 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVADER: A Human-Evaluated Benchmark for Vulnerability Assessment, Detection, Explanation, and Remediation
May 26, 2025Ensuring that large language models (LLMs) can effectively assess, detect, explain, and remediate software vulnerabilities is critical for building robust and secure software systems. We introduce VADER, a human-evaluated benchmark designed explicitly to assess LLM performance across four key vulnerability-handling dimensions: assessment, detection, explanation, and remediation. VADER comprises 174 real-world software vulnerabilities, each carefully curated from GitHub repositories and annotated by security experts. For each vulnerability case, models are tasked with identifying the flaw, classifying it using Common Weakness Enumeration (CWE), explaining its underlying cause, proposing a patch, and formulating a test plan. Using a one-shot prompting strategy, we benchmark six state-of-the-art LLMs (Claude 3.7 Sonnet, Gemini 2.5 Pro, GPT-4.1, GPT-4.5, Grok 3 Beta, and o3) on VADER, and human security experts evaluated each response according to a rigorous scoring rubric emphasizing remediation (quality of the code fix, 50%), explanation (20%), and classification and test plan (30%) according to a standardized rubric. Our results show that current state-of-the-art LLMs achieve only moderate success on VADER - OpenAI's o3 attained 54.7% accuracy overall, with others in the 49-54% range, indicating ample room for improvement. Notably, remediation quality is strongly correlated (Pearson r > 0.97) with accurate classification and test plans, suggesting that models that effectively categorize vulnerabilities also tend to fix them well. VADER's comprehensive dataset, detailed evaluation rubrics, scoring tools, and visualized results with confidence intervals are publicly released, providing the community with an interpretable, reproducible benchmark to advance vulnerability-aware LLMs. All code and data are available at: https://github.com/AfterQuery/vader
InverseBench: Benchmarking Plug-and-Play Diffusion Priors for Inverse Problems in Physical Sciences
Mar 14, 2025



Plug-and-play diffusion priors (PnPDP) have emerged as a promising research direction for solving inverse problems. However, current studies primarily focus on natural image restoration, leaving the performance of these algorithms in scientific inverse problems largely unexplored. To address this gap, we introduce \textsc{InverseBench}, a framework that evaluates diffusion models across five distinct scientific inverse problems. These problems present unique structural challenges that differ from existing benchmarks, arising from critical scientific applications such as optical tomography, medical imaging, black hole imaging, seismology, and fluid dynamics. With \textsc{InverseBench}, we benchmark 14 inverse problem algorithms that use plug-and-play diffusion priors against strong, domain-specific baselines, offering valuable new insights into the strengths and weaknesses of existing algorithms. To facilitate further research and development, we open-source the codebase, along with datasets and pre-trained models, at https://devzhk.github.io/InverseBench/.
DART-Eval: A Comprehensive DNA Language Model Evaluation Benchmark on Regulatory DNA
Dec 06, 2024



Recent advances in self-supervised models for natural language, vision, and protein sequences have inspired the development of large genomic DNA language models (DNALMs). These models aim to learn generalizable representations of diverse DNA elements, potentially enabling various genomic prediction, interpretation and design tasks. Despite their potential, existing benchmarks do not adequately assess the capabilities of DNALMs on key downstream applications involving an important class of non-coding DNA elements critical for regulating gene activity. In this study, we introduce DART-Eval, a suite of representative benchmarks specifically focused on regulatory DNA to evaluate model performance across zero-shot, probed, and fine-tuned scenarios against contemporary ab initio models as baselines. Our benchmarks target biologically meaningful downstream tasks such as functional sequence feature discovery, predicting cell-type specific regulatory activity, and counterfactual prediction of the impacts of genetic variants. We find that current DNALMs exhibit inconsistent performance and do not offer compelling gains over alternative baseline models for most tasks, while requiring significantly more computational resources. We discuss potentially promising modeling, data curation, and evaluation strategies for the next generation of DNALMs. Our code is available at https://github.com/kundajelab/DART-Eval.
Ensemble Kalman Diffusion Guidance: A Derivative-free Method for Inverse Problems
Sep 30, 2024



When solving inverse problems, it is increasingly popular to use pre-trained diffusion models as plug-and-play priors. This framework can accommodate different forward models without re-training while preserving the generative capability of diffusion models. Despite their success in many imaging inverse problems, most existing methods rely on privileged information such as derivative, pseudo-inverse, or full knowledge about the forward model. This reliance poses a substantial limitation that restricts their use in a wide range of problems where such information is unavailable, such as in many scientific applications. To address this issue, we propose Ensemble Kalman Diffusion Guidance (EnKG) for diffusion models, a derivative-free approach that can solve inverse problems by only accessing forward model evaluations and a pre-trained diffusion model prior. We study the empirical effectiveness of our method across various inverse problems, including scientific settings such as inferring fluid flows and astronomical objects, which are highly non-linear inverse problems that often only permit black-box access to the forward model.
Towards Open-World Mobile Manipulation in Homes: Lessons from the Neurips 2023 HomeRobot Open Vocabulary Mobile Manipulation Challenge
Jul 09, 2024



In order to develop robots that can effectively serve as versatile and capable home assistants, it is crucial for them to reliably perceive and interact with a wide variety of objects across diverse environments. To this end, we proposed Open Vocabulary Mobile Manipulation as a key benchmark task for robotics: finding any object in a novel environment and placing it on any receptacle surface within that environment. We organized a NeurIPS 2023 competition featuring both simulation and real-world components to evaluate solutions to this task. Our baselines on the most challenging version of this task, using real perception in simulation, achieved only an 0.8% success rate; by the end of the competition, the best participants achieved an 10.8\% success rate, a 13x improvement. We observed that the most successful teams employed a variety of methods, yet two common threads emerged among the best solutions: enhancing error detection and recovery, and improving the integration of perception with decision-making processes. In this paper, we detail the results and methodologies used, both in simulation and real-world settings. We discuss the lessons learned and their implications for future research. Additionally, we compare performance in real and simulated environments, emphasizing the necessity for robust generalization to novel settings.
Cambrian-1: A Fully Open, Vision-Centric Exploration of Multimodal LLMs
Jun 24, 2024



We introduce Cambrian-1, a family of multimodal LLMs (MLLMs) designed with a vision-centric approach. While stronger language models can enhance multimodal capabilities, the design choices for vision components are often insufficiently explored and disconnected from visual representation learning research. This gap hinders accurate sensory grounding in real-world scenarios. Our study uses LLMs and visual instruction tuning as an interface to evaluate various visual representations, offering new insights into different models and architectures -- self-supervised, strongly supervised, or combinations thereof -- based on experiments with over 20 vision encoders. We critically examine existing MLLM benchmarks, addressing the difficulties involved in consolidating and interpreting results from various tasks, and introduce a new vision-centric benchmark, CV-Bench. To further improve visual grounding, we propose the Spatial Vision Aggregator (SVA), a dynamic and spatially-aware connector that integrates high-resolution vision features with LLMs while reducing the number of tokens. Additionally, we discuss the curation of high-quality visual instruction-tuning data from publicly available sources, emphasizing the importance of data source balancing and distribution ratio. Collectively, Cambrian-1 not only achieves state-of-the-art performance but also serves as a comprehensive, open cookbook for instruction-tuned MLLMs. We provide model weights, code, supporting tools, datasets, and detailed instruction-tuning and evaluation recipes. We hope our release will inspire and accelerate advancements in multimodal systems and visual representation learning.
HomeRobot: Open-Vocabulary Mobile Manipulation
Jun 20, 2023



HomeRobot (noun): An affordable compliant robot that navigates homes and manipulates a wide range of objects in order to complete everyday tasks. Open-Vocabulary Mobile Manipulation (OVMM) is the problem of picking any object in any unseen environment, and placing it in a commanded location. This is a foundational challenge for robots to be useful assistants in human environments, because it involves tackling sub-problems from across robotics: perception, language understanding, navigation, and manipulation are all essential to OVMM. In addition, integration of the solutions to these sub-problems poses its own substantial challenges. To drive research in this area, we introduce the HomeRobot OVMM benchmark, where an agent navigates household environments to grasp novel objects and place them on target receptacles. HomeRobot has two components: a simulation component, which uses a large and diverse curated object set in new, high-quality multi-room home environments; and a real-world component, providing a software stack for the low-cost Hello Robot Stretch to encourage replication of real-world experiments across labs. We implement both reinforcement learning and heuristic (model-based) baselines and show evidence of sim-to-real transfer. Our baselines achieve a 20% success rate in the real world; our experiments identify ways future research work improve performance. See videos on our website: https://ovmm.github.io/.
USA-Net: Unified Semantic and Affordance Representations for Robot Memory
Apr 25, 2023



In order for robots to follow open-ended instructions like "go open the brown cabinet over the sink", they require an understanding of both the scene geometry and the semantics of their environment. Robotic systems often handle these through separate pipelines, sometimes using very different representation spaces, which can be suboptimal when the two objectives conflict. In this work, we present USA-Net, a simple method for constructing a world representation that encodes both the semantics and spatial affordances of a scene in a differentiable map. This allows us to build a gradient-based planner which can navigate to locations in the scene specified using open-ended vocabulary. We use this planner to consistently generate trajectories which are both shorter 5-10% shorter and 10-30% closer to our goal query in CLIP embedding space than paths from comparable grid-based planners which don't leverage gradient information. To our knowledge, this is the first end-to-end differentiable planner optimizes for both semantics and affordance in a single implicit map. Code and visuals are available at our website: https://usa.bolte.cc/
Navigating to Objects Specified by Images
Apr 03, 2023



Images are a convenient way to specify which particular object instance an embodied agent should navigate to. Solving this task requires semantic visual reasoning and exploration of unknown environments. We present a system that can perform this task in both simulation and the real world. Our modular method solves sub-tasks of exploration, goal instance re-identification, goal localization, and local navigation. We re-identify the goal instance in egocentric vision using feature-matching and localize the goal instance by projecting matched features to a map. Each sub-task is solved using off-the-shelf components requiring zero fine-tuning. On the HM3D InstanceImageNav benchmark, this system outperforms a baseline end-to-end RL policy 7x and a state-of-the-art ImageNav model 2.3x (56% vs 25% success). We deploy this system to a mobile robot platform and demonstrate effective real-world performance, achieving an 88% success rate across a home and an office environment.
Theseus: A Library for Differentiable Nonlinear Optimization
Jul 19, 2022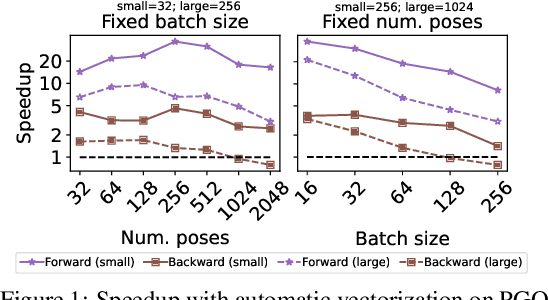
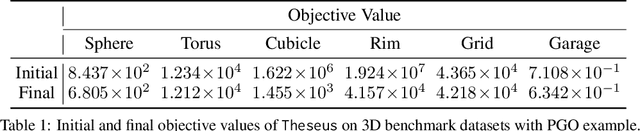
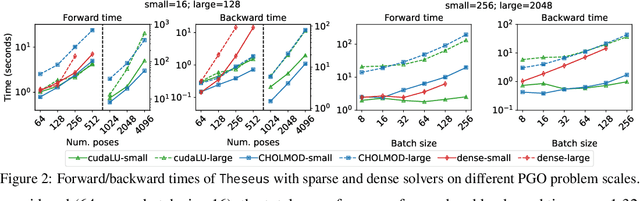
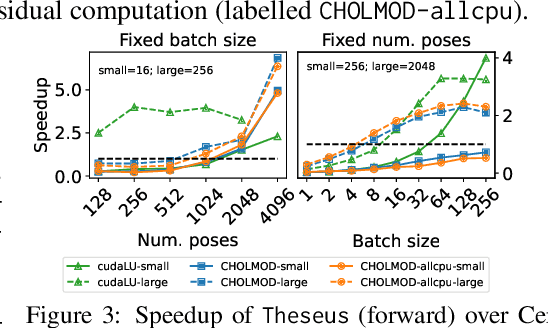
We present Theseus, an efficient application-agnostic open source library for differentiable nonlinear least squares (DNLS) optimization built on PyTorch, providing a common framework for end-to-end structured learning in robotics and vision. Existing DNLS implementations are application specific and do not always incorporate many ingredients important for efficiency. Theseus is application-agnostic, as we illustrate with several example applications that are built using the same underlying differentiable components, such as second-order optimizers, standard costs functions, and Lie groups. For efficiency, Theseus incorporates support for sparse solvers, automatic vectorization, batching, GPU acceleration, and gradient computation with implicit differentiation and direct loss minimization. We do extensive performance evaluation in a set of applications, demonstrating significant efficiency gains and better scalability when these features are incorporated. Project page: https://sites.google.com/view/theseus-ai