 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOptimizing Server Placement for Vertical Federated Learning in Dynamic Edge/Fog Networks
May 10, 2026We investigate the control and optimization of vertical federated learning (VFL), a class of distributed machine learning (ML) methods in which edge/fog devices contain separate data features, in dynamic edge/fog networks. Owing to heterogeneous data features and hardware across edge/fog networks, devices' contributions to VFL vary substantially, and, moreover, dynamic edge/fog networks can lead to the permanent exit or entry of select data features. In this setting, our proposed methodology, server controlled VFL in dynamic networks (SC-DN), first establishes the existence of a global first-order stationary point for every global round, and then leverages this result to jointly optimize ML model training and resource consumption based on four key control variables: (i) server placement, (ii) device-to-server transmit power, (iii) local device processor frequency, and (iv) local training iterations per global round. The resulting optimization formulation contains coupled variables as well as numerous forms of logarithmic constraints which we show is a mixed-integer signomial program, an NP-hard problem, and for which we develop a general solver. Finally, via experiments on both image and multi-modal datasets, we show that our methodology demonstrates superior classification/regression performance and resource consumption savings than even greedy methodologies.
E-MPC: Edge-assisted Model Predictive Control
Oct 01, 2024



Model predictive control (MPC) has become the de facto standard action space for local planning and learning-based control in many continuous robotic control tasks, including autonomous driving. MPC solves a long-horizon cost optimization as a series of short-horizon optimizations based on a global planner-supplied reference path. The primary challenge in MPC, however, is that the computational budget for re-planning has a hard limit, which frequently inhibits exact optimization. Modern edge networks provide low-latency communication and heterogeneous properties that can be especially beneficial in this situation. We propose a novel framework for edge-assisted MPC (E-MPC) for path planning that exploits the heterogeneity of edge networks in three important ways: 1) varying computational capacity, 2) localized sensor information, and 3) localized observation histories. Theoretical analysis and extensive simulations are undertaken to demonstrate quantitatively the benefits of E-MPC in various scenarios, including maps, channel dynamics, and availability and density of edge nodes. The results confirm that E-MPC has the potential to reduce costs by a greater percentage than standard MPC does.
Cooperative Federated Learning over Ground-to-Satellite Integrated Networks: Joint Local Computation and Data Offloading
Dec 23, 2023



While network coverage maps continue to expand, many devices located in remote areas remain unconnected to terrestrial communication infrastructures, preventing them from getting access to the associated data-driven services. In this paper, we propose a ground-to-satellite cooperative federated learning (FL) methodology to facilitate machine learning service management over remote regions. Our methodology orchestrates satellite constellations to provide the following key functions during FL: (i) processing data offloaded from ground devices, (ii) aggregating models within device clusters, and (iii) relaying models/data to other satellites via inter-satellite links (ISLs). Due to the limited coverage time of each satellite over a particular remote area, we facilitate satellite transmission of trained models and acquired data to neighboring satellites via ISL, so that the incoming satellite can continue conducting FL for the region. We theoretically analyze the convergence behavior of our algorithm, and develop a training latency minimizer which optimizes over satellite-specific network resources, including the amount of data to be offloaded from ground devices to satellites and satellites' computation speeds. Through experiments on three datasets, we show that our methodology can significantly speed up the convergence of FL compared with terrestrial-only and other satellite baseline approaches.
Device Sampling and Resource Optimization for Federated Learning in Cooperative Edge Networks
Nov 07, 2023The conventional federated learning (FedL) architecture distributes machine learning (ML) across worker devices by having them train local models that are periodically aggregated by a server. FedL ignores two important characteristics of contemporary wireless networks, however: (i) the network may contain heterogeneous communication/computation resources, and (ii) there may be significant overlaps in devices' local data distributions. In this work, we develop a novel optimization methodology that jointly accounts for these factors via intelligent device sampling complemented by device-to-device (D2D) offloading. Our optimization methodology aims to select the best combination of sampled nodes and data offloading configuration to maximize FedL training accuracy while minimizing data processing and D2D communication resource consumption subject to realistic constraints on the network topology and device capabilities. Theoretical analysis of the D2D offloading subproblem leads to new FedL convergence bounds and an efficient sequential convex optimizer. Using these results, we develop a sampling methodology based on graph convolutional networks (GCNs) which learns the relationship between network attributes, sampled nodes, and D2D data offloading to maximize FedL accuracy. Through evaluation on popular datasets and real-world network measurements from our edge testbed, we find that our methodology outperforms popular device sampling methodologies from literature in terms of ML model performance, data processing overhead, and energy consumption.
Edge AI Inference in Heterogeneous Constrained Computing: Feasibility and Opportunities
Oct 27, 2023



The network edge's role in Artificial Intelligence (AI) inference processing is rapidly expanding, driven by a plethora of applications seeking computational advantages. These applications strive for data-driven efficiency, leveraging robust AI capabilities and prioritizing real-time responsiveness. However, as demand grows, so does system complexity. The proliferation of AI inference accelerators showcases innovation but also underscores challenges, particularly the varied software and hardware configurations of these devices. This diversity, while advantageous for certain tasks, introduces hurdles in device integration and coordination. In this paper, our objectives are three-fold. Firstly, we outline the requirements and components of a framework that accommodates hardware diversity. Next, we assess the impact of device heterogeneity on AI inference performance, identifying strategies to optimize outcomes without compromising service quality. Lastly, we shed light on the prevailing challenges and opportunities in this domain, offering insights for both the research community and industry stakeholders.
Asynchronous Multi-Model Federated Learning over Wireless Networks: Theory, Modeling, and Optimization
May 22, 2023Federated learning (FL) has emerged as a key technique for distributed machine learning (ML). Most literature on FL has focused on systems with (i) ML model training for a single task/model, (ii) a synchronous setting for uplink/downlink transfer of model parameters, which is often unrealistic. To address this, we develop MA-FL, which considers FL with multiple downstream tasks to be trained over an asynchronous model transmission architecture. We first characterize the convergence of ML model training under MA-FL via introducing a family of scheduling tensors to capture the scheduling of devices. Our convergence analysis sheds light on the impact of resource allocation (e.g., the mini-batch size and number of gradient descent iterations), device scheduling, and individual model states (i.e., warmed vs. cold initialization) on the performance of ML models. We then formulate a non-convex mixed integer optimization problem for jointly configuring the resource allocation and device scheduling to strike an efficient trade-off between energy consumption and ML performance, which is solved via successive convex approximations. Through numerical simulations, we reveal the advantages of MA-FL in terms of model performance and network resource savings.
Towards Cooperative Federated Learning over Heterogeneous Edge/Fog Networks
Mar 15, 2023



Federated learning (FL) has been promoted as a popular technique for training machine learning (ML) models over edge/fog networks. Traditional implementations of FL have largely neglected the potential for inter-network cooperation, treating edge/fog devices and other infrastructure participating in ML as separate processing elements. Consequently, FL has been vulnerable to several dimensions of network heterogeneity, such as varying computation capabilities, communication resources, data qualities, and privacy demands. We advocate for cooperative federated learning (CFL), a cooperative edge/fog ML paradigm built on device-to-device (D2D) and device-to-server (D2S) interactions. Through D2D and D2S cooperation, CFL counteracts network heterogeneity in edge/fog networks through enabling a model/data/resource pooling mechanism, which will yield substantial improvements in ML model training quality and network resource consumption. We propose a set of core methodologies that form the foundation of D2D and D2S cooperation and present preliminary experiments that demonstrate their benefits. We also discuss new FL functionalities enabled by this cooperative framework such as the integration of unlabeled data and heterogeneous device privacy into ML model training. Finally, we describe some open research directions at the intersection of cooperative edge/fog and FL.
Interference Cancellation GAN Framework for Dynamic Channels
Aug 17, 2022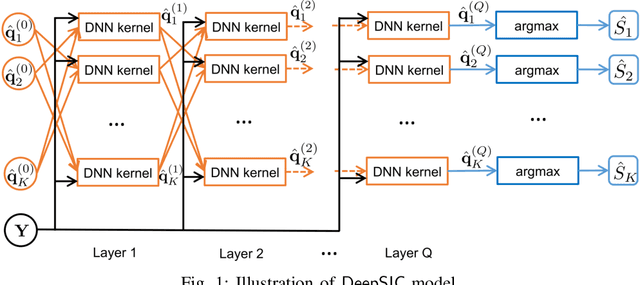
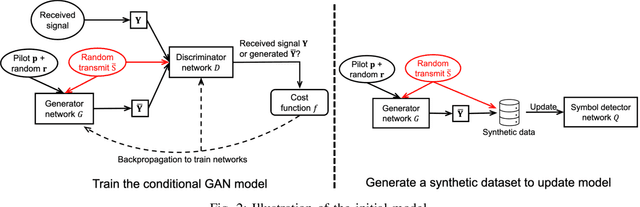
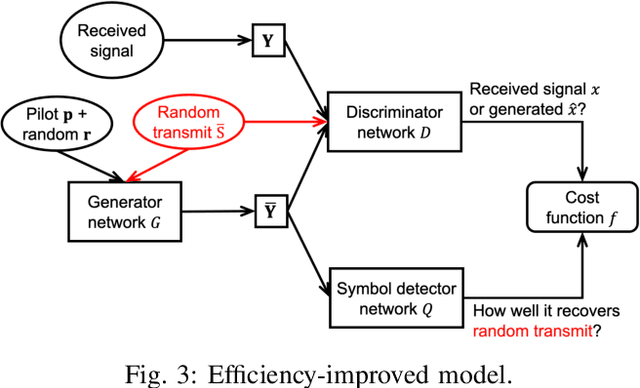
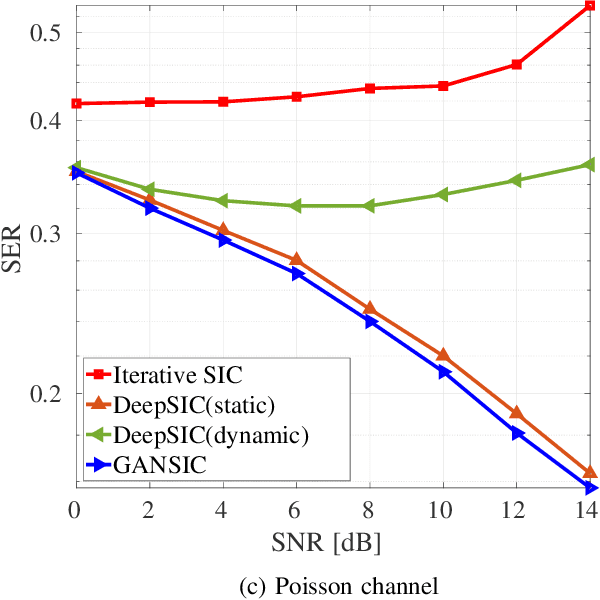
Symbol detection is a fundamental and challenging problem in modern communication systems, e.g., multiuser multiple-input multiple-output (MIMO) setting. Iterative Soft Interference Cancellation (SIC) is a state-of-the-art method for this task and recently motivated data-driven neural network models, e.g. DeepSIC, that can deal with unknown non-linear channels. However, these neural network models require thorough timeconsuming training of the networks before applying, and is thus not readily suitable for highly dynamic channels in practice. We introduce an online training framework that can swiftly adapt to any changes in the channel. Our proposed framework unifies the recent deep unfolding approaches with the emerging generative adversarial networks (GANs) to capture any changes in the channel and quickly adjust the networks to maintain the top performance of the model. We demonstrate that our framework significantly outperforms recent neural network models on highly dynamic channels and even surpasses those on the static channel in our experiments.
Embedding Alignment for Unsupervised Federated Learning via Smart Data Exchange
Aug 04, 2022


Federated learning (FL) has been recognized as one of the most promising solutions for distributed machine learning (ML). In most of the current literature, FL has been studied for supervised ML tasks, in which edge devices collect labeled data. Nevertheless, in many applications, it is impractical to assume existence of labeled data across devices. To this end, we develop a novel methodology, Cooperative Federated unsupervised Contrastive Learning (CF-CL), for FL across edge devices with unlabeled datasets. CF-CL employs local device cooperation where data are exchanged among devices through device-to-device (D2D) communications to avoid local model bias resulting from non-independent and identically distributed (non-i.i.d.) local datasets. CF-CL introduces a push-pull smart data sharing mechanism tailored to unsupervised FL settings, in which, each device pushes a subset of its local datapoints to its neighbors as reserved data points, and pulls a set of datapoints from its neighbors, sampled through a probabilistic importance sampling technique. We demonstrate that CF-CL leads to (i) alignment of unsupervised learned latent spaces across devices, (ii) faster global convergence, allowing for less frequent global model aggregations; and (iii) is effective in extreme non-i.i.d. data settings across the devices.
Multi-Edge Server-Assisted Dynamic Federated Learning with an Optimized Floating Aggregation Point
Mar 26, 2022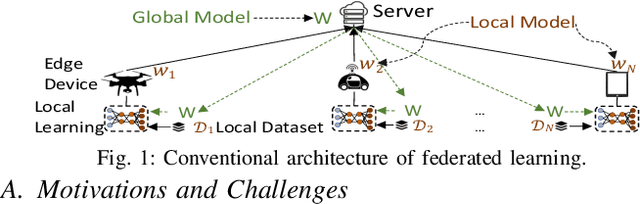
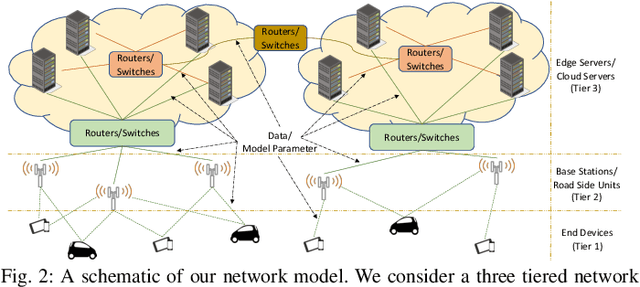
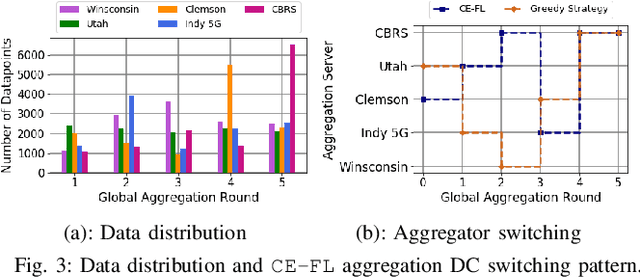
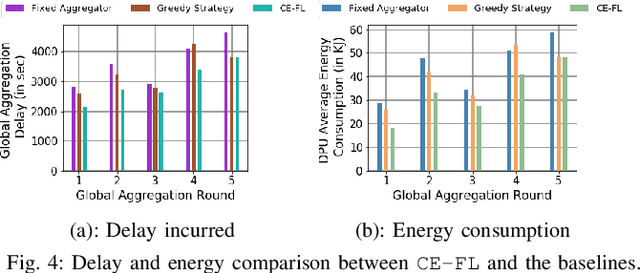
We propose cooperative edge-assisted dynamic federated learning (CE-FL). CE-FL introduces a distributed machine learning (ML) architecture, where data collection is carried out at the end devices, while the model training is conducted cooperatively at the end devices and the edge servers, enabled via data offloading from the end devices to the edge servers through base stations. CE-FL also introduces floating aggregation point, where the local models generated at the devices and the servers are aggregated at an edge server, which varies from one model training round to another to cope with the network evolution in terms of data distribution and users' mobility. CE-FL considers the heterogeneity of network elements in terms of communication/computation models and the proximity to one another. CE-FL further presumes a dynamic environment with online variation of data at the network devices which causes a drift at the ML model performance. We model the processes taken during CE-FL, and conduct analytical convergence analysis of its ML model training. We then formulate network-aware CE-FL which aims to adaptively optimize all the network elements via tuning their contribution to the learning process, which turns out to be a non-convex mixed integer problem. Motivated by the large scale of the system, we propose a distributed optimization solver to break down the computation of the solution across the network elements. We finally demonstrate the effectiveness of our framework with the data collected from a real-world testbed.