 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSurf3R: Rapid Surface Reconstruction from Sparse RGB Views in Seconds
Aug 06, 2025



Current multi-view 3D reconstruction methods rely on accurate camera calibration and pose estimation, requiring complex and time-intensive pre-processing that hinders their practical deployment. To address this challenge, we introduce Surf3R, an end-to-end feedforward approach that reconstructs 3D surfaces from sparse views without estimating camera poses and completes an entire scene in under 10 seconds. Our method employs a multi-branch and multi-view decoding architecture in which multiple reference views jointly guide the reconstruction process. Through the proposed branch-wise processing, cross-view attention, and inter-branch fusion, the model effectively captures complementary geometric cues without requiring camera calibration. Moreover, we introduce a D-Normal regularizer based on an explicit 3D Gaussian representation for surface reconstruction. It couples surface normals with other geometric parameters to jointly optimize the 3D geometry, significantly improving 3D consistency and surface detail accuracy. Experimental results demonstrate that Surf3R achieves state-of-the-art performance on multiple surface reconstruction metrics on ScanNet++ and Replica datasets, exhibiting excellent generalization and efficiency.
Squeeze10-LLM: Squeezing LLMs' Weights by 10 Times via a Staged Mixed-Precision Quantization Method
Jul 24, 2025Deploying large language models (LLMs) is challenging due to their massive parameters and high computational costs. Ultra low-bit quantization can significantly reduce storage and accelerate inference, but extreme compression (i.e., mean bit-width <= 2) often leads to severe performance degradation. To address this, we propose Squeeze10-LLM, effectively "squeezing" 16-bit LLMs' weights by 10 times. Specifically, Squeeze10-LLM is a staged mixed-precision post-training quantization (PTQ) framework and achieves an average of 1.6 bits per weight by quantizing 80% of the weights to 1 bit and 20% to 4 bits. We introduce Squeeze10LLM with two key innovations: Post-Binarization Activation Robustness (PBAR) and Full Information Activation Supervision (FIAS). PBAR is a refined weight significance metric that accounts for the impact of quantization on activations, improving accuracy in low-bit settings. FIAS is a strategy that preserves full activation information during quantization to mitigate cumulative error propagation across layers. Experiments on LLaMA and LLaMA2 show that Squeeze10-LLM achieves state-of-the-art performance for sub-2bit weight-only quantization, improving average accuracy from 43% to 56% on six zero-shot classification tasks--a significant boost over existing PTQ methods. Our code will be released upon publication.
Light of Normals: Unified Feature Representation for Universal Photometric Stereo
Jun 24, 2025



Universal photometric stereo (PS) aims to recover high-quality surface normals from objects under arbitrary lighting conditions without relying on specific illumination models. Despite recent advances such as SDM-UniPS and Uni MS-PS, two fundamental challenges persist: 1) the deep coupling between varying illumination and surface normal features, where ambiguity in observed intensity makes it difficult to determine whether brightness variations stem from lighting changes or surface orientation; and 2) the preservation of high-frequency geometric details in complex surfaces, where intricate geometries create self-shadowing, inter-reflections, and subtle normal variations that conventional feature processing operations struggle to capture accurately.
Enhancing point cloud analysis via neighbor aggregation correction based on cross-stage structure correlation
Jun 18, 2025Point cloud analysis is the cornerstone of many downstream tasks, among which aggregating local structures is the basis for understanding point cloud data. While numerous works aggregate neighbor using three-dimensional relative coordinates, there are irrelevant point interference and feature hierarchy gap problems due to the limitation of local coordinates. Although some works address this limitation by refining spatial description though explicit modeling of cross-stage structure, these enhancement methods based on direct geometric structure encoding have problems of high computational overhead and noise sensitivity. To overcome these problems, we propose the Point Distribution Set Abstraction module (PDSA) that utilizes the correlation in the high-dimensional space to correct the feature distribution during aggregation, which improves the computational efficiency and robustness. PDSA distinguishes the point correlation based on a lightweight cross-stage structural descriptor, and enhances structural homogeneity by reducing the variance of the neighbor feature matrix and increasing classes separability though long-distance modeling. Additionally, we introducing a key point mechanism to optimize the computational overhead. The experimental result on semantic segmentation and classification tasks based on different baselines verify the generalization of the method we proposed, and achieve significant performance improvement with less parameter cost. The corresponding ablation and visualization results demonstrate the effectiveness and rationality of our method. The code and training weight is available at: https://github.com/AGENT9717/PointDistribution
HRGS: Hierarchical Gaussian Splatting for Memory-Efficient High-Resolution 3D Reconstruction
Jun 17, 2025



3D Gaussian Splatting (3DGS) has made significant strides in real-time 3D scene reconstruction, but faces memory scalability issues in high-resolution scenarios. To address this, we propose Hierarchical Gaussian Splatting (HRGS), a memory-efficient framework with hierarchical block-level optimization. First, we generate a global, coarse Gaussian representation from low-resolution data. Then, we partition the scene into multiple blocks, refining each block with high-resolution data. The partitioning involves two steps: Gaussian partitioning, where irregular scenes are normalized into a bounded cubic space with a uniform grid for task distribution, and training data partitioning, where only relevant observations are retained for each block. By guiding block refinement with the coarse Gaussian prior, we ensure seamless Gaussian fusion across adjacent blocks. To reduce computational demands, we introduce Importance-Driven Gaussian Pruning (IDGP), which computes importance scores for each Gaussian and removes those with minimal contribution, speeding up convergence and reducing memory usage. Additionally, we incorporate normal priors from a pretrained model to enhance surface reconstruction quality. Our method enables high-quality, high-resolution 3D scene reconstruction even under memory constraints. Extensive experiments on three benchmarks show that HRGS achieves state-of-the-art performance in high-resolution novel view synthesis (NVS) and surface reconstruction tasks.
Prompt as Knowledge Bank: Boost Vision-language model via Structural Representation for zero-shot medical detection
Feb 22, 2025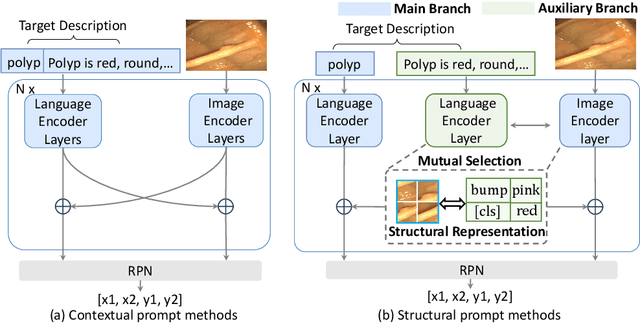
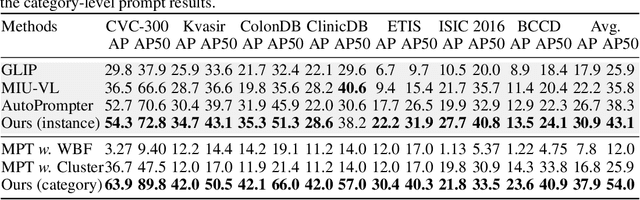
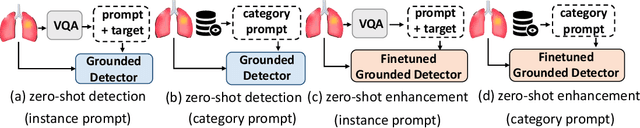
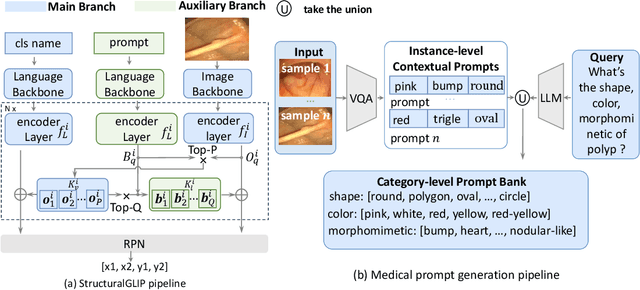
Zero-shot medical detection can further improve detection performance without relying on annotated medical images even upon the fine-tuned model, showing great clinical value. Recent studies leverage grounded vision-language models (GLIP) to achieve this by using detailed disease descriptions as prompts for the target disease name during the inference phase. However, these methods typically treat prompts as equivalent context to the target name, making it difficult to assign specific disease knowledge based on visual information, leading to a coarse alignment between images and target descriptions. In this paper, we propose StructuralGLIP, which introduces an auxiliary branch to encode prompts into a latent knowledge bank layer-by-layer, enabling more context-aware and fine-grained alignment. Specifically, in each layer, we select highly similar features from both the image representation and the knowledge bank, forming structural representations that capture nuanced relationships between image patches and target descriptions. These features are then fused across modalities to further enhance detection performance. Extensive experiments demonstrate that StructuralGLIP achieves a +4.1\% AP improvement over prior state-of-the-art methods across seven zero-shot medical detection benchmarks, and consistently improves fine-tuned models by +3.2\% AP on endoscopy image datasets.
DAMamba: Vision State Space Model with Dynamic Adaptive Scan
Feb 18, 2025



State space models (SSMs) have recently garnered significant attention in computer vision. However, due to the unique characteristics of image data, adapting SSMs from natural language processing to computer vision has not outperformed the state-of-the-art convolutional neural networks (CNNs) and Vision Transformers (ViTs). Existing vision SSMs primarily leverage manually designed scans to flatten image patches into sequences locally or globally. This approach disrupts the original semantic spatial adjacency of the image and lacks flexibility, making it difficult to capture complex image structures. To address this limitation, we propose Dynamic Adaptive Scan (DAS), a data-driven method that adaptively allocates scanning orders and regions. This enables more flexible modeling capabilities while maintaining linear computational complexity and global modeling capacity. Based on DAS, we further propose the vision backbone DAMamba, which significantly outperforms current state-of-the-art vision Mamba models in vision tasks such as image classification, object detection, instance segmentation, and semantic segmentation. Notably, it surpasses some of the latest state-of-the-art CNNs and ViTs. Code will be available at https://github.com/ltzovo/DAMamba.
Normalizing Batch Normalization for Long-Tailed Recognition
Jan 06, 2025



In real-world scenarios, the number of training samples across classes usually subjects to a long-tailed distribution. The conventionally trained network may achieve unexpected inferior performance on the rare class compared to the frequent class. Most previous works attempt to rectify the network bias from the data-level or from the classifier-level. Differently, in this paper, we identify that the bias towards the frequent class may be encoded into features, i.e., the rare-specific features which play a key role in discriminating the rare class are much weaker than the frequent-specific features. Based on such an observation, we introduce a simple yet effective approach, normalizing the parameters of Batch Normalization (BN) layer to explicitly rectify the feature bias. To achieve this end, we represent the Weight/Bias parameters of a BN layer as a vector, normalize it into a unit one and multiply the unit vector by a scalar learnable parameter. Through decoupling the direction and magnitude of parameters in BN layer to learn, the Weight/Bias exhibits a more balanced distribution and thus the strength of features becomes more even. Extensive experiments on various long-tailed recognition benchmarks (i.e., CIFAR-10/100-LT, ImageNet-LT and iNaturalist 2018) show that our method outperforms previous state-of-the-arts remarkably. The code and checkpoints are available at https://github.com/yuxiangbao/NBN.
Graph Structure Refinement with Energy-based Contrastive Learning
Dec 20, 2024



Graph Neural Networks (GNNs) have recently gained widespread attention as a successful tool for analyzing graph-structured data. However, imperfect graph structure with noisy links lacks enough robustness and may damage graph representations, therefore limiting the GNNs' performance in practical tasks. Moreover, existing generative architectures fail to fit discriminative graph-related tasks. To tackle these issues, we introduce an unsupervised method based on a joint of generative training and discriminative training to learn graph structure and representation, aiming to improve the discriminative performance of generative models. We propose an Energy-based Contrastive Learning (ECL) guided Graph Structure Refinement (GSR) framework, denoted as ECL-GSR. To our knowledge, this is the first work to combine energy-based models with contrastive learning for GSR. Specifically, we leverage ECL to approximate the joint distribution of sample pairs, which increases the similarity between representations of positive pairs while reducing the similarity between negative ones. Refined structure is produced by augmenting and removing edges according to the similarity metrics among node representations. Extensive experiments demonstrate that ECL-GSR outperforms \textit{the state-of-the-art on eight benchmark datasets} in node classification. ECL-GSR achieves \textit{faster training with fewer samples and memories} against the leading baseline, highlighting its simplicity and efficiency in downstream tasks.
CCExpert: Advancing MLLM Capability in Remote Sensing Change Captioning with Difference-Aware Integration and a Foundational Dataset
Nov 18, 2024



Remote Sensing Image Change Captioning (RSICC) aims to generate natural language descriptions of surface changes between multi-temporal remote sensing images, detailing the categories, locations, and dynamics of changed objects (e.g., additions or disappearances). Many current methods attempt to leverage the long-sequence understanding and reasoning capabilities of multimodal large language models (MLLMs) for this task. However, without comprehensive data support, these approaches often alter the essential feature transmission pathways of MLLMs, disrupting the intrinsic knowledge within the models and limiting their potential in RSICC. In this paper, we propose a novel model, CCExpert, based on a new, advanced multimodal large model framework. Firstly, we design a difference-aware integration module to capture multi-scale differences between bi-temporal images and incorporate them into the original image context, thereby enhancing the signal-to-noise ratio of differential features. Secondly, we constructed a high-quality, diversified dataset called CC-Foundation, containing 200,000 image pairs and 1.2 million captions, to provide substantial data support for continue pretraining in this domain. Lastly, we employed a three-stage progressive training process to ensure the deep integration of the difference-aware integration module with the pretrained MLLM. CCExpert achieved a notable performance of $S^*_m=81.80$ on the LEVIR-CC benchmark, significantly surpassing previous state-of-the-art methods. The code and part of the dataset will soon be open-sourced at https://github.com/Meize0729/CCExpert.