 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIdentification of Probabilities of Causation: A Complete Characterization
May 21, 2025Probabilities of causation are fundamental to modern decision-making. Pearl first introduced three binary probabilities of causation, and Tian and Pearl later derived tight bounds for them using Balke's linear programming. The theoretical characterization of probabilities of causation with multi-valued treatments and outcomes has remained unresolved for decades, limiting the scope of causality-based decision-making. In this paper, we resolve this foundational gap by proposing a complete set of representative probabilities of causation and proving that they are sufficient to characterize all possible probabilities of causation within the framework of Structural Causal Models (SCMs). We then formally derive tight bounds for these representative quantities using formal mathematical proofs. Finally, we demonstrate the practical relevance of our results through illustrative toy examples.
Scalable Defense against In-the-wild Jailbreaking Attacks with Safety Context Retrieval
May 21, 2025Large Language Models (LLMs) are known to be vulnerable to jailbreaking attacks, wherein adversaries exploit carefully engineered prompts to induce harmful or unethical responses. Such threats have raised critical concerns about the safety and reliability of LLMs in real-world deployment. While existing defense mechanisms partially mitigate such risks, subsequent advancements in adversarial techniques have enabled novel jailbreaking methods to circumvent these protections, exposing the limitations of static defense frameworks. In this work, we explore defending against evolving jailbreaking threats through the lens of context retrieval. First, we conduct a preliminary study demonstrating that even a minimal set of safety-aligned examples against a particular jailbreak can significantly enhance robustness against this attack pattern. Building on this insight, we further leverage the retrieval-augmented generation (RAG) techniques and propose Safety Context Retrieval (SCR), a scalable and robust safeguarding paradigm for LLMs against jailbreaking. Our comprehensive experiments demonstrate how SCR achieves superior defensive performance against both established and emerging jailbreaking tactics, contributing a new paradigm to LLM safety. Our code will be available upon publication.
CoIn: Counting the Invisible Reasoning Tokens in Commercial Opaque LLM APIs
May 19, 2025As post-training techniques evolve, large language models (LLMs) are increasingly augmented with structured multi-step reasoning abilities, often optimized through reinforcement learning. These reasoning-enhanced models outperform standard LLMs on complex tasks and now underpin many commercial LLM APIs. However, to protect proprietary behavior and reduce verbosity, providers typically conceal the reasoning traces while returning only the final answer. This opacity introduces a critical transparency gap: users are billed for invisible reasoning tokens, which often account for the majority of the cost, yet have no means to verify their authenticity. This opens the door to token count inflation, where providers may overreport token usage or inject synthetic, low-effort tokens to inflate charges. To address this issue, we propose CoIn, a verification framework that audits both the quantity and semantic validity of hidden tokens. CoIn constructs a verifiable hash tree from token embedding fingerprints to check token counts, and uses embedding-based relevance matching to detect fabricated reasoning content. Experiments demonstrate that CoIn, when deployed as a trusted third-party auditor, can effectively detect token count inflation with a success rate reaching up to 94.7%, showing the strong ability to restore billing transparency in opaque LLM services. The dataset and code are available at https://github.com/CASE-Lab-UMD/LLM-Auditing-CoIn.
VeriReason: Reinforcement Learning with Testbench Feedback for Reasoning-Enhanced Verilog Generation
May 17, 2025Automating Register Transfer Level (RTL) code generation using Large Language Models (LLMs) offers substantial promise for streamlining digital circuit design and reducing human effort. However, current LLM-based approaches face significant challenges with training data scarcity, poor specification-code alignment, lack of verification mechanisms, and balancing generalization with specialization. Inspired by DeepSeek-R1, we introduce VeriReason, a framework integrating supervised fine-tuning with Guided Reward Proximal Optimization (GRPO) reinforcement learning for RTL generation. Using curated training examples and a feedback-driven reward model, VeriReason combines testbench evaluations with structural heuristics while embedding self-checking capabilities for autonomous error correction. On the VerilogEval Benchmark, VeriReason delivers significant improvements: achieving 83.1% functional correctness on the VerilogEval Machine benchmark, substantially outperforming both comparable-sized models and much larger commercial systems like GPT-4 Turbo. Additionally, our approach demonstrates up to a 2.8X increase in first-attempt functional correctness compared to baseline methods and exhibits robust generalization to unseen designs. To our knowledge, VeriReason represents the first system to successfully integrate explicit reasoning capabilities with reinforcement learning for Verilog generation, establishing a new state-of-the-art for automated RTL synthesis. The models and datasets are available at: https://huggingface.co/collections/AI4EDA-CASE Code is Available at: https://github.com/NellyW8/VeriReason
FedHQ: Hybrid Runtime Quantization for Federated Learning
May 17, 2025Federated Learning (FL) is a decentralized model training approach that preserves data privacy but struggles with low efficiency. Quantization, a powerful training optimization technique, has been widely explored for integration into FL. However, many studies fail to consider the distinct performance attribution between particular quantization strategies, such as post-training quantization (PTQ) or quantization-aware training (QAT). As a result, existing FL quantization methods rely solely on either PTQ or QAT, optimizing for speed or accuracy while compromising the other. To efficiently accelerate FL and maintain distributed convergence accuracy across various FL settings, this paper proposes a hybrid quantitation approach combining PTQ and QAT for FL systems. We conduct case studies to validate the effectiveness of using hybrid quantization in FL. To solve the difficulty of modeling speed and accuracy caused by device and data heterogeneity, we propose a hardware-related analysis and data-distribution-related analysis to help identify the trade-off boundaries for strategy selection. Based on these, we proposed a novel framework named FedHQ to automatically adopt optimal hybrid strategy allocation for FL systems. Specifically, FedHQ develops a coarse-grained global initialization and fine-grained ML-based adjustment to ensure efficiency and robustness. Experiments show that FedHQ achieves up to 2.47x times training acceleration and up to 11.15% accuracy improvement and negligible extra overhead.
Bridging BCI and Communications: A MIMO Framework for EEG-to-ECoG Wireless Channel Modeling
May 16, 2025As a method to connect human brain and external devices, Brain-computer interfaces (BCIs) are receiving extensive research attention. Recently, the integration of communication theory with BCI has emerged as a popular trend, offering potential to enhance system performance and shape next-generation communications. A key challenge in this field is modeling the brain wireless communication channel between intracranial electrocorticography (ECoG) emitting neurons and extracranial electroencephalography (EEG) receiving electrodes. However, the complex physiology of brain challenges the application of traditional channel modeling methods, leaving relevant research in its infancy. To address this gap, we propose a frequency-division multiple-input multiple-output (MIMO) estimation framework leveraging simultaneous macaque EEG and ECoG recordings, while employing neurophysiology-informed regularization to suppress noise interference. This approach reveals profound similarities between neural signal propagation and multi-antenna communication systems. Experimental results show improved estimation accuracy over conventional methods while highlighting a trade-off between frequency resolution and temporal stability determined by signal duration. This work establish a conceptual bridge between neural interfacing and communication theory, accelerating synergistic developments in both fields.
Dynamic Domain Information Modulation Algorithm for Multi-domain Sentiment Analysis
May 10, 2025



Multi-domain sentiment classification aims to mitigate poor performance models due to the scarcity of labeled data in a single domain, by utilizing data labeled from various domains. A series of models that jointly train domain classifiers and sentiment classifiers have demonstrated their advantages, because domain classification helps generate necessary information for sentiment classification. Intuitively, the importance of sentiment classification tasks is the same in all domains for multi-domain sentiment classification; but domain classification tasks are different because the impact of domain information on sentiment classification varies across different fields; this can be controlled through adjustable weights or hyper parameters. However, as the number of domains increases, existing hyperparameter optimization algorithms may face the following challenges: (1) tremendous demand for computing resources, (2) convergence problems, and (3) high algorithm complexity. To efficiently generate the domain information required for sentiment classification in each domain, we propose a dynamic information modulation algorithm. Specifically, the model training process is divided into two stages. In the first stage, a shared hyperparameter, which would control the proportion of domain classification tasks across all fields, is determined. In the second stage, we introduce a novel domain-aware modulation algorithm to adjust the domain information contained in the input text, which is then calculated based on a gradient-based and loss-based method. In summary, experimental results on a public sentiment analysis dataset containing 16 domains prove the superiority of the proposed method.
SymRTLO: Enhancing RTL Code Optimization with LLMs and Neuron-Inspired Symbolic Reasoning
Apr 14, 2025



Optimizing Register Transfer Level (RTL) code is crucial for improving the power, performance, and area (PPA) of digital circuits in the early stages of synthesis. Manual rewriting, guided by synthesis feedback, can yield high-quality results but is time-consuming and error-prone. Most existing compiler-based approaches have difficulty handling complex design constraints. Large Language Model (LLM)-based methods have emerged as a promising alternative to address these challenges. However, LLM-based approaches often face difficulties in ensuring alignment between the generated code and the provided prompts. This paper presents SymRTLO, a novel neuron-symbolic RTL optimization framework that seamlessly integrates LLM-based code rewriting with symbolic reasoning techniques. Our method incorporates a retrieval-augmented generation (RAG) system of optimization rules and Abstract Syntax Tree (AST)-based templates, enabling LLM-based rewriting that maintains syntactic correctness while minimizing undesired circuit behaviors. A symbolic module is proposed for analyzing and optimizing finite state machine (FSM) logic, allowing fine-grained state merging and partial specification handling beyond the scope of pattern-based compilers. Furthermore, a fast verification pipeline, combining formal equivalence checks with test-driven validation, further reduces the complexity of verification. Experiments on the RTL-Rewriter benchmark with Synopsys Design Compiler and Yosys show that SymRTLO improves power, performance, and area (PPA) by up to 43.9%, 62.5%, and 51.1%, respectively, compared to the state-of-the-art methods.
Towards Stepwise Domain Knowledge-Driven Reasoning Optimization and Reflection Improvement
Apr 12, 2025
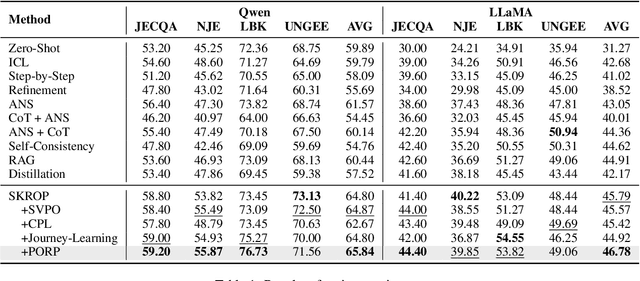
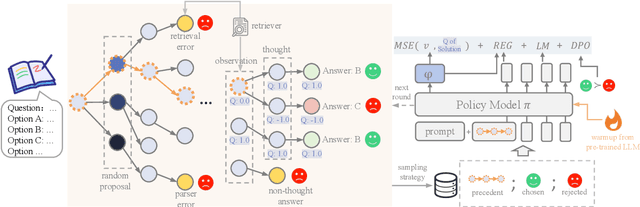
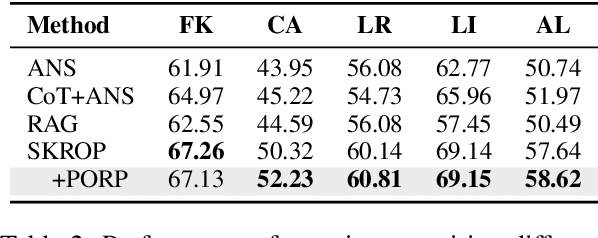
Recently, stepwise supervision on Chain of Thoughts (CoTs) presents an enhancement on the logical reasoning tasks such as coding and math, with the help of Monte Carlo Tree Search (MCTS). However, its contribution to tasks requiring domain-specific expertise and knowledge remains unexplored. Motivated by the interest, we identify several potential challenges of vanilla MCTS within this context, and propose the framework of Stepwise Domain Knowledge-Driven Reasoning Optimization, employing the MCTS algorithm to develop step-level supervision for problems that require essential comprehension, reasoning, and specialized knowledge. Additionally, we also introduce the Preference Optimization towards Reflection Paths, which iteratively learns self-reflection on the reasoning thoughts from better perspectives. We have conducted extensive experiments to evaluate the advantage of the methodologies. Empirical results demonstrate the effectiveness on various legal-domain problems. We also report a diverse set of valuable findings, hoping to encourage the enthusiasm to the research of domain-specific LLMs and MCTS.
ThermoStereoRT: Thermal Stereo Matching in Real Time via Knowledge Distillation and Attention-based Refinement
Apr 10, 2025We introduce ThermoStereoRT, a real-time thermal stereo matching method designed for all-weather conditions that recovers disparity from two rectified thermal stereo images, envisioning applications such as night-time drone surveillance or under-bed cleaning robots. Leveraging a lightweight yet powerful backbone, ThermoStereoRT constructs a 3D cost volume from thermal images and employs multi-scale attention mechanisms to produce an initial disparity map. To refine this map, we design a novel channel and spatial attention module. Addressing the challenge of sparse ground truth data in thermal imagery, we utilize knowledge distillation to boost performance without increasing computational demands. Comprehensive evaluations on multiple datasets demonstrate that ThermoStereoRT delivers both real-time capacity and robust accuracy, making it a promising solution for real-world deployment in various challenging environments. Our code will be released on https://github.com/SJTU-ViSYS-team/ThermoStereoRT
* 7 pages, 6 figures, 4 tables. Accepted to IEEE ICRA 2025. This is the preprint version