, due to its advantages such as 3D maneuverability, flexible deployment, and LoS air-to-air/ground communication links. In particular, the intrinsic high mobility renders UAV especially suitable for operating as a movable antenna (MA) from the sky. In this paper, by exploiting the flexible mobility of UAV swarm and antenna position adjustment of MA, we propose a novel UAV swarm enabled two-level MA system, where UAVs not only individually deploy a local MA array, but also form a larger-scale MA system with their individual MA arrays via swarm coordination. We formulate a general optimization problem to maximize the minimum achievable rate over all ground UEs, by jointly optimizing the 3D UAV swarm placement positions, their individual MAs' positions, and receive beamforming for different UEs. We first consider the special case where each UAV has only one antenna, under different scenarios of one single UE, two UEs, and arbitrary number of UEs. In particular, for the two-UE case, we derive the optimal UAV swarm placement positions in closed-form that achieves IUI-free communication, where the UAV swarm forms a uniform sparse array (USA) satisfying collision avoidance constraint. While for the general case with arbitrary number of UEs, we propose an efficient alternating optimization algorithm to solve the formulated non-convex optimization problem. Then, we extend the results to the case where each UAV is equipped with multiple antennas. Numerical results verify that the proposed low-altitude UAV swarm enabled MA system significantly outperforms various benchmark schemes, thanks to the exploitation of two-level mobility to create more favorable channel conditions for multi-UE communications.
UDuo: Universal Dual Optimization Framework for Online Matching
May 28, 2025Online resource allocation under budget constraints critically depends on proper modeling of user arrival dynamics. Classical approaches employ stochastic user arrival models to derive near-optimal solutions through fractional matching formulations of exposed users for downstream allocation tasks. However, this is no longer a reasonable assumption when the environment changes dynamically. In this work, We propose the Universal Dual optimization framework UDuo, a novel paradigm that fundamentally rethinks online allocation through three key innovations: (i) a temporal user arrival representation vector that explicitly captures distribution shifts in user arrival patterns and resource consumption dynamics, (ii) a resource pacing learner with adaptive allocation policies that generalize to heterogeneous constraint scenarios, and (iii) an online time-series forecasting approach for future user arrival distributions that achieves asymptotically optimal solutions with constraint feasibility guarantees in dynamic environments. Experimental results show that UDuo achieves higher efficiency and faster convergence than the traditional stochastic arrival model in real-world pricing while maintaining rigorous theoretical validity for general online allocation problems.
StyleAR: Customizing Multimodal Autoregressive Model for Style-Aligned Text-to-Image Generation
May 26, 2025
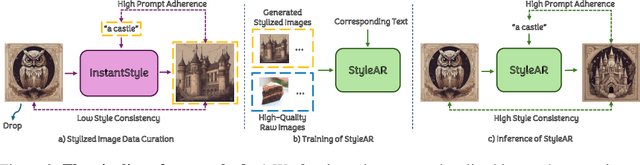

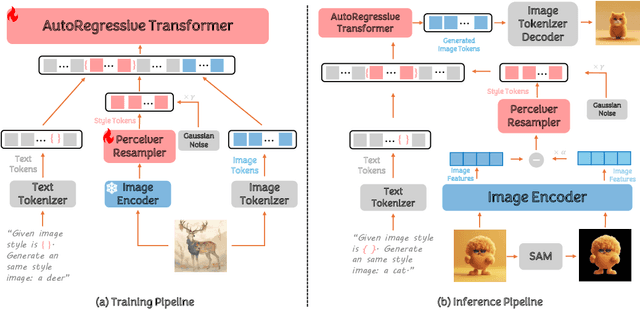
In the current research landscape, multimodal autoregressive (AR) models have shown exceptional capabilities across various domains, including visual understanding and generation. However, complex tasks such as style-aligned text-to-image generation present significant challenges, particularly in data acquisition. In analogy to instruction-following tuning for image editing of AR models, style-aligned generation requires a reference style image and prompt, resulting in a text-image-to-image triplet where the output shares the style and semantics of the input. However, acquiring large volumes of such triplet data with specific styles is considerably more challenging than obtaining conventional text-to-image data used for training generative models. To address this issue, we propose StyleAR, an innovative approach that combines a specially designed data curation method with our proposed AR models to effectively utilize text-to-image binary data for style-aligned text-to-image generation. Our method synthesizes target stylized data using a reference style image and prompt, but only incorporates the target stylized image as the image modality to create high-quality binary data. To facilitate binary data training, we introduce a CLIP image encoder with a perceiver resampler that translates the image input into style tokens aligned with multimodal tokens in AR models and implement a style-enhanced token technique to prevent content leakage which is a common issue in previous work. Furthermore, we mix raw images drawn from large-scale text-image datasets with stylized images to enhance StyleAR's ability to extract richer stylistic features and ensure style consistency. Extensive qualitative and quantitative experiments demonstrate our superior performance.
Guard Me If You Know Me: Protecting Specific Face-Identity from Deepfakes
May 26, 2025Securing personal identity against deepfake attacks is increasingly critical in the digital age, especially for celebrities and political figures whose faces are easily accessible and frequently targeted. Most existing deepfake detection methods focus on general-purpose scenarios and often ignore the valuable prior knowledge of known facial identities, e.g., "VIP individuals" whose authentic facial data are already available. In this paper, we propose \textbf{VIPGuard}, a unified multimodal framework designed to capture fine-grained and comprehensive facial representations of a given identity, compare them against potentially fake or similar-looking faces, and reason over these comparisons to make accurate and explainable predictions. Specifically, our framework consists of three main stages. First, fine-tune a multimodal large language model (MLLM) to learn detailed and structural facial attributes. Second, we perform identity-level discriminative learning to enable the model to distinguish subtle differences between highly similar faces, including real and fake variations. Finally, we introduce user-specific customization, where we model the unique characteristics of the target face identity and perform semantic reasoning via MLLM to enable personalized and explainable deepfake detection. Our framework shows clear advantages over previous detection works, where traditional detectors mainly rely on low-level visual cues and provide no human-understandable explanations, while other MLLM-based models often lack a detailed understanding of specific face identities. To facilitate the evaluation of our method, we built a comprehensive identity-aware benchmark called \textbf{VIPBench} for personalized deepfake detection, involving the latest 7 face-swapping and 7 entire face synthesis techniques for generation.
Deep Video Discovery: Agentic Search with Tool Use for Long-form Video Understanding
May 23, 2025Long-form video understanding presents significant challenges due to extensive temporal-spatial complexity and the difficulty of question answering under such extended contexts. While Large Language Models (LLMs) have demonstrated considerable advancements in video analysis capabilities and long context handling, they continue to exhibit limitations when processing information-dense hour-long videos. To overcome such limitations, we propose the Deep Video Discovery agent to leverage an agentic search strategy over segmented video clips. Different from previous video agents manually designing a rigid workflow, our approach emphasizes the autonomous nature of agents. By providing a set of search-centric tools on multi-granular video database, our DVD agent leverages the advanced reasoning capability of LLM to plan on its current observation state, strategically selects tools, formulates appropriate parameters for actions, and iteratively refines its internal reasoning in light of the gathered information. We perform comprehensive evaluation on multiple long video understanding benchmarks that demonstrates the advantage of the entire system design. Our DVD agent achieves SOTA performance, significantly surpassing prior works by a large margin on the challenging LVBench dataset. Comprehensive ablation studies and in-depth tool analyses are also provided, yielding insights to further advance intelligent agents tailored for long-form video understanding tasks. The code will be released later.
One-Step Diffusion-Based Image Compression with Semantic Distillation
May 22, 2025While recent diffusion-based generative image codecs have shown impressive performance, their iterative sampling process introduces unpleasing latency. In this work, we revisit the design of a diffusion-based codec and argue that multi-step sampling is not necessary for generative compression. Based on this insight, we propose OneDC, a One-step Diffusion-based generative image Codec -- that integrates a latent compression module with a one-step diffusion generator. Recognizing the critical role of semantic guidance in one-step diffusion, we propose using the hyperprior as a semantic signal, overcoming the limitations of text prompts in representing complex visual content. To further enhance the semantic capability of the hyperprior, we introduce a semantic distillation mechanism that transfers knowledge from a pretrained generative tokenizer to the hyperprior codec. Additionally, we adopt a hybrid pixel- and latent-domain optimization to jointly enhance both reconstruction fidelity and perceptual realism. Extensive experiments demonstrate that OneDC achieves SOTA perceptual quality even with one-step generation, offering over 40% bitrate reduction and 20x faster decoding compared to prior multi-step diffusion-based codecs. Code will be released later.
Generative Latent Coding for Ultra-Low Bitrate Image and Video Compression
May 22, 2025Most existing approaches for image and video compression perform transform coding in the pixel space to reduce redundancy. However, due to the misalignment between the pixel-space distortion and human perception, such schemes often face the difficulties in achieving both high-realism and high-fidelity at ultra-low bitrate. To solve this problem, we propose \textbf{G}enerative \textbf{L}atent \textbf{C}oding (\textbf{GLC}) models for image and video compression, termed GLC-image and GLC-Video. The transform coding of GLC is conducted in the latent space of a generative vector-quantized variational auto-encoder (VQ-VAE). Compared to the pixel-space, such a latent space offers greater sparsity, richer semantics and better alignment with human perception, and show its advantages in achieving high-realism and high-fidelity compression. To further enhance performance, we improve the hyper prior by introducing a spatial categorical hyper module in GLC-image and a spatio-temporal categorical hyper module in GLC-video. Additionally, the code-prediction-based loss function is proposed to enhance the semantic consistency. Experiments demonstrate that our scheme shows high visual quality at ultra-low bitrate for both image and video compression. For image compression, GLC-image achieves an impressive bitrate of less than $0.04$ bpp, achieving the same FID as previous SOTA model MS-ILLM while using $45\%$ fewer bitrate on the CLIC 2020 test set. For video compression, GLC-video achieves 65.3\% bitrate saving over PLVC in terms of DISTS.