 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRecurrent Bilinear Optimization for Binary Neural Networks
Sep 04, 2022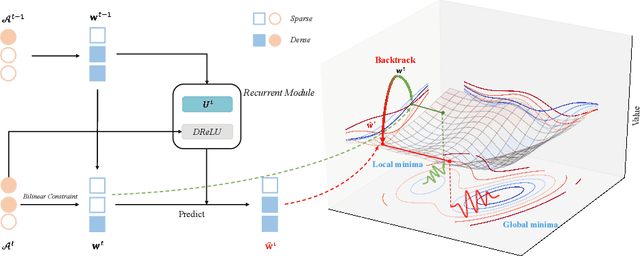
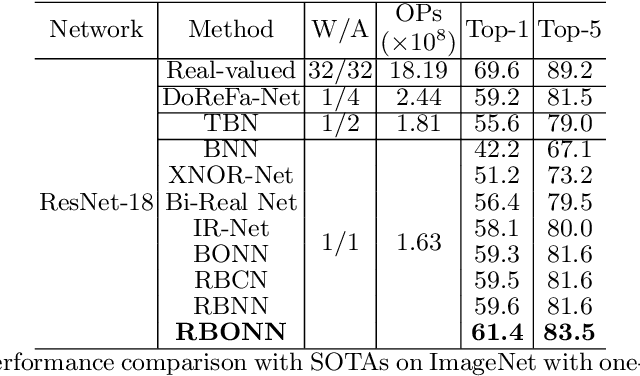

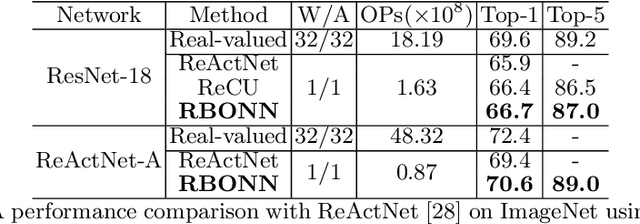
Binary Neural Networks (BNNs) show great promise for real-world embedded devices. As one of the critical steps to achieve a powerful BNN, the scale factor calculation plays an essential role in reducing the performance gap to their real-valued counterparts. However, existing BNNs neglect the intrinsic bilinear relationship of real-valued weights and scale factors, resulting in a sub-optimal model caused by an insufficient training process. To address this issue, Recurrent Bilinear Optimization is proposed to improve the learning process of BNNs (RBONNs) by associating the intrinsic bilinear variables in the back propagation process. Our work is the first attempt to optimize BNNs from the bilinear perspective. Specifically, we employ a recurrent optimization and Density-ReLU to sequentially backtrack the sparse real-valued weight filters, which will be sufficiently trained and reach their performance limits based on a controllable learning process. We obtain robust RBONNs, which show impressive performance over state-of-the-art BNNs on various models and datasets. Particularly, on the task of object detection, RBONNs have great generalization performance. Our code is open-sourced on https://github.com/SteveTsui/RBONN .
Anti-Retroactive Interference for Lifelong Learning
Aug 27, 2022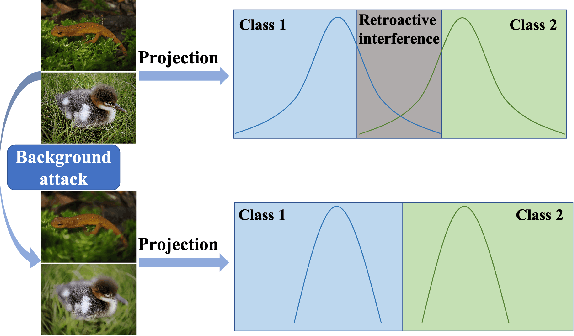
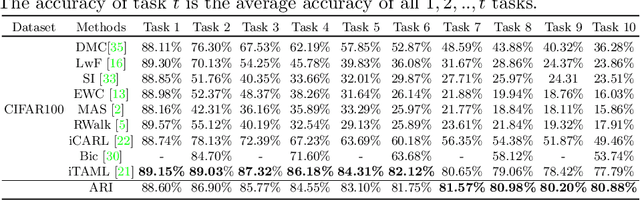
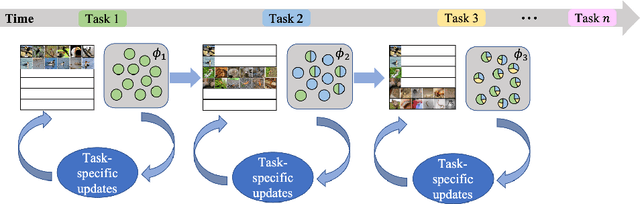

Humans can continuously learn new knowledge. However, machine learning models suffer from drastic dropping in performance on previous tasks after learning new tasks. Cognitive science points out that the competition of similar knowledge is an important cause of forgetting. In this paper, we design a paradigm for lifelong learning based on meta-learning and associative mechanism of the brain. It tackles the problem from two aspects: extracting knowledge and memorizing knowledge. First, we disrupt the sample's background distribution through a background attack, which strengthens the model to extract the key features of each task. Second, according to the similarity between incremental knowledge and base knowledge, we design an adaptive fusion of incremental knowledge, which helps the model allocate capacity to the knowledge of different difficulties. It is theoretically analyzed that the proposed learning paradigm can make the models of different tasks converge to the same optimum. The proposed method is validated on the MNIST, CIFAR100, CUB200 and ImageNet100 datasets.
Bi-level Doubly Variational Learning for Energy-based Latent Variable Models
Mar 24, 2022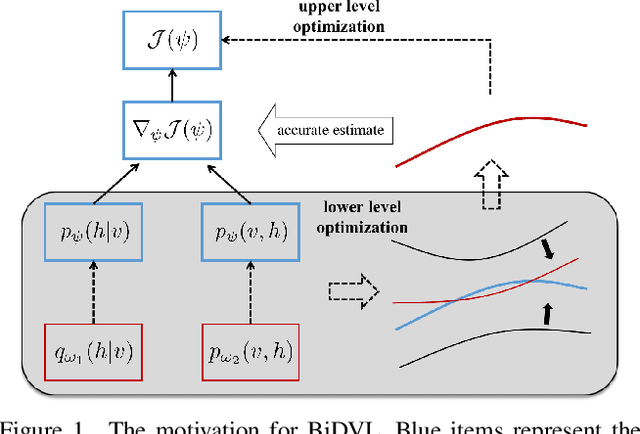

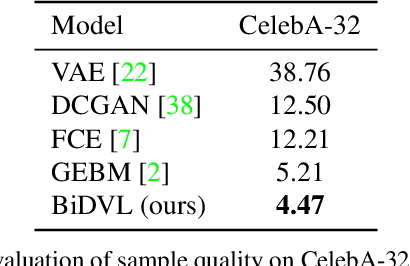

Energy-based latent variable models (EBLVMs) are more expressive than conventional energy-based models. However, its potential on visual tasks are limited by its training process based on maximum likelihood estimate that requires sampling from two intractable distributions. In this paper, we propose Bi-level doubly variational learning (BiDVL), which is based on a new bi-level optimization framework and two tractable variational distributions to facilitate learning EBLVMs. Particularly, we lead a decoupled EBLVM consisting of a marginal energy-based distribution and a structural posterior to handle the difficulties when learning deep EBLVMs on images. By choosing a symmetric KL divergence in the lower level of our framework, a compact BiDVL for visual tasks can be obtained. Our model achieves impressive image generation performance over related works. It also demonstrates the significant capacity of testing image reconstruction and out-of-distribution detection.
Confidence Dimension for Deep Learning based on Hoeffding Inequality and Relative Evaluation
Mar 17, 2022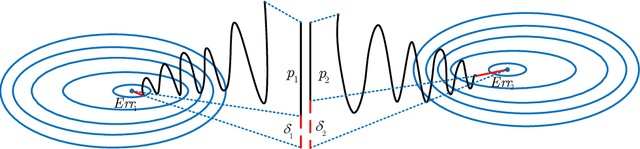
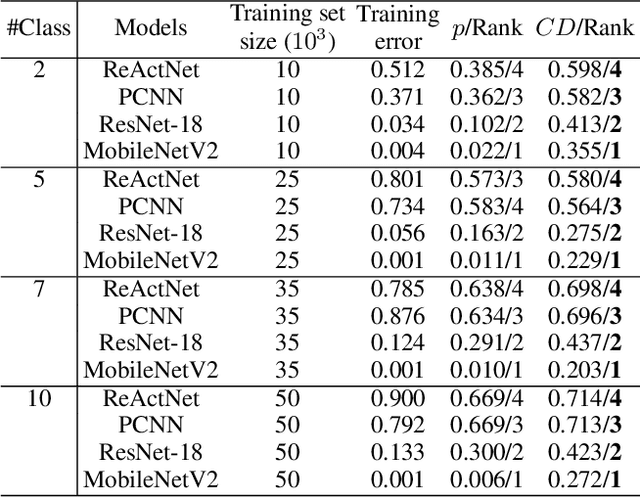
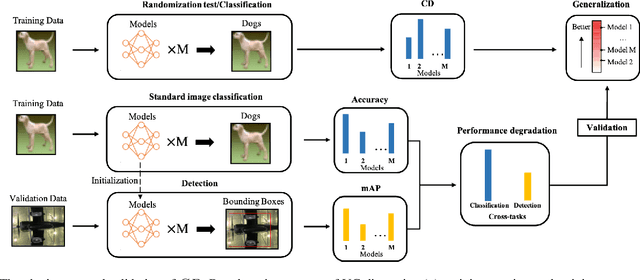
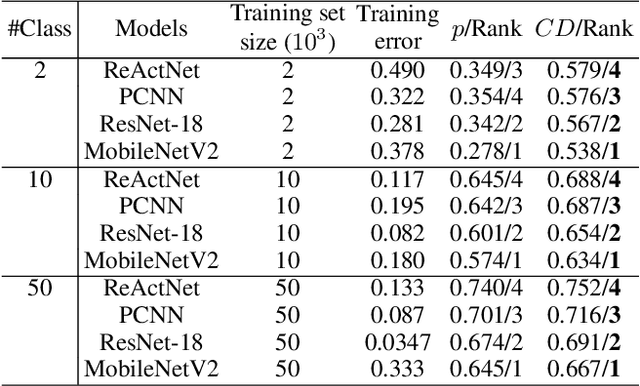
Research on the generalization ability of deep neural networks (DNNs) has recently attracted a great deal of attention. However, due to their complex architectures and large numbers of parameters, measuring the generalization ability of specific DNN models remains an open challenge. In this paper, we propose to use multiple factors to measure and rank the relative generalization of DNNs based on a new concept of confidence dimension (CD). Furthermore, we provide a feasible framework in our CD to theoretically calculate the upper bound of generalization based on the conventional Vapnik-Chervonenk dimension (VC-dimension) and Hoeffding's inequality. Experimental results on image classification and object detection demonstrate that our CD can reflect the relative generalization ability for different DNNs. In addition to full-precision DNNs, we also analyze the generalization ability of binary neural networks (BNNs), whose generalization ability remains an unsolved problem. Our CD yields a consistent and reliable measure and ranking for both full-precision DNNs and BNNs on all the tasks.
TerViT: An Efficient Ternary Vision Transformer
Jan 21, 2022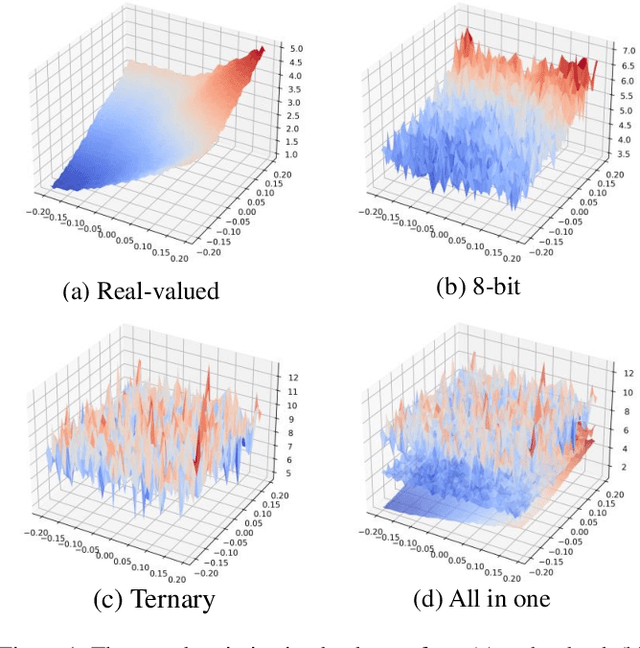
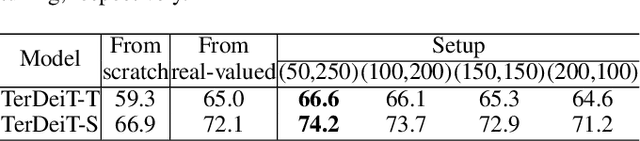
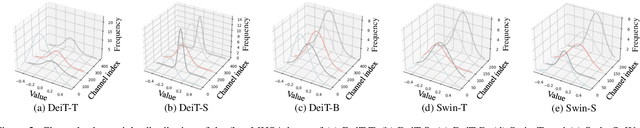

Vision transformers (ViTs) have demonstrated great potential in various visual tasks, but suffer from expensive computational and memory cost problems when deployed on resource-constrained devices. In this paper, we introduce a ternary vision transformer (TerViT) to ternarize the weights in ViTs, which are challenged by the large loss surface gap between real-valued and ternary parameters. To address the issue, we introduce a progressive training scheme by first training 8-bit transformers and then TerViT, and achieve a better optimization than conventional methods. Furthermore, we introduce channel-wise ternarization, by partitioning each matrix to different channels, each of which is with an unique distribution and ternarization interval. We apply our methods to popular DeiT and Swin backbones, and extensive results show that we can achieve competitive performance. For example, TerViT can quantize Swin-S to 13.1MB model size while achieving above 79% Top-1 accuracy on ImageNet dataset.
Associative Adversarial Learning Based on Selective Attack
Jan 04, 2022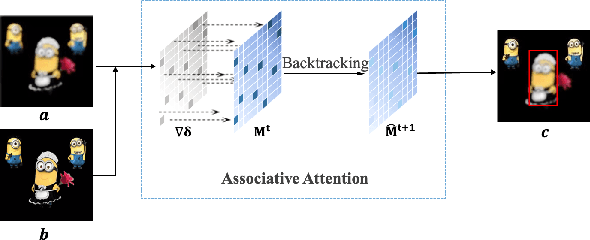
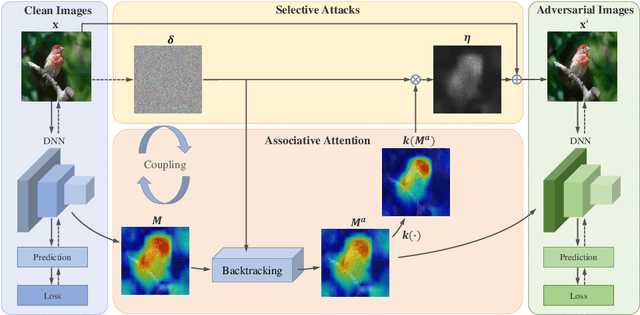
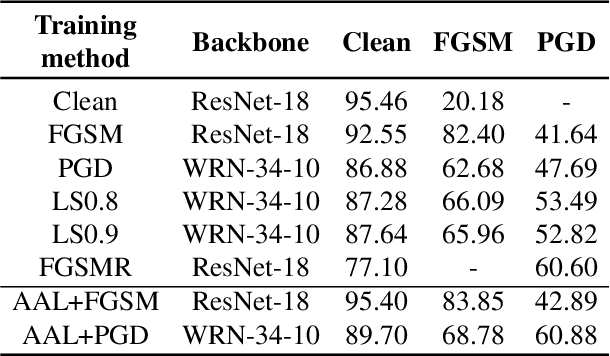
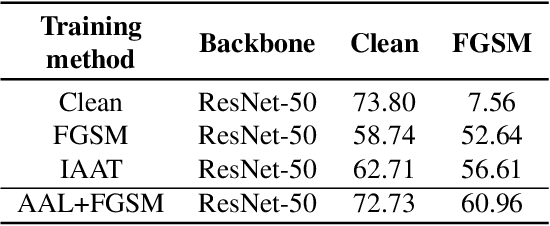
A human's attention can intuitively adapt to corrupted areas of an image by recalling a similar uncorrupted image they have previously seen. This observation motivates us to improve the attention of adversarial images by considering their clean counterparts. To accomplish this, we introduce Associative Adversarial Learning (AAL) into adversarial learning to guide a selective attack. We formulate the intrinsic relationship between attention and attack (perturbation) as a coupling optimization problem to improve their interaction. This leads to an attention backtracking algorithm that can effectively enhance the attention's adversarial robustness. Our method is generic and can be used to address a variety of tasks by simply choosing different kernels for the associative attention that select other regions for a specific attack. Experimental results show that the selective attack improves the model's performance. We show that our method improves the recognition accuracy of adversarial training on ImageNet by 8.32% compared with the baseline. It also increases object detection mAP on PascalVOC by 2.02% and recognition accuracy of few-shot learning on miniImageNet by 1.63%.
Self-Supervised Monocular Depth and Ego-Motion Estimation in Endoscopy: Appearance Flow to the Rescue
Dec 15, 2021
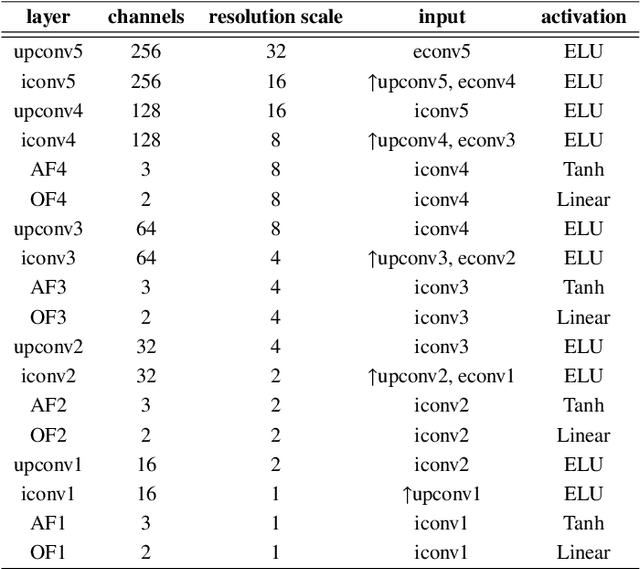
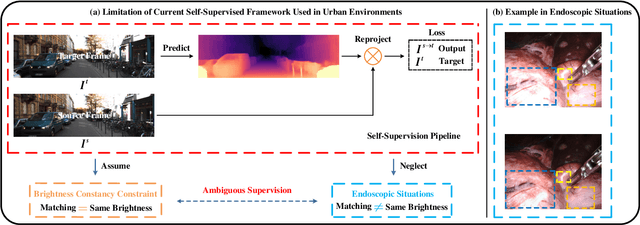

Recently, self-supervised learning technology has been applied to calculate depth and ego-motion from monocular videos, achieving remarkable performance in autonomous driving scenarios. One widely adopted assumption of depth and ego-motion self-supervised learning is that the image brightness remains constant within nearby frames. Unfortunately, the endoscopic scene does not meet this assumption because there are severe brightness fluctuations induced by illumination variations, non-Lambertian reflections and interreflections during data collection, and these brightness fluctuations inevitably deteriorate the depth and ego-motion estimation accuracy. In this work, we introduce a novel concept referred to as appearance flow to address the brightness inconsistency problem. The appearance flow takes into consideration any variations in the brightness pattern and enables us to develop a generalized dynamic image constraint. Furthermore, we build a unified self-supervised framework to estimate monocular depth and ego-motion simultaneously in endoscopic scenes, which comprises a structure module, a motion module, an appearance module and a correspondence module, to accurately reconstruct the appearance and calibrate the image brightness. Extensive experiments are conducted on the SCARED dataset and EndoSLAM dataset, and the proposed unified framework exceeds other self-supervised approaches by a large margin. To validate our framework's generalization ability on different patients and cameras, we train our model on SCARED but test it on the SERV-CT and Hamlyn datasets without any fine-tuning, and the superior results reveal its strong generalization ability. Code will be available at: \url{https://github.com/ShuweiShao/AF-SfMLearner}.
IntraQ: Learning Synthetic Images with Intra-Class Heterogeneity for Zero-Shot Network Quantization
Dec 03, 2021
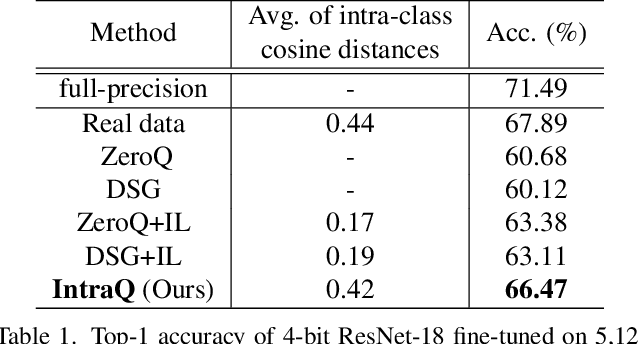
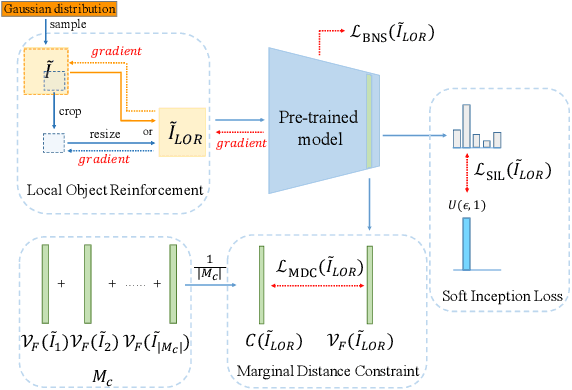
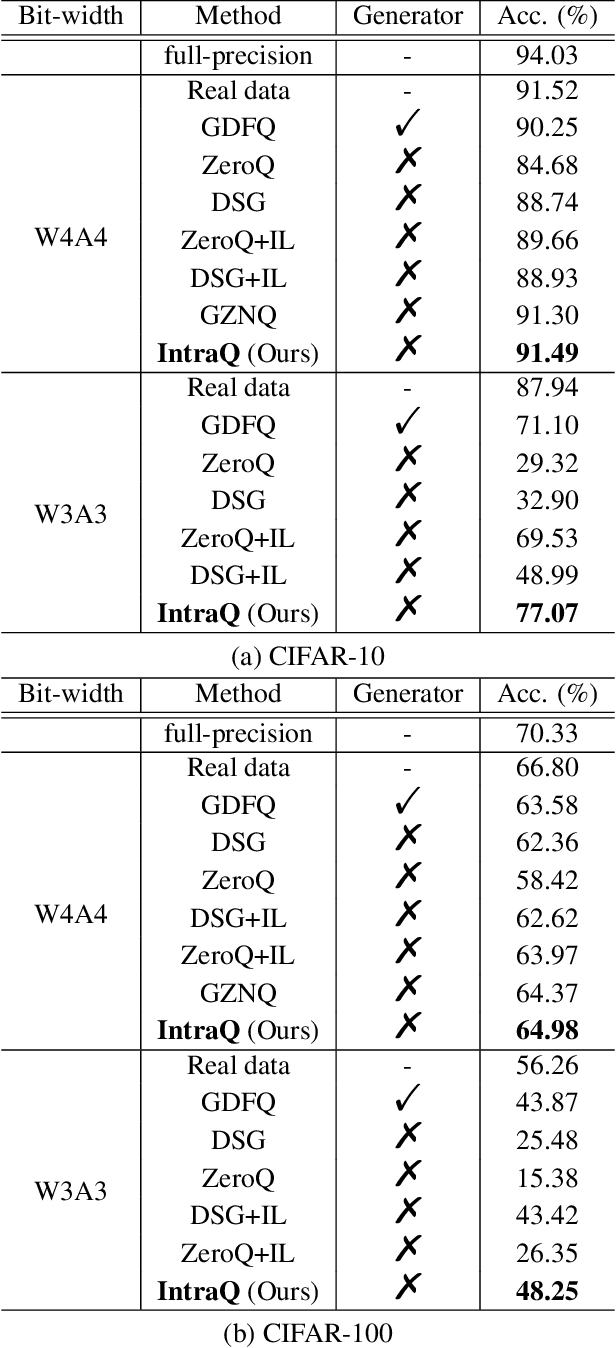
Learning to synthesize data has emerged as a promising direction in zero-shot quantization (ZSQ), which represents neural networks by low-bit integer without accessing any of the real data. In this paper, we observe an interesting phenomenon of intra-class heterogeneity in real data and show that existing methods fail to retain this property in their synthetic images, which causes a limited performance increase. To address this issue, we propose a novel zero-shot quantization method referred to as IntraQ. First, we propose a local object reinforcement that locates the target objects at different scales and positions of the synthetic images. Second, we introduce a marginal distance constraint to form class-related features distributed in a coarse area. Lastly, we devise a soft inception loss which injects a soft prior label to prevent the synthetic images from being overfitting to a fixed object. Our IntraQ is demonstrated to well retain the intra-class heterogeneity in the synthetic images and also observed to perform state-of-the-art. For example, compared to the advanced ZSQ, our IntraQ obtains 9.17\% increase of the top-1 accuracy on ImageNet when all layers of MobileNetV1 are quantized to 4-bit. Code is at https://github.com/zysxmu/InterQ.
POEM: 1-bit Point-wise Operations based on Expectation-Maximization for Efficient Point Cloud Processing
Nov 26, 2021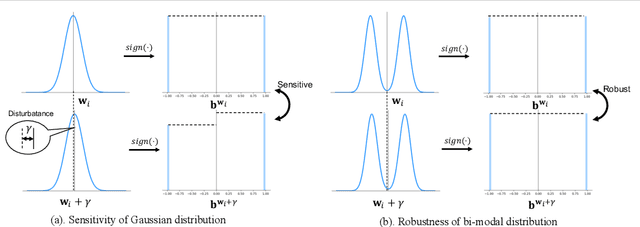
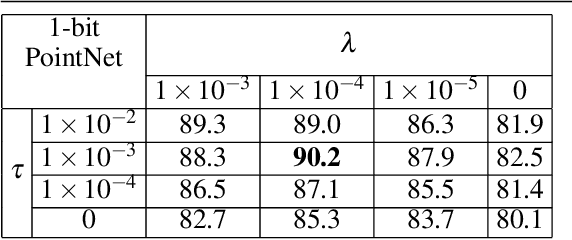
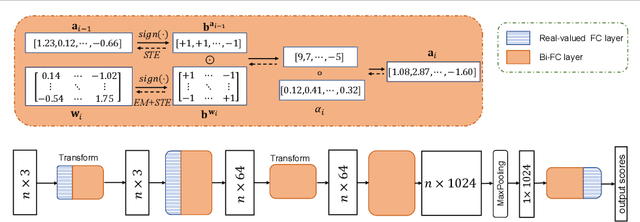

Real-time point cloud processing is fundamental for lots of computer vision tasks, while still challenged by the computational problem on resource-limited edge devices. To address this issue, we implement XNOR-Net-based binary neural networks (BNNs) for an efficient point cloud processing, but its performance is severely suffered due to two main drawbacks, Gaussian-distributed weights and non-learnable scale factor. In this paper, we introduce point-wise operations based on Expectation-Maximization (POEM) into BNNs for efficient point cloud processing. The EM algorithm can efficiently constrain weights for a robust bi-modal distribution. We lead a well-designed reconstruction loss to calculate learnable scale factors to enhance the representation capacity of 1-bit fully-connected (Bi-FC) layers. Extensive experiments demonstrate that our POEM surpasses existing the state-of-the-art binary point cloud networks by a significant margin, up to 6.7 %.
NENet: Monocular Depth Estimation via Neural Ensembles
Nov 16, 2021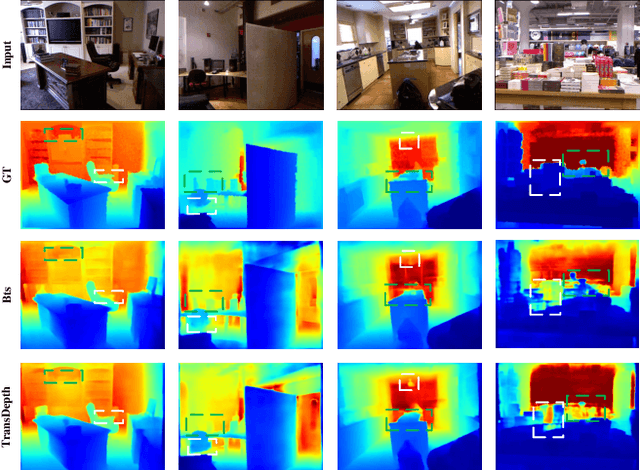
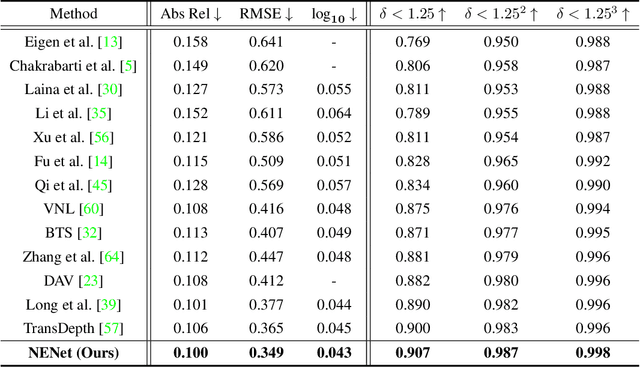
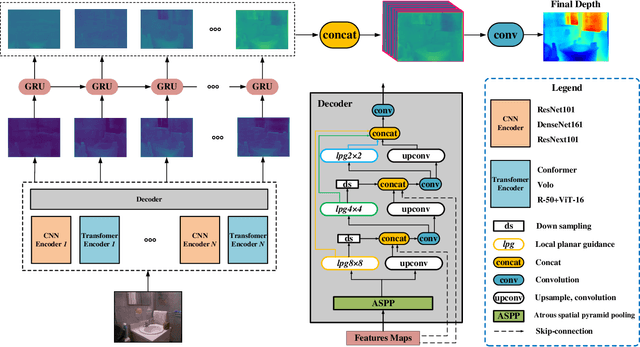
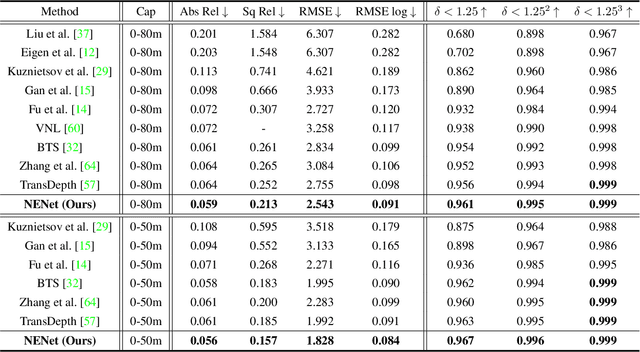
Depth estimation is getting a widespread popularity in the computer vision community, and it is still quite difficult to recover an accurate depth map using only one single RGB image. In this work, we observe a phenomenon that existing methods tend to exhibit asymmetric errors, which might open up a new direction for accurate and robust depth estimation. We carefully investigate into the phenomenon, and construct a two-level ensemble scheme, NENet, to integrate multiple predictions from diverse base predictors. The NENet forms a more reliable depth estimator, which substantially boosts the performance over base predictors. Notably, this is the first attempt to introduce ensemble learning and evaluate its utility for monocular depth estimation to the best of our knowledge. Extensive experiments demonstrate that the proposed NENet achieves better results than previous state-of-the-art approaches on the NYU-Depth-v2 and KITTI datasets. In particular, our method improves previous state-of-the-art methods from 0.365 to 0.349 on the metric RMSE on the NYU dataset. To validate the generalizability across cameras, we directly apply the models trained on the NYU dataset to the SUN RGB-D dataset without any fine-tuning, and achieve the superior results, which indicate its strong generalizability. The source code and trained models will be publicly available upon the acceptance.