 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNegligible in Size, Significant in Effect: On Scale Vectors in Large Language Models
May 26, 2026Normalization layers in modern large language models (LLMs) consist of a deterministic normalization operation and a learnable scale vector. While the normalization operation has been extensively studied, the scale vector remains poorly understood despite its ubiquitous use. In this work, we present a systematic study of scale vectors in LLMs from the perspectives of expressivity, optimization, and architectural structure. First, we show empirically that although scale vectors constitute only a negligible fraction of model parameters, removing them substantially degrades LLM pre-training. Our theory further shows that, in Pre-Norm architectures, scale vectors do not increase expressivity; instead, they improve optimization through a self-amplifying preconditioning effect on subsequent linear mappings. Second, we investigate the role of weight decay for scale vectors. By distinguishing Input-Norm and Output-Norm layers, we theoretically show that weight decay is beneficial for the former but harmful for the latter, due to their distinct roles in optimization and expressivity. Third, motivated by this understanding, we propose three lightweight and complementary improvements to scale vectors: branch-specific heterogeneity, improved placement around linear mappings, and magnitude-direction reparameterization. Both theory and experiments show that each improvement yields consistent gains. Finally, we combine these improvements into a unified scale-vector strategy and evaluate it through extensive LLM pre-training experiments on dense and mixture-of-experts models ranging from 0.12B to 2B parameters, across multiple optimizers and learning rate schedules, under industrial-scale token budgets. The unified strategy consistently achieves lower terminal loss than well-tuned baselines and exhibits more favorable scaling behavior, while adding negligible parameter and computational overhead.
More Expressive Feedforward Layers: Part I. Token-Adaptive Mixing of Activations
May 26, 2026Feedforward network (FFN) layers account for a large fraction of parameters and nonlinear expressivity in Transformer-based large language models (LLMs). Despite the evolution from ReLU and GELU to gated variants such as SwiGLU, most FFN designs still use a single fixed activation function, applying the same nonlinear transformation to all tokens. In this work, we propose Mixture of Activations (MoA), a token-adaptive FFN design that mixes a dictionary of activation functions using lightweight input-dependent gates while sharing the same linear projections. As an input-independent counterpart, we also introduce learnable activations (LA), which form linear combinations of activation functions for both ReLU-type and SwiGLU-type FFNs. Theoretically, we establish strict finite-width expressive separations among fixed-activation FFNs, LA, and MoA: LA strictly contains fixed-activation FFNs, while MoA strictly contains LA, with the additional expressivity arising from input-dependent nonlinear hybridization. Empirically, we evaluate MoA through extensive pre-training experiments on dense and MoE language models ranging from 0.12B to 2B parameters under different token budgets, optimizers, and learning rate schedules. MoA consistently achieves lower terminal loss and exhibits more favorable scaling behavior than well-tuned baselines, with minimal parameter and computational overhead. These results suggest that token-adaptive activation mixing is a simple and effective mechanism for improving FFN expressivity in LLMs.
On the Learning Dynamics of Two-layer Linear Networks with Label Noise SGD
Mar 11, 2026One crucial factor behind the success of deep learning lies in the implicit bias induced by noise inherent in gradient-based training algorithms. Motivated by empirical observations that training with noisy labels improves model generalization, we delve into the underlying mechanisms behind stochastic gradient descent (SGD) with label noise. Focusing on a two-layer over-parameterized linear network, we analyze the learning dynamics of label noise SGD, unveiling a two-phase learning behavior. In \emph{Phase I}, the magnitudes of model weights progressively diminish, and the model escapes the lazy regime; enters the rich regime. In \emph{Phase II}, the alignment between model weights and the ground-truth interpolator increases, and the model eventually converges. Our analysis highlights the critical role of label noise in driving the transition from the lazy to the rich regime and minimally explains its empirical success. Furthermore, we extend these insights to Sharpness-Aware Minimization (SAM), showing that the principles governing label noise SGD also apply to broader optimization algorithms. Extensive experiments, conducted under both synthetic and real-world setups, strongly support our theory. Our code is released at https://github.com/a-usually/Label-Noise-SGD.
Accelerating LLM Pre-Training through Flat-Direction Dynamics Enhancement
Feb 26, 2026Pre-training Large Language Models requires immense computational resources, making optimizer efficiency essential. The optimization landscape is highly anisotropic, with loss reduction driven predominantly by progress along flat directions. While matrix-based optimizers such as Muon and SOAP leverage fine-grained curvature information to outperform AdamW, their updates tend toward isotropy -- relatively conservative along flat directions yet potentially aggressive along sharp ones. To address this limitation, we first establish a unified Riemannian Ordinary Differential Equation (ODE) framework that elucidates how common adaptive algorithms operate synergistically: the preconditioner induces a Riemannian geometry that mitigates ill-conditioning, while momentum serves as a Riemannian damping term that promotes convergence. Guided by these insights, we propose LITE, a generalized acceleration strategy that enhances training dynamics by applying larger Hessian damping coefficients and learning rates along flat trajectories. Extensive experiments demonstrate that LITE significantly accelerates both Muon and SOAP across diverse architectures (Dense, MoE), parameter scales (130M--1.3B), datasets (C4, Pile), and learning-rate schedules (cosine, warmup-stable-decay). Theoretical analysis confirms that LITE facilitates faster convergence along flat directions in anisotropic landscapes, providing a principled approach to efficient LLM pre-training. The code is available at https://github.com/SHUCHENZHU/LITE.
Fast Catch-Up, Late Switching: Optimal Batch Size Scheduling via Functional Scaling Laws
Feb 15, 2026Batch size scheduling (BSS) plays a critical role in large-scale deep learning training, influencing both optimization dynamics and computational efficiency. Yet, its theoretical foundations remain poorly understood. In this work, we show that the functional scaling law (FSL) framework introduced in Li et al. (2025a) provides a principled lens for analyzing BSS. Specifically, we characterize the optimal BSS under a fixed data budget and show that its structure depends sharply on task difficulty. For easy tasks, optimal schedules keep increasing batch size throughout. In contrast, for hard tasks, the optimal schedule maintains small batch sizes for most of training and switches to large batches only in a late stage. To explain the emergence of late switching, we uncover a dynamical mechanism -- the fast catch-up effect -- which also manifests in large language model (LLM) pretraining. After switching from small to large batches, the loss rapidly aligns with the constant large-batch trajectory. Using FSL, we show that this effect stems from rapid forgetting of accumulated gradient noise, with the catch-up speed determined by task difficulty. Crucially, this effect implies that large batches can be safely deferred to late training without sacrificing performance, while substantially reducing data consumption. Finally, extensive LLM pretraining experiments -- covering both Dense and MoE architectures with up to 1.1B parameters and 1T tokens -- validate our theoretical predictions. Across all settings, late-switch schedules consistently outperform constant-batch and early-switch baselines.
A Single Merging Suffices: Recovering Server-based Learning Performance in Decentralized Learning
Jul 09, 2025Decentralized learning provides a scalable alternative to traditional parameter-server-based training, yet its performance is often hindered by limited peer-to-peer communication. In this paper, we study how communication should be scheduled over time, including determining when and how frequently devices synchronize. Our empirical results show that concentrating communication budgets in the later stages of decentralized training markedly improves global generalization. Surprisingly, we uncover that fully connected communication at the final step, implemented by a single global merging, is sufficient to match the performance of server-based training. We further show that low communication in decentralized learning preserves the \textit{mergeability} of local models throughout training. Our theoretical contributions, which explains these phenomena, are first to establish that the globally merged model of decentralized SGD can converge faster than centralized mini-batch SGD. Technically, we novelly reinterpret part of the discrepancy among local models, which were previously considered as detrimental noise, as constructive components that accelerate convergence. This work challenges the common belief that decentralized learning generalizes poorly under data heterogeneity and limited communication, while offering new insights into model merging and neural network loss landscapes.
GradPower: Powering Gradients for Faster Language Model Pre-Training
May 30, 2025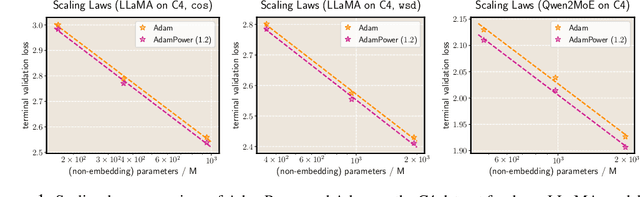
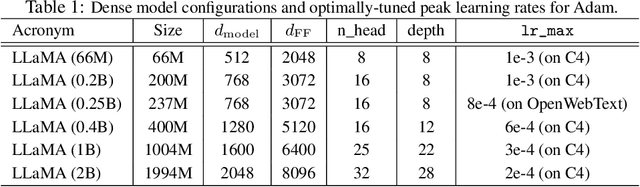
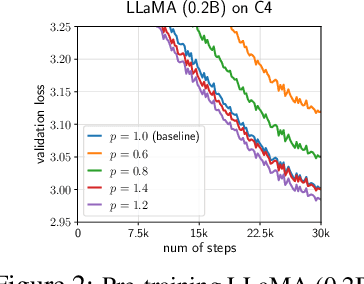
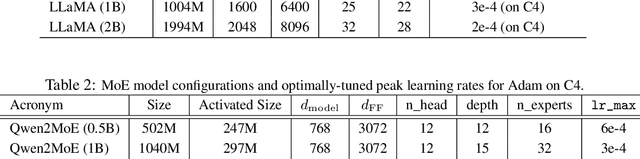
We propose GradPower, a lightweight gradient-transformation technique for accelerating language model pre-training. Given a gradient vector $g=(g_i)_i$, GradPower first applies the elementwise sign-power transformation: $\varphi_p(g)=({\rm sign}(g_i)|g_i|^p)_{i}$ for a fixed $p>0$, and then feeds the transformed gradient into a base optimizer. Notably, GradPower requires only a single-line code change and no modifications to the base optimizer's internal logic, including the hyperparameters. When applied to Adam (termed AdamPower), GradPower consistently achieves lower terminal loss across diverse architectures (LLaMA, Qwen2MoE), parameter scales (66M to 2B), datasets (C4, OpenWebText), and learning-rate schedules (cosine, warmup-stable-decay). The most pronounced gains are observed when training modern mixture-of-experts models with warmup-stable-decay schedules. GradPower also integrates seamlessly with other state-of-the-art optimizers, such as Muon, yielding further improvements. Finally, we provide theoretical analyses that reveal the underlying mechanism of GradPower and highlights the influence of gradient noise.
On the Expressive Power of Mixture-of-Experts for Structured Complex Tasks
May 30, 2025Mixture-of-experts networks (MoEs) have demonstrated remarkable efficiency in modern deep learning. Despite their empirical success, the theoretical foundations underlying their ability to model complex tasks remain poorly understood. In this work, we conduct a systematic study of the expressive power of MoEs in modeling complex tasks with two common structural priors: low-dimensionality and sparsity. For shallow MoEs, we prove that they can efficiently approximate functions supported on low-dimensional manifolds, overcoming the curse of dimensionality. For deep MoEs, we show that $\cO(L)$-layer MoEs with $E$ experts per layer can approximate piecewise functions comprising $E^L$ pieces with compositional sparsity, i.e., they can exhibit an exponential number of structured tasks. Our analysis reveals the roles of critical architectural components and hyperparameters in MoEs, including the gating mechanism, expert networks, the number of experts, and the number of layers, and offers natural suggestions for MoE variants.
The Sharpness Disparity Principle in Transformers for Accelerating Language Model Pre-Training
Feb 26, 2025Transformers consist of diverse building blocks, such as embedding layers, normalization layers, self-attention mechanisms, and point-wise feedforward networks. Thus, understanding the differences and interactions among these blocks is important. In this paper, we uncover a clear Sharpness Disparity across these blocks, which emerges early in training and intriguingly persists throughout the training process. Motivated by this finding, we propose Blockwise Learning Rate (LR), a strategy that tailors the LR to each block's sharpness, accelerating large language model (LLM) pre-training. By integrating Blockwise LR into AdamW, we consistently achieve lower terminal loss and nearly $2\times$ speedup compared to vanilla AdamW. We demonstrate this acceleration across GPT-2 and LLaMA, with model sizes ranging from 0.12B to 1.1B and datasets of OpenWebText and MiniPile. Finally, we incorporate Blockwise LR into Adam-mini (Zhang et al., 2024), a recently proposed memory-efficient variant of Adam, achieving a combined $2\times$ speedup and $2\times$ memory saving. These results underscore the potential of exploiting the sharpness disparity to improve LLM training.
CCExpert: Advancing MLLM Capability in Remote Sensing Change Captioning with Difference-Aware Integration and a Foundational Dataset
Nov 18, 2024



Remote Sensing Image Change Captioning (RSICC) aims to generate natural language descriptions of surface changes between multi-temporal remote sensing images, detailing the categories, locations, and dynamics of changed objects (e.g., additions or disappearances). Many current methods attempt to leverage the long-sequence understanding and reasoning capabilities of multimodal large language models (MLLMs) for this task. However, without comprehensive data support, these approaches often alter the essential feature transmission pathways of MLLMs, disrupting the intrinsic knowledge within the models and limiting their potential in RSICC. In this paper, we propose a novel model, CCExpert, based on a new, advanced multimodal large model framework. Firstly, we design a difference-aware integration module to capture multi-scale differences between bi-temporal images and incorporate them into the original image context, thereby enhancing the signal-to-noise ratio of differential features. Secondly, we constructed a high-quality, diversified dataset called CC-Foundation, containing 200,000 image pairs and 1.2 million captions, to provide substantial data support for continue pretraining in this domain. Lastly, we employed a three-stage progressive training process to ensure the deep integration of the difference-aware integration module with the pretrained MLLM. CCExpert achieved a notable performance of $S^*_m=81.80$ on the LEVIR-CC benchmark, significantly surpassing previous state-of-the-art methods. The code and part of the dataset will soon be open-sourced at https://github.com/Meize0729/CCExpert.