 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhat Drives Success in Physical Planning with Joint-Embedding Predictive World Models?
Dec 30, 2025A long-standing challenge in AI is to develop agents capable of solving a wide range of physical tasks and generalizing to new, unseen tasks and environments. A popular recent approach involves training a world model from state-action trajectories and subsequently use it with a planning algorithm to solve new tasks. Planning is commonly performed in the input space, but a recent family of methods has introduced planning algorithms that optimize in the learned representation space of the world model, with the promise that abstracting irrelevant details yields more efficient planning. In this work, we characterize models from this family as JEPA-WMs and investigate the technical choices that make algorithms from this class work. We propose a comprehensive study of several key components with the objective of finding the optimal approach within the family. We conducted experiments using both simulated environments and real-world robotic data, and studied how the model architecture, the training objective, and the planning algorithm affect planning success. We combine our findings to propose a model that outperforms two established baselines, DINO-WM and V-JEPA-2-AC, in both navigation and manipulation tasks. Code, data and checkpoints are available at https://github.com/facebookresearch/jepa-wms.
World Models Can Leverage Human Videos for Dexterous Manipulation
Dec 15, 2025



Dexterous manipulation is challenging because it requires understanding how subtle hand motion influences the environment through contact with objects. We introduce DexWM, a Dexterous Manipulation World Model that predicts the next latent state of the environment conditioned on past states and dexterous actions. To overcome the scarcity of dexterous manipulation datasets, DexWM is trained on over 900 hours of human and non-dexterous robot videos. To enable fine-grained dexterity, we find that predicting visual features alone is insufficient; therefore, we introduce an auxiliary hand consistency loss that enforces accurate hand configurations. DexWM outperforms prior world models conditioned on text, navigation, and full-body actions, achieving more accurate predictions of future states. DexWM also demonstrates strong zero-shot generalization to unseen manipulation skills when deployed on a Franka Panda arm equipped with an Allegro gripper, outperforming Diffusion Policy by over 50% on average in grasping, placing, and reaching tasks.
PARTNR: A Benchmark for Planning and Reasoning in Embodied Multi-agent Tasks
Oct 31, 2024



We present a benchmark for Planning And Reasoning Tasks in humaN-Robot collaboration (PARTNR) designed to study human-robot coordination in household activities. PARTNR tasks exhibit characteristics of everyday tasks, such as spatial, temporal, and heterogeneous agent capability constraints. We employ a semi-automated task generation pipeline using Large Language Models (LLMs), incorporating simulation in the loop for grounding and verification. PARTNR stands as the largest benchmark of its kind, comprising 100,000 natural language tasks, spanning 60 houses and 5,819 unique objects. We analyze state-of-the-art LLMs on PARTNR tasks, across the axes of planning, perception and skill execution. The analysis reveals significant limitations in SoTA models, such as poor coordination and failures in task tracking and recovery from errors. When LLMs are paired with real humans, they require 1.5x as many steps as two humans collaborating and 1.1x more steps than a single human, underscoring the potential for improvement in these models. We further show that fine-tuning smaller LLMs with planning data can achieve performance on par with models 9 times larger, while being 8.6x faster at inference. Overall, PARTNR highlights significant challenges facing collaborative embodied agents and aims to drive research in this direction.
Situated Instruction Following
Jul 15, 2024



Language is never spoken in a vacuum. It is expressed, comprehended, and contextualized within the holistic backdrop of the speaker's history, actions, and environment. Since humans are used to communicating efficiently with situated language, the practicality of robotic assistants hinge on their ability to understand and act upon implicit and situated instructions. In traditional instruction following paradigms, the agent acts alone in an empty house, leading to language use that is both simplified and artificially "complete." In contrast, we propose situated instruction following, which embraces the inherent underspecification and ambiguity of real-world communication with the physical presence of a human speaker. The meaning of situated instructions naturally unfold through the past actions and the expected future behaviors of the human involved. Specifically, within our settings we have instructions that (1) are ambiguously specified, (2) have temporally evolving intent, (3) can be interpreted more precisely with the agent's dynamic actions. Our experiments indicate that state-of-the-art Embodied Instruction Following (EIF) models lack holistic understanding of situated human intention.
Towards Open-World Mobile Manipulation in Homes: Lessons from the Neurips 2023 HomeRobot Open Vocabulary Mobile Manipulation Challenge
Jul 09, 2024



In order to develop robots that can effectively serve as versatile and capable home assistants, it is crucial for them to reliably perceive and interact with a wide variety of objects across diverse environments. To this end, we proposed Open Vocabulary Mobile Manipulation as a key benchmark task for robotics: finding any object in a novel environment and placing it on any receptacle surface within that environment. We organized a NeurIPS 2023 competition featuring both simulation and real-world components to evaluate solutions to this task. Our baselines on the most challenging version of this task, using real perception in simulation, achieved only an 0.8% success rate; by the end of the competition, the best participants achieved an 10.8\% success rate, a 13x improvement. We observed that the most successful teams employed a variety of methods, yet two common threads emerged among the best solutions: enhancing error detection and recovery, and improving the integration of perception with decision-making processes. In this paper, we detail the results and methodologies used, both in simulation and real-world settings. We discuss the lessons learned and their implications for future research. Additionally, we compare performance in real and simulated environments, emphasizing the necessity for robust generalization to novel settings.
Habitat 3.0: A Co-Habitat for Humans, Avatars and Robots
Oct 19, 2023



We present Habitat 3.0: a simulation platform for studying collaborative human-robot tasks in home environments. Habitat 3.0 offers contributions across three dimensions: (1) Accurate humanoid simulation: addressing challenges in modeling complex deformable bodies and diversity in appearance and motion, all while ensuring high simulation speed. (2) Human-in-the-loop infrastructure: enabling real human interaction with simulated robots via mouse/keyboard or a VR interface, facilitating evaluation of robot policies with human input. (3) Collaborative tasks: studying two collaborative tasks, Social Navigation and Social Rearrangement. Social Navigation investigates a robot's ability to locate and follow humanoid avatars in unseen environments, whereas Social Rearrangement addresses collaboration between a humanoid and robot while rearranging a scene. These contributions allow us to study end-to-end learned and heuristic baselines for human-robot collaboration in-depth, as well as evaluate them with humans in the loop. Our experiments demonstrate that learned robot policies lead to efficient task completion when collaborating with unseen humanoid agents and human partners that might exhibit behaviors that the robot has not seen before. Additionally, we observe emergent behaviors during collaborative task execution, such as the robot yielding space when obstructing a humanoid agent, thereby allowing the effective completion of the task by the humanoid agent. Furthermore, our experiments using the human-in-the-loop tool demonstrate that our automated evaluation with humanoids can provide an indication of the relative ordering of different policies when evaluated with real human collaborators. Habitat 3.0 unlocks interesting new features in simulators for Embodied AI, and we hope it paves the way for a new frontier of embodied human-AI interaction capabilities.
HomeRobot: Open-Vocabulary Mobile Manipulation
Jun 20, 2023



HomeRobot (noun): An affordable compliant robot that navigates homes and manipulates a wide range of objects in order to complete everyday tasks. Open-Vocabulary Mobile Manipulation (OVMM) is the problem of picking any object in any unseen environment, and placing it in a commanded location. This is a foundational challenge for robots to be useful assistants in human environments, because it involves tackling sub-problems from across robotics: perception, language understanding, navigation, and manipulation are all essential to OVMM. In addition, integration of the solutions to these sub-problems poses its own substantial challenges. To drive research in this area, we introduce the HomeRobot OVMM benchmark, where an agent navigates household environments to grasp novel objects and place them on target receptacles. HomeRobot has two components: a simulation component, which uses a large and diverse curated object set in new, high-quality multi-room home environments; and a real-world component, providing a software stack for the low-cost Hello Robot Stretch to encourage replication of real-world experiments across labs. We implement both reinforcement learning and heuristic (model-based) baselines and show evidence of sim-to-real transfer. Our baselines achieve a 20% success rate in the real world; our experiments identify ways future research work improve performance. See videos on our website: https://ovmm.github.io/.
Leveraging Language for Accelerated Learning of Tool Manipulation
Jun 27, 2022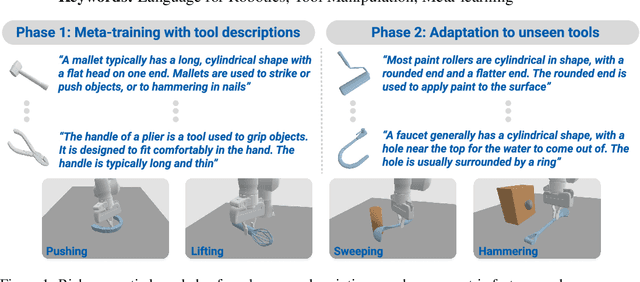
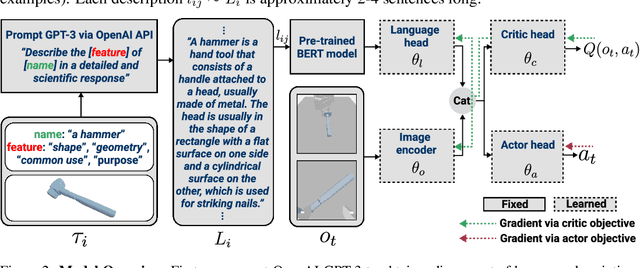
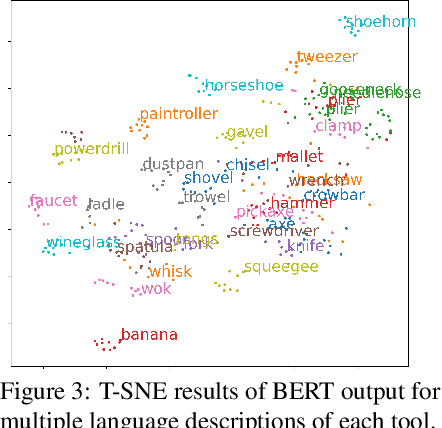
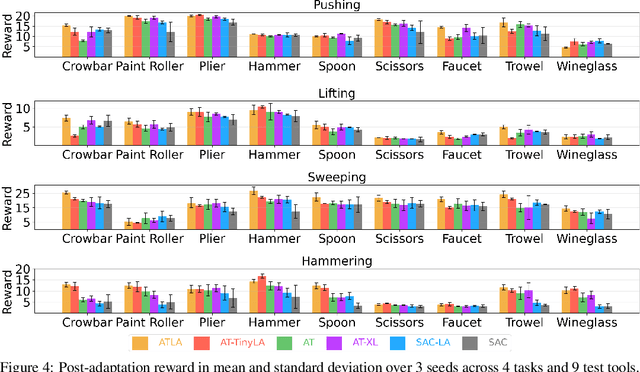
Robust and generalized tool manipulation requires an understanding of the properties and affordances of different tools. We investigate whether linguistic information about a tool (e.g., its geometry, common uses) can help control policies adapt faster to new tools for a given task. We obtain diverse descriptions of various tools in natural language and use pre-trained language models to generate their feature representations. We then perform language-conditioned meta-learning to learn policies that can efficiently adapt to new tools given their corresponding text descriptions. Our results demonstrate that combining linguistic information and meta-learning significantly accelerates tool learning in several manipulation tasks including pushing, lifting, sweeping, and hammering.
Safe Reinforcement Learning for Legged Locomotion
Mar 05, 2022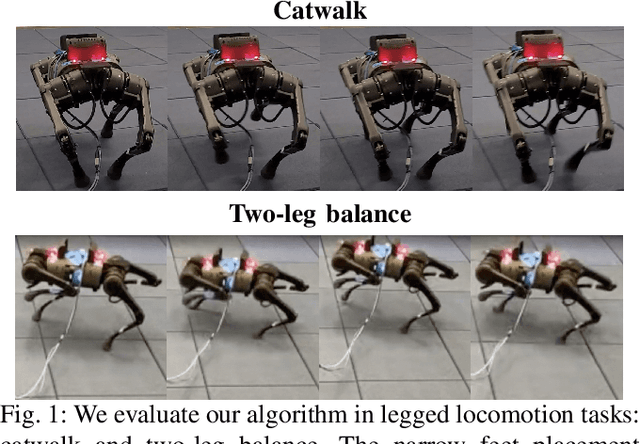
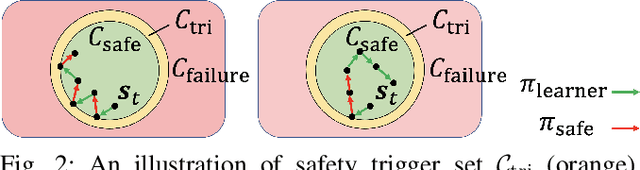


Designing control policies for legged locomotion is complex due to the under-actuated and non-continuous robot dynamics. Model-free reinforcement learning provides promising tools to tackle this challenge. However, a major bottleneck of applying model-free reinforcement learning in real world is safety. In this paper, we propose a safe reinforcement learning framework that switches between a safe recovery policy that prevents the robot from entering unsafe states, and a learner policy that is optimized to complete the task. The safe recovery policy takes over the control when the learner policy violates safety constraints, and hands over the control back when there are no future safety violations. We design the safe recovery policy so that it ensures safety of legged locomotion while minimally intervening in the learning process. Furthermore, we theoretically analyze the proposed framework and provide an upper bound on the task performance. We verify the proposed framework in four locomotion tasks on a simulated and real quadrupedal robot: efficient gait, catwalk, two-leg balance, and pacing. On average, our method achieves 48.6% fewer falls and comparable or better rewards than the baseline methods in simulation. When deployed it on real-world quadruped robot, our training pipeline enables 34% improvement in energy efficiency for the efficient gait, 40.9% narrower of the feet placement in the catwalk, and two times more jumping duration in the two-leg balance. Our method achieves less than five falls over the duration of 115 minutes of hardware time.
Safe Reinforcement Learning with Natural Language Constraints
Oct 11, 2020
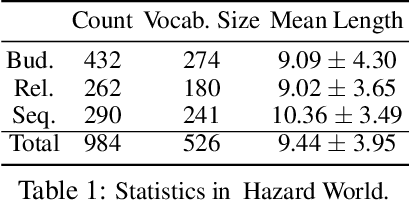
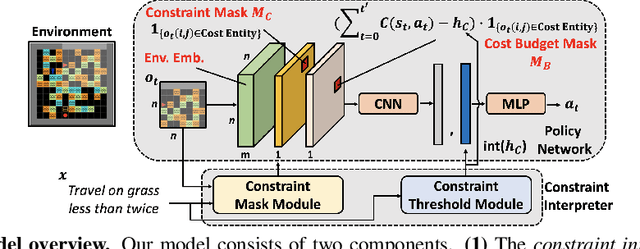
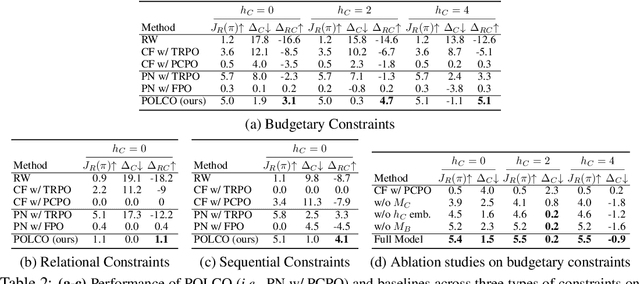
In this paper, we tackle the problem of learning control policies for tasks when provided with constraints in natural language. In contrast to instruction following, language here is used not to specify goals, but rather to describe situations that an agent must avoid during its exploration of the environment. Specifying constraints in natural language also differs from the predominant paradigm in safe reinforcement learning, where safety criteria are enforced by hand-defined cost functions. While natural language allows for easy and flexible specification of safety constraints and budget limitations, its ambiguous nature presents a challenge when mapping these specifications into representations that can be used by techniques for safe reinforcement learning. To address this, we develop a model that contains two components: (1) a constraint interpreter to encode natural language constraints into vector representations capturing spatial and temporal information on forbidden states, and (2) a policy network that uses these representations to output a policy with minimal constraint violations. Our model is end-to-end differentiable and we train it using a recently proposed algorithm for constrained policy optimization. To empirically demonstrate the effectiveness of our approach, we create a new benchmark task for autonomous navigation with crowd-sourced free-form text specifying three different types of constraints. Our method outperforms several baselines by achieving 6-7 times higher returns and 76% fewer constraint violations on average. Dataset and code to reproduce our experiments are available at https://sites.google.com/view/polco-hazard-world/.