 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSketchSong: Hierarchical Song Generation with Sketch Planning and Fine-Grained Multi-Track Modeling
Jun 02, 2026Recent song generation systems can synthesize realistic audio, yet generating complete songs remains challenging for two reasons. First, explicit song-level arrangement planning remains limited in existing methods, so models often need to organize overall arrangement development while generating low-level audio details. This often leads to incoherence in arrangements, such as weak section transitions and limited dynamic progression. Second, coarse modeling of different musical parts obscures their distinct roles and interactions, limiting arrangement richness of generated songs. In this paper, we present SketchSong, a hierarchical song generation framework that addresses these issues through song-level sketch planning and fine-grained multi-track modeling. Along the temporal dimension, SketchSong first predicts a compact sequence of high-level sketch tokens derived from compressed audio representations, and then generates audio tokens conditioned on these sketches. This coarse-to-fine process gives the model an explicit arrangement plan before detailed audio generation. Along the track dimension, SketchSong explicitly models four tracks, i.e., vocals, bass, drums and other instruments. This enables the model to capture the roles and interactions of different musical parts more precisely. Experiments on song generation benchmarks show that SketchSong consistently outperforms our baseline on both objective metrics and human listening tests. Despite not employing additional post-training for preference optimization such as lyrics and text-prompt alignments, SketchSong achieves competitive results against strong, post-trained open-source systems, demonstrating the effectiveness of our overall design.
Dual Diffusion Models for Multi-modal Guided 3D Avatar Generation
Mar 04, 2026Generating high-fidelity 3D avatars from text or image prompts is highly sought after in virtual reality and human-computer interaction. However, existing text-driven methods often rely on iterative Score Distillation Sampling (SDS) or CLIP optimization, which struggle with fine-grained semantic control and suffer from excessively slow inference. Meanwhile, image-driven approaches are severely bottlenecked by the scarcity and high acquisition cost of high-quality 3D facial scans, limiting model generalization. To address these challenges, we first construct a novel, large-scale dataset comprising over 100,000 pairs across four modalities: fine-grained textual descriptions, in-the-wild face images, high-quality light-normalized texture UV maps, and 3D geometric shapes. Leveraging this comprehensive dataset, we propose PromptAvatar, a framework featuring dual diffusion models. Specifically, it integrates a Texture Diffusion Model (TDM) that supports flexible multi-condition guidance from text and/or image prompts, alongside a Geometry Diffusion Model (GDM) guided by text prompts. By learning the direct mapping from multi-modal prompts to 3D representations, PromptAvatar eliminates the need for time-consuming iterative optimization, successfully generating high-fidelity, shading-free 3D avatars in under 10 seconds. Extensive quantitative and qualitative experiments demonstrate that our method significantly outperforms existing state-of-the-art approaches in generation quality, fine-grained detail alignment, and computational efficiency.
Tutti: Expressive Multi-Singer Synthesis via Structure-Level Timbre Control and Vocal Texture Modeling
Feb 09, 2026While existing Singing Voice Synthesis systems achieve high-fidelity solo performances, they are constrained by global timbre control, failing to address dynamic multi-singer arrangement and vocal texture within a single song. To address this, we propose Tutti, a unified framework designed for structured multi-singer generation. Specifically, we introduce a Structure-Aware Singer Prompt to enable flexible singer scheduling evolving with musical structure, and propose Complementary Texture Learning via Condition-Guided VAE to capture implicit acoustic textures (e.g., spatial reverberation and spectral fusion) that are complementary to explicit controls. Experiments demonstrate that Tutti excels in precise multi-singer scheduling and significantly enhances the acoustic realism of choral generation, offering a novel paradigm for complex multi-singer arrangement. Audio samples are available at https://annoauth123-ctrl.github.io/Tutii_Demo/.
ZONE: Zero-Shot Instruction-Guided Local Editing
Dec 28, 2023



Recent advances in vision-language models like Stable Diffusion have shown remarkable power in creative image synthesis and editing.However, most existing text-to-image editing methods encounter two obstacles: First, the text prompt needs to be carefully crafted to achieve good results, which is not intuitive or user-friendly. Second, they are insensitive to local edits and can irreversibly affect non-edited regions, leaving obvious editing traces. To tackle these problems, we propose a Zero-shot instructiON-guided local image Editing approach, termed ZONE. We first convert the editing intent from the user-provided instruction (e.g., ``make his tie blue") into specific image editing regions through InstructPix2Pix. We then propose a Region-IoU scheme for precise image layer extraction from an off-the-shelf segment model. We further develop an edge smoother based on FFT for seamless blending between the layer and the image.Our method allows for arbitrary manipulation of a specific region with a single instruction while preserving the rest. Extensive experiments demonstrate that our ZONE achieves remarkable local editing results and user-friendliness, outperforming state-of-the-art methods.
IPDreamer: Appearance-Controllable 3D Object Generation with Image Prompts
Oct 09, 2023


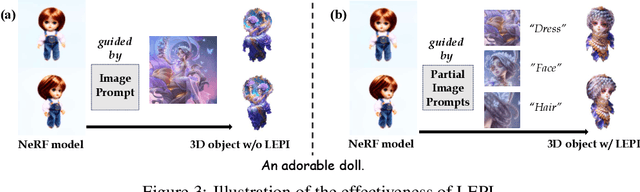
Recent advances in text-to-3D generation have been remarkable, with methods such as DreamFusion leveraging large-scale text-to-image diffusion-based models to supervise 3D generation. These methods, including the variational score distillation proposed by ProlificDreamer, enable the synthesis of detailed and photorealistic textured meshes. However, the appearance of 3D objects generated by these methods is often random and uncontrollable, posing a challenge in achieving appearance-controllable 3D objects. To address this challenge, we introduce IPDreamer, a novel approach that incorporates image prompts to provide specific and comprehensive appearance information for 3D object generation. Our results demonstrate that IPDreamer effectively generates high-quality 3D objects that are consistent with both the provided text and image prompts, demonstrating its promising capability in appearance-controllable 3D object generation.