 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePatchGuard: Provable Defense against Adversarial Patches Using Masks on Small Receptive Fields
Jun 08, 2020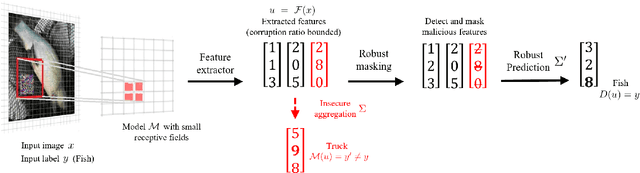

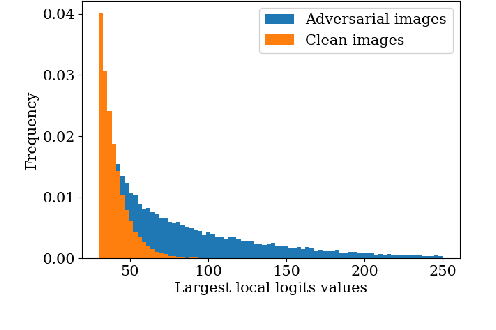
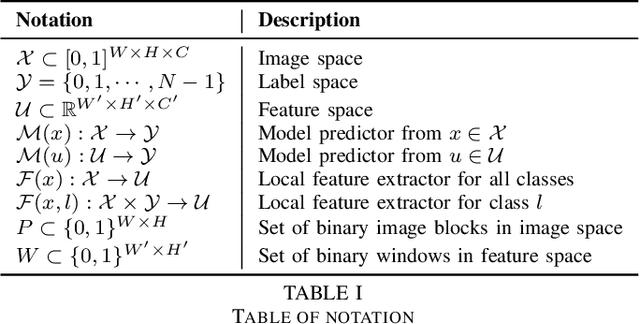
Localized adversarial patches aim to induce misclassification in machine learning models by arbitrarily modifying pixels within a restricted region of an image. Such attacks can be realized in the physical world by attaching the adversarial patch to the object to be misclassified. In this paper, we propose a general defense framework called PatchGuard that can achieve both high clean accuracy and provable robustness against localized adversarial patches. The cornerstone of PatchGuard is to use convolutional networks with small receptive fields that impose a bound on the number of features corrupted by an adversarial patch. Given a bound on the number of corrupted features, the problem of designing an adversarial patch defense reduces to that of designing a secure feature aggregation mechanism. Towards this end, we present our robust masking defense that robustly detects and masks corrupted features to recover the correct prediction. Our defense achieves state-of-the-art provable robust accuracy on ImageNette (a 10-class subset of ImageNet), ImageNet, and CIFAR-10 datasets. Against the strongest untargeted white-box adaptive attacker, we achieve 92.4% clean accuracy and 85.2% provable robust accuracy on 10-class ImageNette images against an adversarial patch consisting of 2% image pixels, 51.9% clean accuracy and 14.4% provable robust accuracy on 1000-class ImageNet images against a 2% pixel patch, and 80.0% clean accuracy and 62.2% provable accuracy on CIFAR-10 images against a 2.4% pixel patch.
Advances and Open Problems in Federated Learning
Dec 10, 2019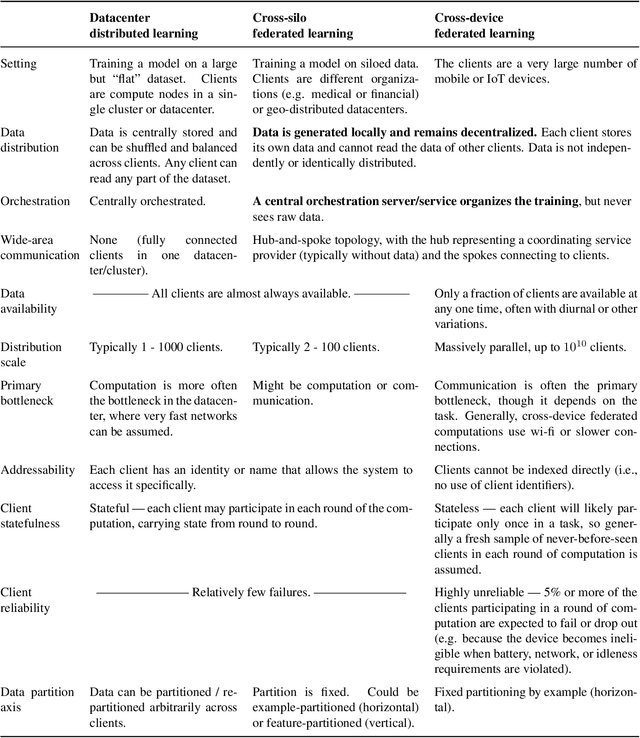
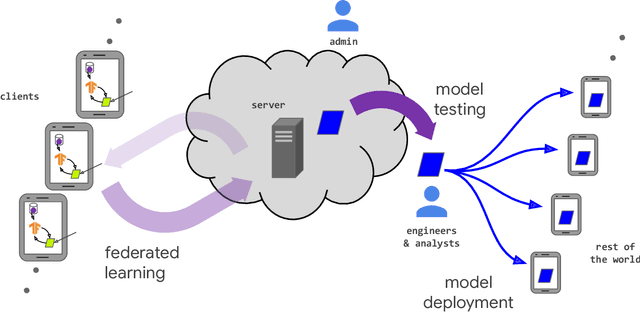
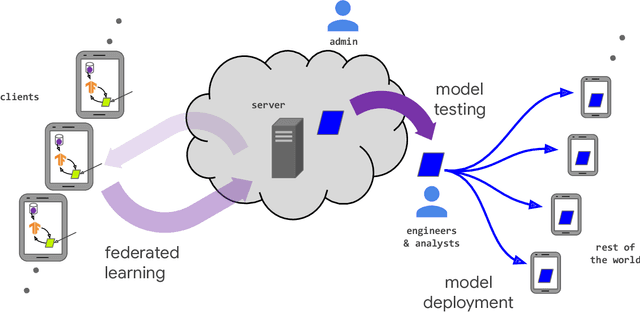

Federated learning (FL) is a machine learning setting where many clients (e.g. mobile devices or whole organizations) collaboratively train a model under the orchestration of a central server (e.g. service provider), while keeping the training data decentralized. FL embodies the principles of focused data collection and minimization, and can mitigate many of the systemic privacy risks and costs resulting from traditional, centralized machine learning and data science approaches. Motivated by the explosive growth in FL research, this paper discusses recent advances and presents an extensive collection of open problems and challenges.
Lower Bounds on Adversarial Robustness from Optimal Transport
Oct 30, 2019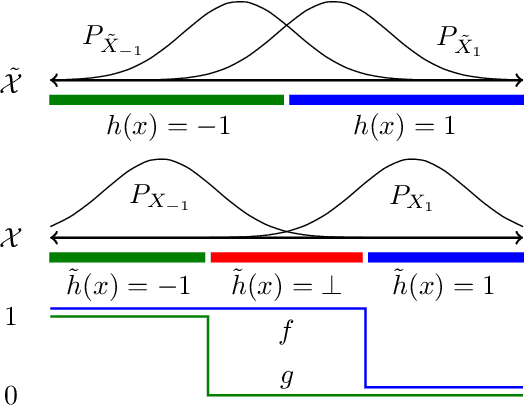
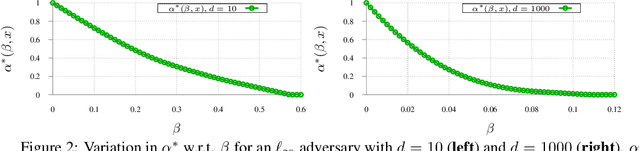
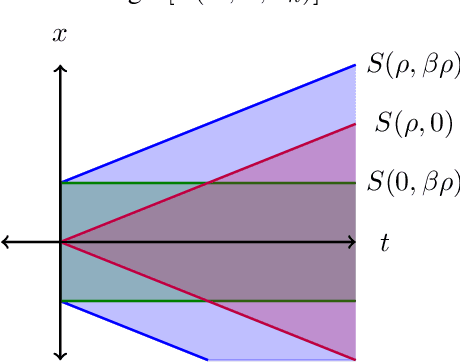

While progress has been made in understanding the robustness of machine learning classifiers to test-time adversaries (evasion attacks), fundamental questions remain unresolved. In this paper, we use optimal transport to characterize the minimum possible loss in an adversarial classification scenario. In this setting, an adversary receives a random labeled example from one of two classes, perturbs the example subject to a neighborhood constraint, and presents the modified example to the classifier. We define an appropriate cost function such that the minimum transportation cost between the distributions of the two classes determines the minimum $0-1$ loss for any classifier. When the classifier comes from a restricted hypothesis class, the optimal transportation cost provides a lower bound. We apply our framework to the case of Gaussian data with norm-bounded adversaries and explicitly show matching bounds for the classification and transport problems as well as the optimality of linear classifiers. We also characterize the sample complexity of learning in this setting, deriving and extending previously known results as a special case. Finally, we use our framework to study the gap between the optimal classification performance possible and that currently achieved by state-of-the-art robustly trained neural networks for datasets of interest, namely, MNIST, Fashion MNIST and CIFAR-10.
Better the Devil you Know: An Analysis of Evasion Attacks using Out-of-Distribution Adversarial Examples
May 05, 2019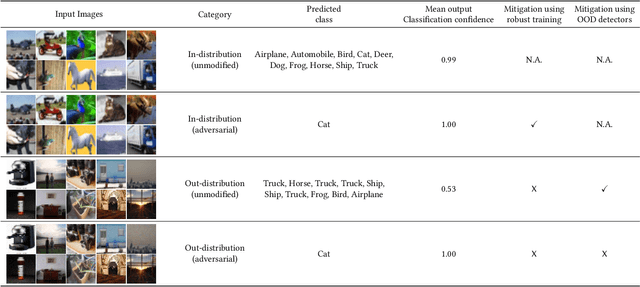
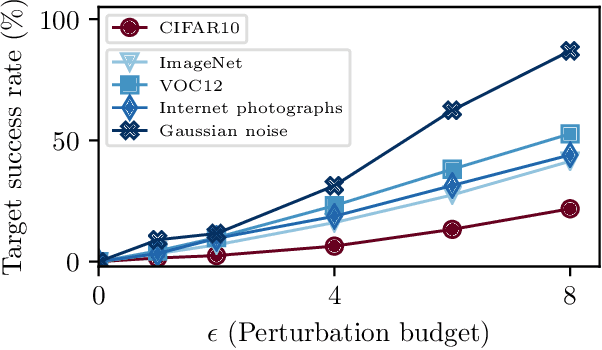
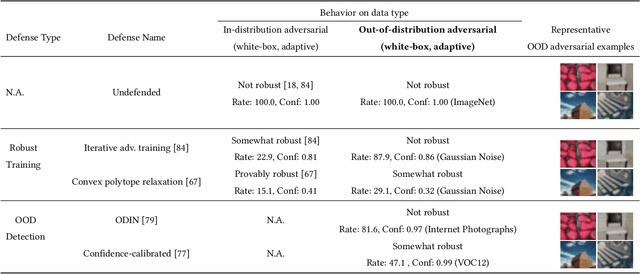
A large body of recent work has investigated the phenomenon of evasion attacks using adversarial examples for deep learning systems, where the addition of norm-bounded perturbations to the test inputs leads to incorrect output classification. Previous work has investigated this phenomenon in closed-world systems where training and test inputs follow a pre-specified distribution. However, real-world implementations of deep learning applications, such as autonomous driving and content classification are likely to operate in the open-world environment. In this paper, we demonstrate the success of open-world evasion attacks, where adversarial examples are generated from out-of-distribution inputs (OOD adversarial examples). In our study, we use 11 state-of-the-art neural network models trained on 3 image datasets of varying complexity. We first demonstrate that state-of-the-art detectors for out-of-distribution data are not robust against OOD adversarial examples. We then consider 5 known defenses for adversarial examples, including state-of-the-art robust training methods, and show that against these defenses, OOD adversarial examples can achieve up to 4$\times$ higher target success rates compared to adversarial examples generated from in-distribution data. We also take a quantitative look at how open-world evasion attacks may affect real-world systems. Finally, we present the first steps towards a robust open-world machine learning system.
Analyzing Federated Learning through an Adversarial Lens
Nov 29, 2018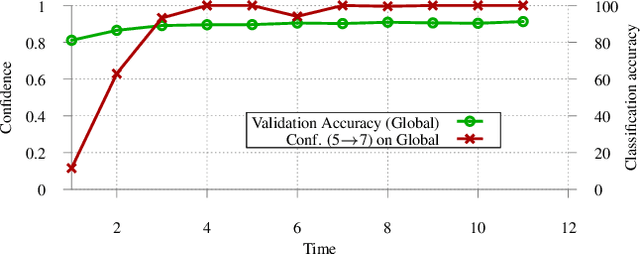
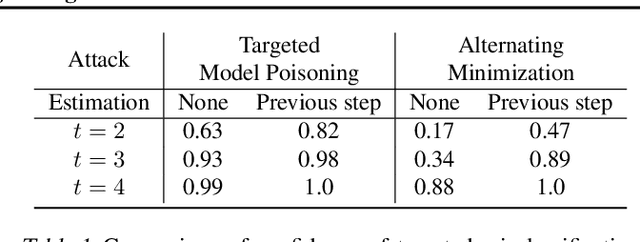
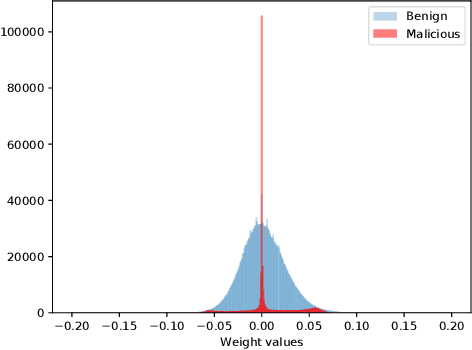
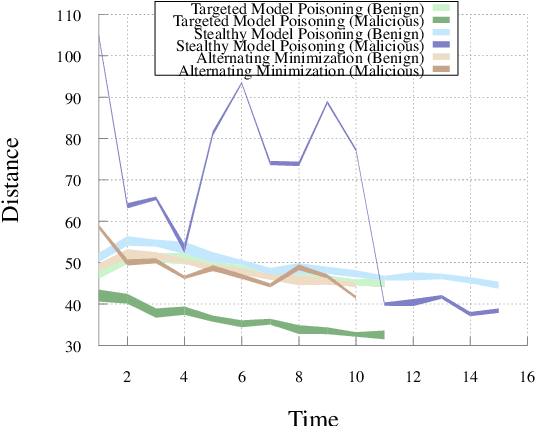
Federated learning distributes model training among a multitude of agents, who, guided by privacy concerns, perform training using their local data but share only model parameter updates, for iterative aggregation at the server. In this work, we explore the threat of model poisoning attacks on federated learning initiated by a single, non-colluding malicious agent where the adversarial objective is to cause the model to misclassify a set of chosen inputs with high confidence. We explore a number of strategies to carry out this attack, starting with simple boosting of the malicious agent's update to overcome the effects of other agents' updates. To increase attack stealth, we propose an alternating minimization strategy, which alternately optimizes for the training loss and the adversarial objective. We follow up by using parameter estimation for the benign agents' updates to improve on attack success. Finally, we use a suite of interpretability techniques to generate visual explanations of model decisions for both benign and malicious models and show that the explanations are nearly visually indistinguishable. Our results indicate that even a highly constrained adversary can carry out model poisoning attacks while simultaneously maintaining stealth, thus highlighting the vulnerability of the federated learning setting and the need to develop effective defense strategies.
PAC-learning in the presence of evasion adversaries
Jun 06, 2018
The existence of evasion attacks during the test phase of machine learning algorithms represents a significant challenge to both their deployment and understanding. These attacks can be carried out by adding imperceptible perturbations to inputs to generate adversarial examples and finding effective defenses and detectors has proven to be difficult. In this paper, we step away from the attack-defense arms race and seek to understand the limits of what can be learned in the presence of an evasion adversary. In particular, we extend the Probably Approximately Correct (PAC)-learning framework to account for the presence of an adversary. We first define corrupted hypothesis classes which arise from standard binary hypothesis classes in the presence of an evasion adversary and derive the Vapnik-Chervonenkis (VC)-dimension for these, denoted as the adversarial VC-dimension. We then show that sample complexity upper bounds from the Fundamental Theorem of Statistical learning can be extended to the case of evasion adversaries, where the sample complexity is controlled by the adversarial VC-dimension. We then explicitly derive the adversarial VC-dimension for halfspace classifiers in the presence of a sample-wise norm-constrained adversary of the type commonly studied for evasion attacks and show that it is the same as the standard VC-dimension, closing an open question. Finally, we prove that the adversarial VC-dimension can be either larger or smaller than the standard VC-dimension depending on the hypothesis class and adversary, making it an interesting object of study in its own right.
DARTS: Deceiving Autonomous Cars with Toxic Signs
May 31, 2018

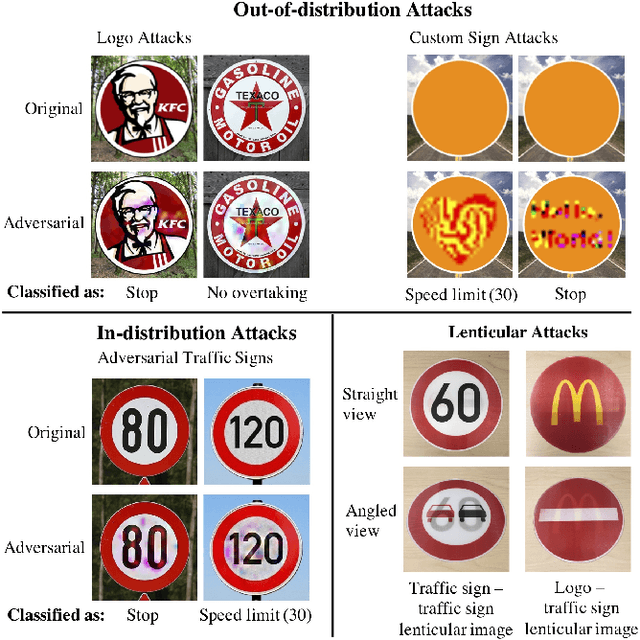

Sign recognition is an integral part of autonomous cars. Any misclassification of traffic signs can potentially lead to a multitude of disastrous consequences, ranging from a life-threatening accident to even a large-scale interruption of transportation services relying on autonomous cars. In this paper, we propose and examine security attacks against sign recognition systems for Deceiving Autonomous caRs with Toxic Signs (we call the proposed attacks DARTS). In particular, we introduce two novel methods to create these toxic signs. First, we propose Out-of-Distribution attacks, which expand the scope of adversarial examples by enabling the adversary to generate these starting from an arbitrary point in the image space compared to prior attacks which are restricted to existing training/test data (In-Distribution). Second, we present the Lenticular Printing attack, which relies on an optical phenomenon to deceive the traffic sign recognition system. We extensively evaluate the effectiveness of the proposed attacks in both virtual and real-world settings and consider both white-box and black-box threat models. Our results demonstrate that the proposed attacks are successful under both settings and threat models. We further show that Out-of-Distribution attacks can outperform In-Distribution attacks on classifiers defended using the adversarial training defense, exposing a new attack vector for these defenses.
Rogue Signs: Deceiving Traffic Sign Recognition with Malicious Ads and Logos
Mar 26, 2018
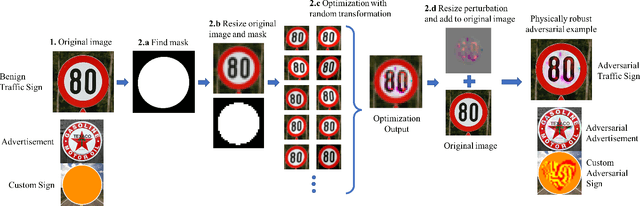
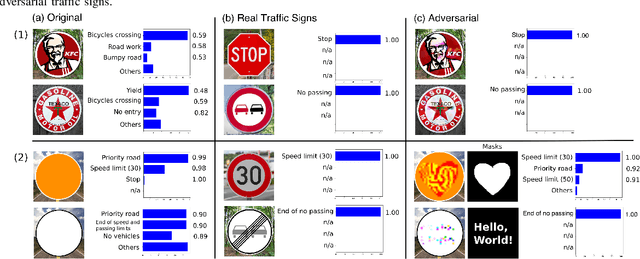

We propose a new real-world attack against the computer vision based systems of autonomous vehicles (AVs). Our novel Sign Embedding attack exploits the concept of adversarial examples to modify innocuous signs and advertisements in the environment such that they are classified as the adversary's desired traffic sign with high confidence. Our attack greatly expands the scope of the threat posed to AVs since adversaries are no longer restricted to just modifying existing traffic signs as in previous work. Our attack pipeline generates adversarial samples which are robust to the environmental conditions and noisy image transformations present in the physical world. We ensure this by including a variety of possible image transformations in the optimization problem used to generate adversarial samples. We verify the robustness of the adversarial samples by printing them out and carrying out drive-by tests simulating the conditions under which image capture would occur in a real-world scenario. We experimented with physical attack samples for different distances, lighting conditions and camera angles. In addition, extensive evaluations were carried out in the virtual setting for a variety of image transformations. The adversarial samples generated using our method have adversarial success rates in excess of 95% in the physical as well as virtual settings.
Exploring the Space of Black-box Attacks on Deep Neural Networks
Dec 27, 2017
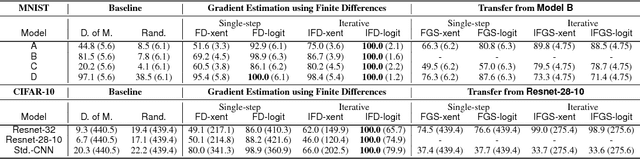
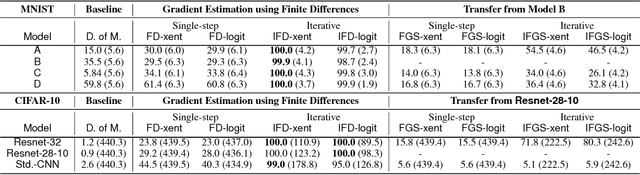
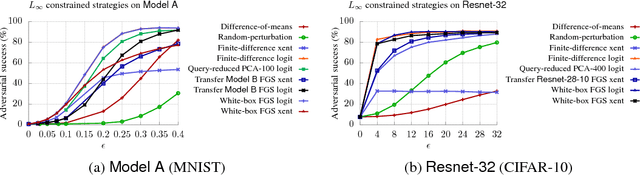
Existing black-box attacks on deep neural networks (DNNs) so far have largely focused on transferability, where an adversarial instance generated for a locally trained model can "transfer" to attack other learning models. In this paper, we propose novel Gradient Estimation black-box attacks for adversaries with query access to the target model's class probabilities, which do not rely on transferability. We also propose strategies to decouple the number of queries required to generate each adversarial sample from the dimensionality of the input. An iterative variant of our attack achieves close to 100% adversarial success rates for both targeted and untargeted attacks on DNNs. We carry out extensive experiments for a thorough comparative evaluation of black-box attacks and show that the proposed Gradient Estimation attacks outperform all transferability based black-box attacks we tested on both MNIST and CIFAR-10 datasets, achieving adversarial success rates similar to well known, state-of-the-art white-box attacks. We also apply the Gradient Estimation attacks successfully against a real-world Content Moderation classifier hosted by Clarifai. Furthermore, we evaluate black-box attacks against state-of-the-art defenses. We show that the Gradient Estimation attacks are very effective even against these defenses.
Enhancing Robustness of Machine Learning Systems via Data Transformations
Nov 29, 2017
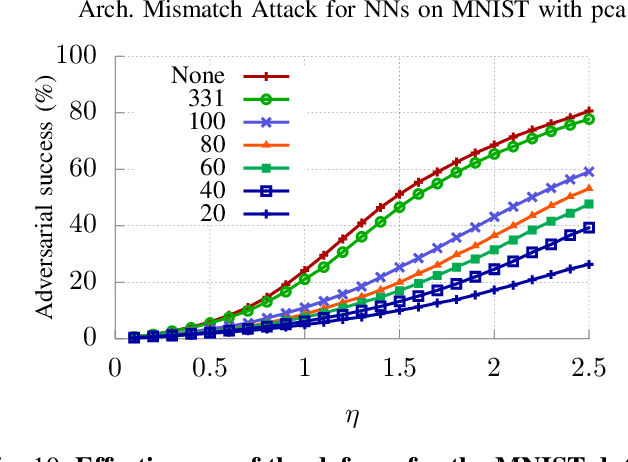
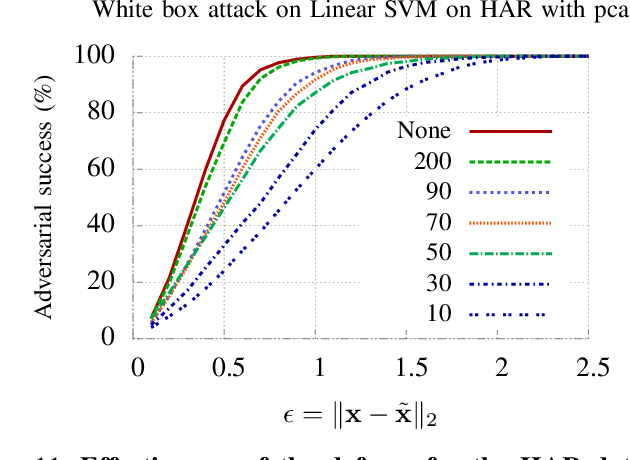
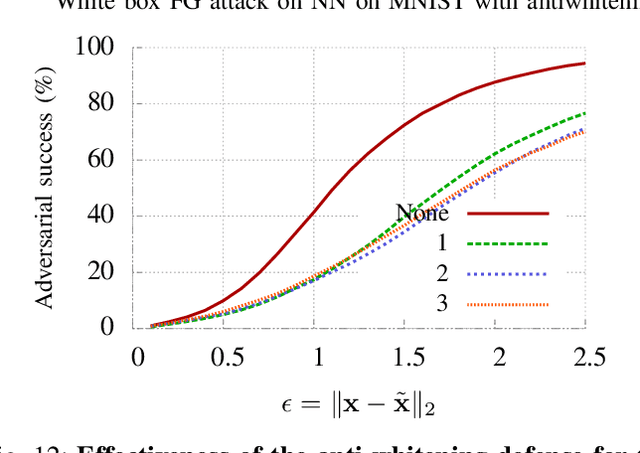
We propose the use of data transformations as a defense against evasion attacks on ML classifiers. We present and investigate strategies for incorporating a variety of data transformations including dimensionality reduction via Principal Component Analysis and data `anti-whitening' to enhance the resilience of machine learning, targeting both the classification and the training phase. We empirically evaluate and demonstrate the feasibility of linear transformations of data as a defense mechanism against evasion attacks using multiple real-world datasets. Our key findings are that the defense is (i) effective against the best known evasion attacks from the literature, resulting in a two-fold increase in the resources required by a white-box adversary with knowledge of the defense for a successful attack, (ii) applicable across a range of ML classifiers, including Support Vector Machines and Deep Neural Networks, and (iii) generalizable to multiple application domains, including image classification and human activity classification.