 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePatchGuard: Provable Defense against Adversarial Patches Using Masks on Small Receptive Fields
Paper and Code
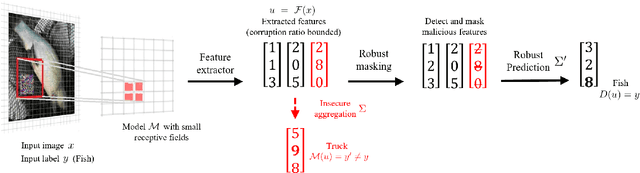

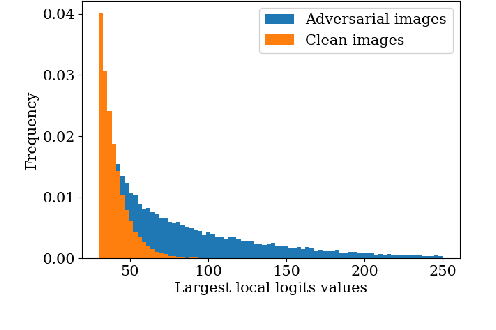
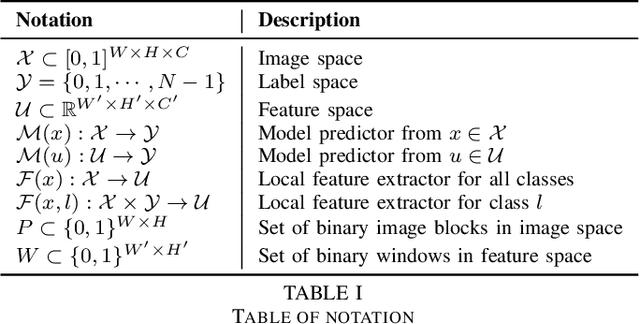
Localized adversarial patches aim to induce misclassification in machine learning models by arbitrarily modifying pixels within a restricted region of an image. Such attacks can be realized in the physical world by attaching the adversarial patch to the object to be misclassified. In this paper, we propose a general defense framework called PatchGuard that can achieve both high clean accuracy and provable robustness against localized adversarial patches. The cornerstone of PatchGuard is to use convolutional networks with small receptive fields that impose a bound on the number of features corrupted by an adversarial patch. Given a bound on the number of corrupted features, the problem of designing an adversarial patch defense reduces to that of designing a secure feature aggregation mechanism. Towards this end, we present our robust masking defense that robustly detects and masks corrupted features to recover the correct prediction. Our defense achieves state-of-the-art provable robust accuracy on ImageNette (a 10-class subset of ImageNet), ImageNet, and CIFAR-10 datasets. Against the strongest untargeted white-box adaptive attacker, we achieve 92.4% clean accuracy and 85.2% provable robust accuracy on 10-class ImageNette images against an adversarial patch consisting of 2% image pixels, 51.9% clean accuracy and 14.4% provable robust accuracy on 1000-class ImageNet images against a 2% pixel patch, and 80.0% clean accuracy and 62.2% provable accuracy on CIFAR-10 images against a 2.4% pixel patch.