 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe 1st PortraitCraft Challenge: A CVPR 2026 Workshop Competition on Portrait Composition Understanding and Generation
Jun 09, 2026This paper presents an overview of the inaugural PortraitCraft Challenge, held as one of the official competitions at CVPR 2026. The challenge focuses on portrait composition understanding and generation, aiming to advance AI research in portrait aesthetics analysis and controllable image synthesis. Unlike existing datasets and tasks that primarily focus on global aesthetic scoring, PortraitCraft introduces a unified evaluation framework comprising two complementary tracks. Track 1 requires models to perform structured portrait composition understanding, and Track 2 requires models to generate portrait images from structured composition descriptions under explicit compositional constraints. To support the challenge, we constructed and publicly released a large-scale portrait composition dataset consisting of approximately 50,000 curated real portrait images, providing multi-level supervision. This report describes the challenge setup, evaluation protocols, dataset composition, and final results, along with an analysis of the technical characteristics of the submitted solutions. The PortraitCraft Challenge provides a standardized and reproducible platform for research on portrait composition understanding and generation, and is expected to foster further progress in the fields of portrait aesthetics and controllable image generation.
EEG-Based Multimodal Learning via Hyperbolic Mixture-of-Curvature Experts
Apr 14, 2026Electroencephalography (EEG)-based multimodal learning integrates brain signals with complementary modalities to improve mental state assessment, providing great clinical potential. The effectiveness of such paradigms largely depends on the representation learning on heterogeneous modalities. For EEG-based paradigms, one promising approach is to leverage their hierarchical structures, as recent studies have shown that both EEG and associated modalities (e.g., facial expressions) exhibit hierarchical structures reflecting complex cognitive processes. However, Euclidean embeddings struggle to represent these hierarchical structures due to their flat geometry, while hyperbolic spaces, with their exponential growth property, are naturally suited for them. In this work, we propose EEG-MoCE, a novel hyperbolic mixture-of-curvature experts framework designed for multimodal neurotechnology. EEG-MoCE assigns each modality to an expert in a learnable-curvature hyperbolic space, enabling adaptive modeling of its intrinsic geometry. A curvature-aware fusion strategy then dynamically weights experts, emphasizing modalities with richer hierarchical information. Extensive experiments on benchmark datasets demonstrate that EEG-MoCE achieves state-of-the-art performance, including emotion recognition, sleep staging, and cognitive assessment.
HEEGNet: Hyperbolic Embeddings for EEG
Jan 06, 2026Electroencephalography (EEG)-based brain-computer interfaces facilitate direct communication with a computer, enabling promising applications in human-computer interactions. However, their utility is currently limited because EEG decoding often suffers from poor generalization due to distribution shifts across domains (e.g., subjects). Learning robust representations that capture underlying task-relevant information would mitigate these shifts and improve generalization. One promising approach is to exploit the underlying hierarchical structure in EEG, as recent studies suggest that hierarchical cognitive processes, such as visual processing, can be encoded in EEG. While many decoding methods still rely on Euclidean embeddings, recent work has begun exploring hyperbolic geometry for EEG. Hyperbolic spaces, regarded as the continuous analogue of tree structures, provide a natural geometry for representing hierarchical data. In this study, we first empirically demonstrate that EEG data exhibit hyperbolicity and show that hyperbolic embeddings improve generalization. Motivated by these findings, we propose HEEGNet, a hybrid hyperbolic network architecture to capture the hierarchical structure in EEG and learn domain-invariant hyperbolic embeddings. To this end, HEEGNet combines both Euclidean and hyperbolic encoders and employs a novel coarse-to-fine domain adaptation strategy. Extensive experiments on multiple public EEG datasets, covering visual evoked potentials, emotion recognition, and intracranial EEG, demonstrate that HEEGNet achieves state-of-the-art performance.
EEG-DLite: Dataset Distillation for Efficient Large EEG Model Training
Dec 13, 2025



Large-scale EEG foundation models have shown strong generalization across a range of downstream tasks, but their training remains resource-intensive due to the volume and variable quality of EEG data. In this work, we introduce EEG-DLite, a data distillation framework that enables more efficient pre-training by selectively removing noisy and redundant samples from large EEG datasets. EEG-DLite begins by encoding EEG segments into compact latent representations using a self-supervised autoencoder, allowing sample selection to be performed efficiently and with reduced sensitivity to noise. Based on these representations, EEG-DLite filters out outliers and minimizes redundancy, resulting in a smaller yet informative subset that retains the diversity essential for effective foundation model training. Through extensive experiments, we demonstrate that training on only 5 percent of a 2,500-hour dataset curated with EEG-DLite yields performance comparable to, and in some cases better than, training on the full dataset across multiple downstream tasks. To our knowledge, this is the first systematic study of pre-training data distillation in the context of EEG foundation models. EEG-DLite provides a scalable and practical path toward more effective and efficient physiological foundation modeling. The code is available at https://github.com/t170815518/EEG-DLite.
BrainPro: Towards Large-scale Brain State-aware EEG Representation Learning
Sep 26, 2025



Electroencephalography (EEG) is a non-invasive technique for recording brain electrical activity, widely used in brain-computer interface (BCI) and healthcare. Recent EEG foundation models trained on large-scale datasets have shown improved performance and generalizability over traditional decoding methods, yet significant challenges remain. Existing models often fail to explicitly capture channel-to-channel and region-to-region interactions, which are critical sources of information inherently encoded in EEG signals. Due to varying channel configurations across datasets, they either approximate spatial structure with self-attention or restrict training to a limited set of common channels, sacrificing flexibility and effectiveness. Moreover, although EEG datasets reflect diverse brain states such as emotion, motor, and others, current models rarely learn state-aware representations during self-supervised pre-training. To address these gaps, we propose BrainPro, a large EEG model that introduces a retrieval-based spatial learning block to flexibly capture channel- and region-level interactions across varying electrode layouts, and a brain state-decoupling block that enables state-aware representation learning through parallel encoders with decoupling and region-aware reconstruction losses. This design allows BrainPro to adapt seamlessly to diverse tasks and hardware settings. Pre-trained on an extensive EEG corpus, BrainPro achieves state-of-the-art performance and robust generalization across nine public BCI datasets. Our codes and the pre-trained weights will be released.
ZONE: Zero-Shot Instruction-Guided Local Editing
Dec 28, 2023



Recent advances in vision-language models like Stable Diffusion have shown remarkable power in creative image synthesis and editing.However, most existing text-to-image editing methods encounter two obstacles: First, the text prompt needs to be carefully crafted to achieve good results, which is not intuitive or user-friendly. Second, they are insensitive to local edits and can irreversibly affect non-edited regions, leaving obvious editing traces. To tackle these problems, we propose a Zero-shot instructiON-guided local image Editing approach, termed ZONE. We first convert the editing intent from the user-provided instruction (e.g., ``make his tie blue") into specific image editing regions through InstructPix2Pix. We then propose a Region-IoU scheme for precise image layer extraction from an off-the-shelf segment model. We further develop an edge smoother based on FFT for seamless blending between the layer and the image.Our method allows for arbitrary manipulation of a specific region with a single instruction while preserving the rest. Extensive experiments demonstrate that our ZONE achieves remarkable local editing results and user-friendliness, outperforming state-of-the-art methods.
Federated Learning via Input-Output Collaborative Distillation
Dec 22, 2023



Federated learning (FL) is a machine learning paradigm in which distributed local nodes collaboratively train a central model without sharing individually held private data. Existing FL methods either iteratively share local model parameters or deploy co-distillation. However, the former is highly susceptible to private data leakage, and the latter design relies on the prerequisites of task-relevant real data. Instead, we propose a data-free FL framework based on local-to-central collaborative distillation with direct input and output space exploitation. Our design eliminates any requirement of recursive local parameter exchange or auxiliary task-relevant data to transfer knowledge, thereby giving direct privacy control to local users. In particular, to cope with the inherent data heterogeneity across locals, our technique learns to distill input on which each local model produces consensual yet unique results to represent each expertise. Our proposed FL framework achieves notable privacy-utility trade-offs with extensive experiments on image classification and segmentation tasks under various real-world heterogeneous federated learning settings on both natural and medical images.
IPDreamer: Appearance-Controllable 3D Object Generation with Image Prompts
Oct 09, 2023


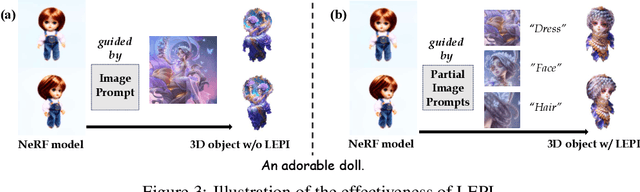
Recent advances in text-to-3D generation have been remarkable, with methods such as DreamFusion leveraging large-scale text-to-image diffusion-based models to supervise 3D generation. These methods, including the variational score distillation proposed by ProlificDreamer, enable the synthesis of detailed and photorealistic textured meshes. However, the appearance of 3D objects generated by these methods is often random and uncontrollable, posing a challenge in achieving appearance-controllable 3D objects. To address this challenge, we introduce IPDreamer, a novel approach that incorporates image prompts to provide specific and comprehensive appearance information for 3D object generation. Our results demonstrate that IPDreamer effectively generates high-quality 3D objects that are consistent with both the provided text and image prompts, demonstrating its promising capability in appearance-controllable 3D object generation.
Controllable Mind Visual Diffusion Model
May 18, 2023Brain signal visualization has emerged as an active research area, serving as a critical interface between the human visual system and computer vision models. Although diffusion models have shown promise in analyzing functional magnetic resonance imaging (fMRI) data, including reconstructing high-quality images consistent with original visual stimuli, their accuracy in extracting semantic and silhouette information from brain signals remains limited. In this regard, we propose a novel approach, referred to as Controllable Mind Visual Diffusion Model (CMVDM). CMVDM extracts semantic and silhouette information from fMRI data using attribute alignment and assistant networks. Additionally, a residual block is incorporated to capture information beyond semantic and silhouette features. We then leverage a control model to fully exploit the extracted information for image synthesis, resulting in generated images that closely resemble the visual stimuli in terms of semantics and silhouette. Through extensive experimentation, we demonstrate that CMVDM outperforms existing state-of-the-art methods both qualitatively and quantitatively.