 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIn Defense of Image Pre-Training for Spatiotemporal Recognition
May 03, 2022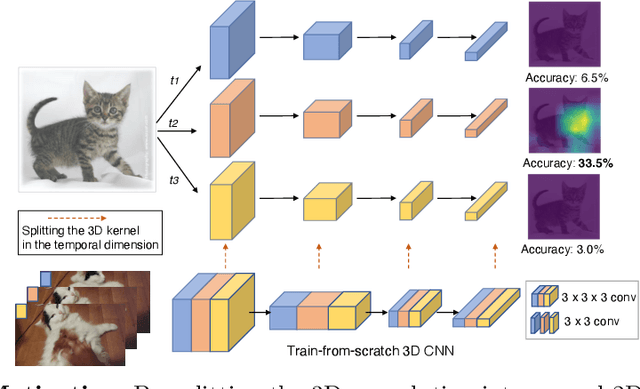
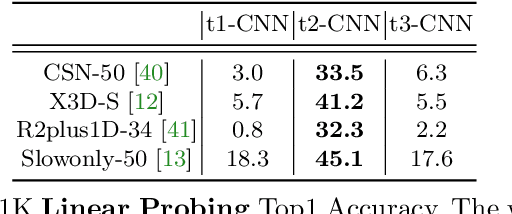
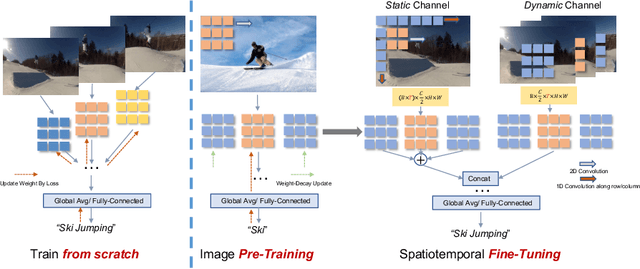

Image pre-training, the current de-facto paradigm for a wide range of visual tasks, is generally less favored in the field of video recognition. By contrast, a common strategy is to directly train with spatiotemporal convolutional neural networks (CNNs) from scratch. Nonetheless, interestingly, by taking a closer look at these from-scratch learned CNNs, we note there exist certain 3D kernels that exhibit much stronger appearance modeling ability than others, arguably suggesting appearance information is already well disentangled in learning. Inspired by this observation, we hypothesize that the key to effectively leveraging image pre-training lies in the decomposition of learning spatial and temporal features, and revisiting image pre-training as the appearance prior to initializing 3D kernels. In addition, we propose Spatial-Temporal Separable (STS) convolution, which explicitly splits the feature channels into spatial and temporal groups, to further enable a more thorough decomposition of spatiotemporal features for fine-tuning 3D CNNs. Our experiments show that simply replacing 3D convolution with STS notably improves a wide range of 3D CNNs without increasing parameters and computation on both Kinetics-400 and Something-Something V2. Moreover, this new training pipeline consistently achieves better results on video recognition with significant speedup. For instance, we achieve +0.6% top-1 of Slowfast on Kinetics-400 over the strong 256-epoch 128-GPU baseline while fine-tuning for only 50 epochs with 4 GPUs. The code and models are available at https://github.com/UCSC-VLAA/Image-Pretraining-for-Video.
Fast AdvProp
Apr 21, 2022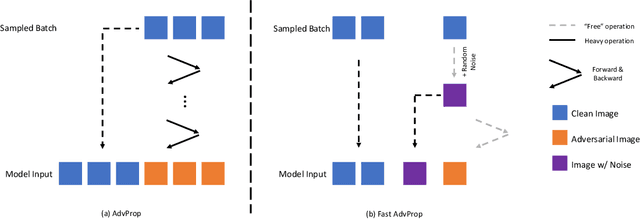


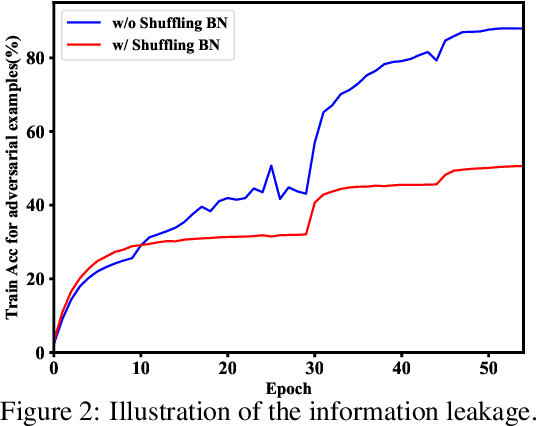
Adversarial Propagation (AdvProp) is an effective way to improve recognition models, leveraging adversarial examples. Nonetheless, AdvProp suffers from the extremely slow training speed, mainly because: a) extra forward and backward passes are required for generating adversarial examples; b) both original samples and their adversarial counterparts are used for training (i.e., 2$\times$ data). In this paper, we introduce Fast AdvProp, which aggressively revamps AdvProp's costly training components, rendering the method nearly as cheap as the vanilla training. Specifically, our modifications in Fast AdvProp are guided by the hypothesis that disentangled learning with adversarial examples is the key for performance improvements, while other training recipes (e.g., paired clean and adversarial training samples, multi-step adversarial attackers) could be largely simplified. Our empirical results show that, compared to the vanilla training baseline, Fast AdvProp is able to further model performance on a spectrum of visual benchmarks, without incurring extra training cost. Additionally, our ablations find Fast AdvProp scales better if larger models are used, is compatible with existing data augmentation methods (i.e., Mixup and CutMix), and can be easily adapted to other recognition tasks like object detection. The code is available here: https://github.com/meijieru/fast_advprop.
SwapMix: Diagnosing and Regularizing the Over-Reliance on Visual Context in Visual Question Answering
Apr 05, 2022

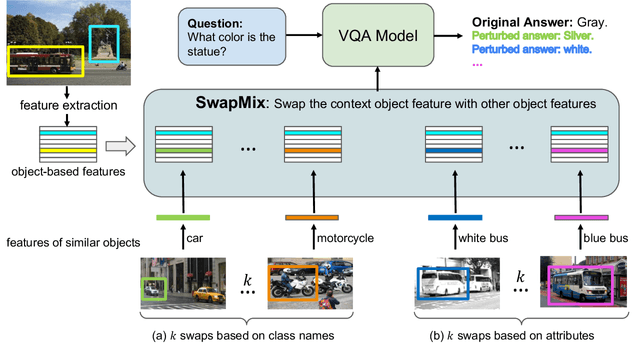
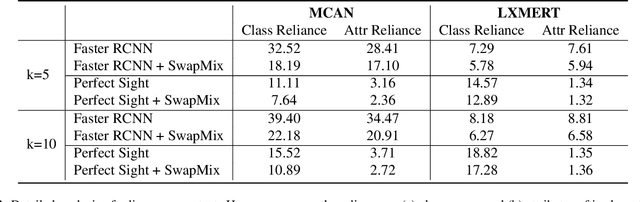
While Visual Question Answering (VQA) has progressed rapidly, previous works raise concerns about robustness of current VQA models. In this work, we study the robustness of VQA models from a novel perspective: visual context. We suggest that the models over-rely on the visual context, i.e., irrelevant objects in the image, to make predictions. To diagnose the model's reliance on visual context and measure their robustness, we propose a simple yet effective perturbation technique, SwapMix. SwapMix perturbs the visual context by swapping features of irrelevant context objects with features from other objects in the dataset. Using SwapMix we are able to change answers to more than 45 % of the questions for a representative VQA model. Additionally, we train the models with perfect sight and find that the context over-reliance highly depends on the quality of visual representations. In addition to diagnosing, SwapMix can also be applied as a data augmentation strategy during training in order to regularize the context over-reliance. By swapping the context object features, the model reliance on context can be suppressed effectively. Two representative VQA models are studied using SwapMix: a co-attention model MCAN and a large-scale pretrained model LXMERT. Our experiments on the popular GQA dataset show the effectiveness of SwapMix for both diagnosing model robustness and regularizing the over-reliance on visual context. The code for our method is available at https://github.com/vipulgupta1011/swapmix
CP2: Copy-Paste Contrastive Pretraining for Semantic Segmentation
Mar 22, 2022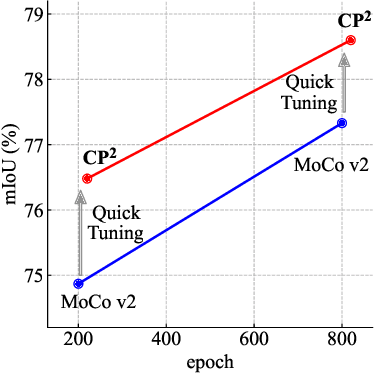
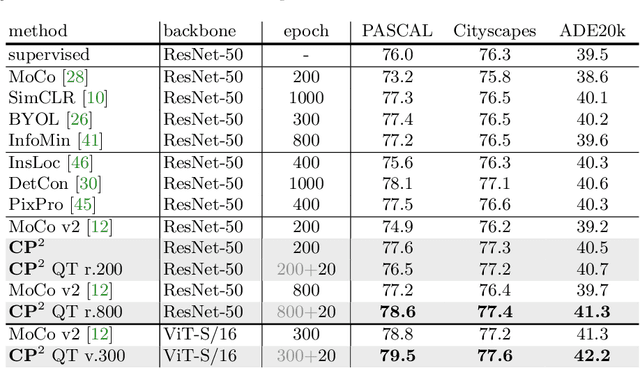
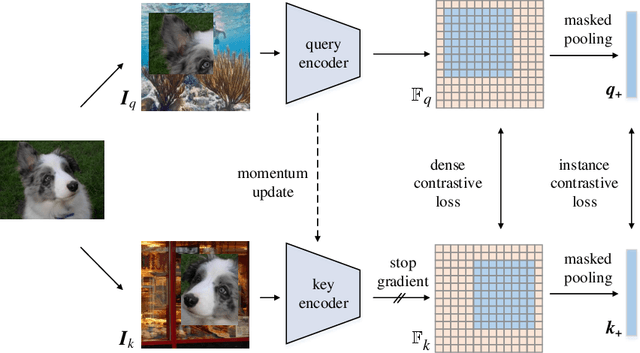
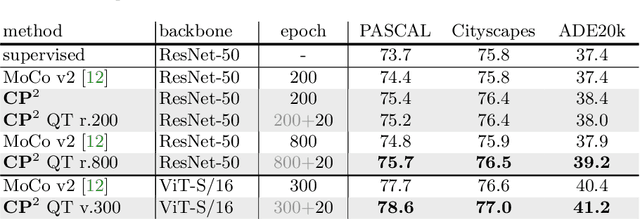
Recent advances in self-supervised contrastive learning yield good image-level representation, which favors classification tasks but usually neglects pixel-level detailed information, leading to unsatisfactory transfer performance to dense prediction tasks such as semantic segmentation. In this work, we propose a pixel-wise contrastive learning method called CP2 (Copy-Paste Contrastive Pretraining), which facilitates both image- and pixel-level representation learning and therefore is more suitable for downstream dense prediction tasks. In detail, we copy-paste a random crop from an image (the foreground) onto different background images and pretrain a semantic segmentation model with the objective of 1) distinguishing the foreground pixels from the background pixels, and 2) identifying the composed images that share the same foreground.Experiments show the strong performance of CP2 in downstream semantic segmentation: By finetuning CP2 pretrained models on PASCAL VOC 2012, we obtain 78.6% mIoU with a ResNet-50 and 79.5% with a ViT-S.
DeepFusion: Lidar-Camera Deep Fusion for Multi-Modal 3D Object Detection
Mar 15, 2022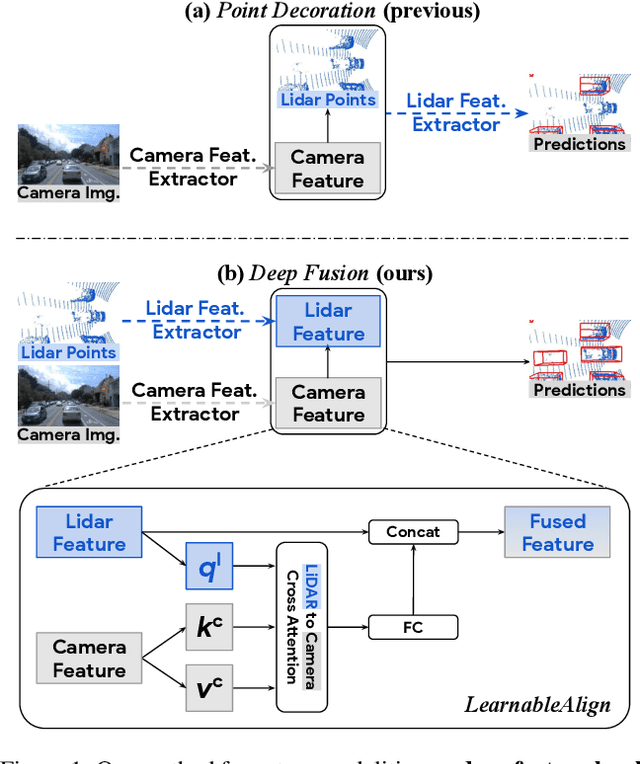
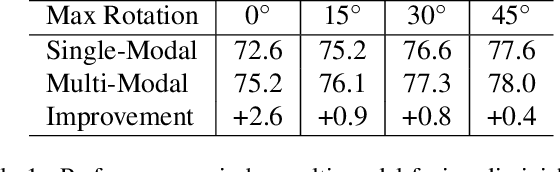
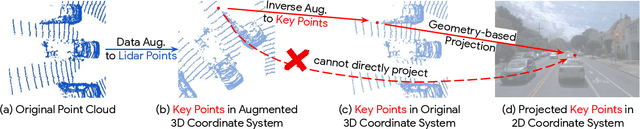
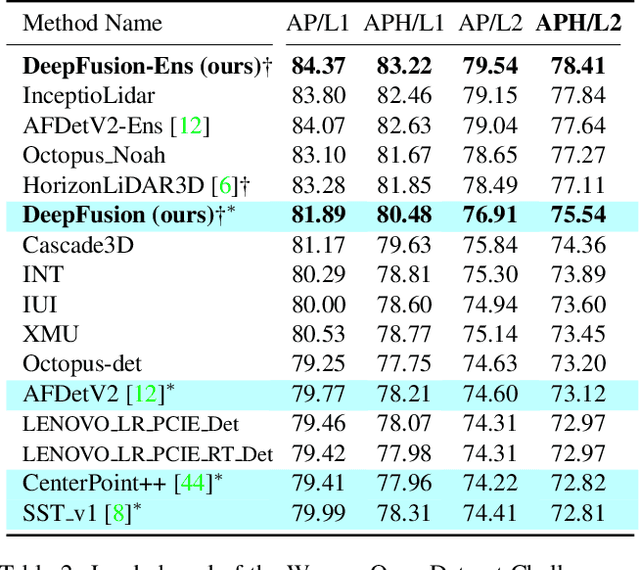
Lidars and cameras are critical sensors that provide complementary information for 3D detection in autonomous driving. While prevalent multi-modal methods simply decorate raw lidar point clouds with camera features and feed them directly to existing 3D detection models, our study shows that fusing camera features with deep lidar features instead of raw points, can lead to better performance. However, as those features are often augmented and aggregated, a key challenge in fusion is how to effectively align the transformed features from two modalities. In this paper, we propose two novel techniques: InverseAug that inverses geometric-related augmentations, e.g., rotation, to enable accurate geometric alignment between lidar points and image pixels, and LearnableAlign that leverages cross-attention to dynamically capture the correlations between image and lidar features during fusion. Based on InverseAug and LearnableAlign, we develop a family of generic multi-modal 3D detection models named DeepFusion, which is more accurate than previous methods. For example, DeepFusion improves PointPillars, CenterPoint, and 3D-MAN baselines on Pedestrian detection for 6.7, 8.9, and 6.2 LEVEL_2 APH, respectively. Notably, our models achieve state-of-the-art performance on Waymo Open Dataset, and show strong model robustness against input corruptions and out-of-distribution data. Code will be publicly available at https://github.com/tensorflow/lingvo/tree/master/lingvo/.
Point-Level Region Contrast for Object Detection Pre-Training
Feb 09, 2022
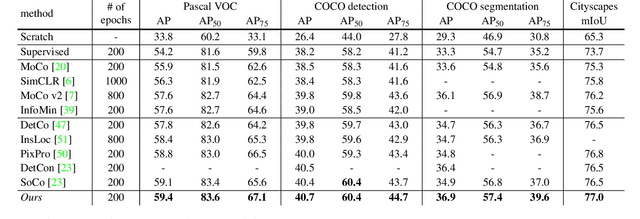
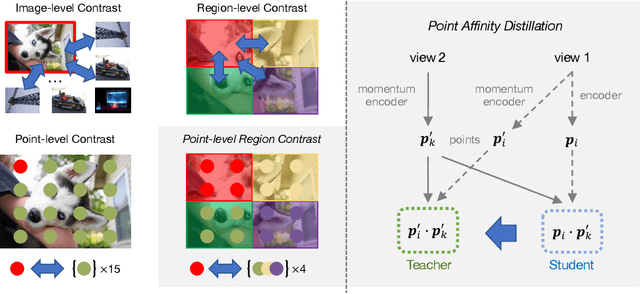

In this work we present point-level region contrast, a self-supervised pre-training approach for the task of object detection. This approach is motivated by the two key factors in detection: localization and recognition. While accurate localization favors models that operate at the pixel- or point-level, correct recognition typically relies on a more holistic, region-level view of objects. Incorporating this perspective in pre-training, our approach performs contrastive learning by directly sampling individual point pairs from different regions. Compared to an aggregated representation per region, our approach is more robust to the change in input region quality, and further enables us to implicitly improve initial region assignments via online knowledge distillation during training. Both advantages are important when dealing with imperfect regions encountered in the unsupervised setting. Experiments show point-level region contrast improves on state-of-the-art pre-training methods for object detection and segmentation across multiple tasks and datasets, and we provide extensive ablation studies and visualizations to aid understanding. Code will be made available.
Lite Vision Transformer with Enhanced Self-Attention
Dec 20, 2021
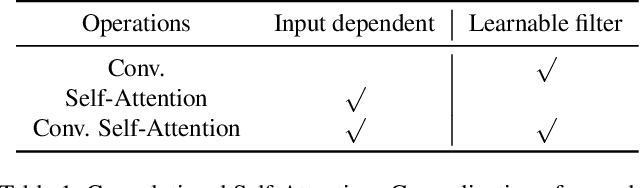
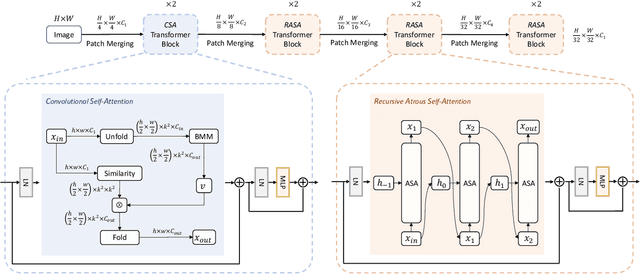
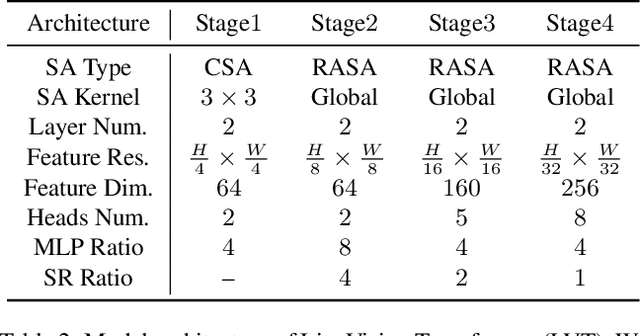
Despite the impressive representation capacity of vision transformer models, current light-weight vision transformer models still suffer from inconsistent and incorrect dense predictions at local regions. We suspect that the power of their self-attention mechanism is limited in shallower and thinner networks. We propose Lite Vision Transformer (LVT), a novel light-weight transformer network with two enhanced self-attention mechanisms to improve the model performances for mobile deployment. For the low-level features, we introduce Convolutional Self-Attention (CSA). Unlike previous approaches of merging convolution and self-attention, CSA introduces local self-attention into the convolution within a kernel of size 3x3 to enrich low-level features in the first stage of LVT. For the high-level features, we propose Recursive Atrous Self-Attention (RASA), which utilizes the multi-scale context when calculating the similarity map and a recursive mechanism to increase the representation capability with marginal extra parameter cost. The superiority of LVT is demonstrated on ImageNet recognition, ADE20K semantic segmentation, and COCO panoptic segmentation. The code is made publicly available.
Masked Feature Prediction for Self-Supervised Visual Pre-Training
Dec 16, 2021

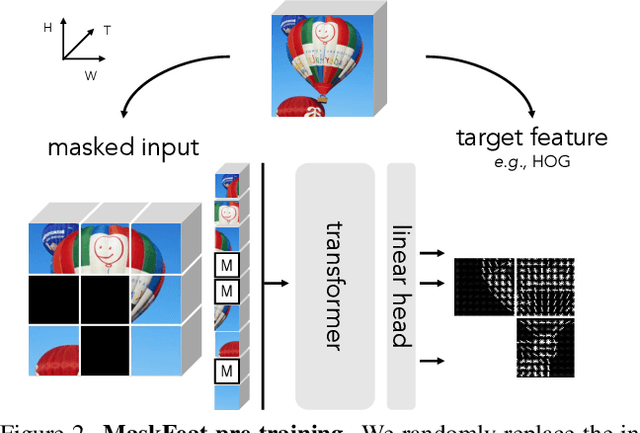
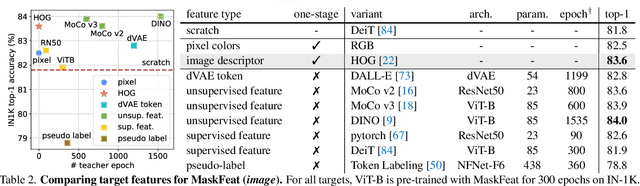
We present Masked Feature Prediction (MaskFeat) for self-supervised pre-training of video models. Our approach first randomly masks out a portion of the input sequence and then predicts the feature of the masked regions. We study five different types of features and find Histograms of Oriented Gradients (HOG), a hand-crafted feature descriptor, works particularly well in terms of both performance and efficiency. We observe that the local contrast normalization in HOG is essential for good results, which is in line with earlier work using HOG for visual recognition. Our approach can learn abundant visual knowledge and drive large-scale Transformer-based models. Without using extra model weights or supervision, MaskFeat pre-trained on unlabeled videos achieves unprecedented results of 86.7% with MViT-L on Kinetics-400, 88.3% on Kinetics-600, 80.4% on Kinetics-700, 38.8 mAP on AVA, and 75.0% on SSv2. MaskFeat further generalizes to image input, which can be interpreted as a video with a single frame and obtains competitive results on ImageNet.
Learning from Temporal Gradient for Semi-supervised Action Recognition
Dec 06, 2021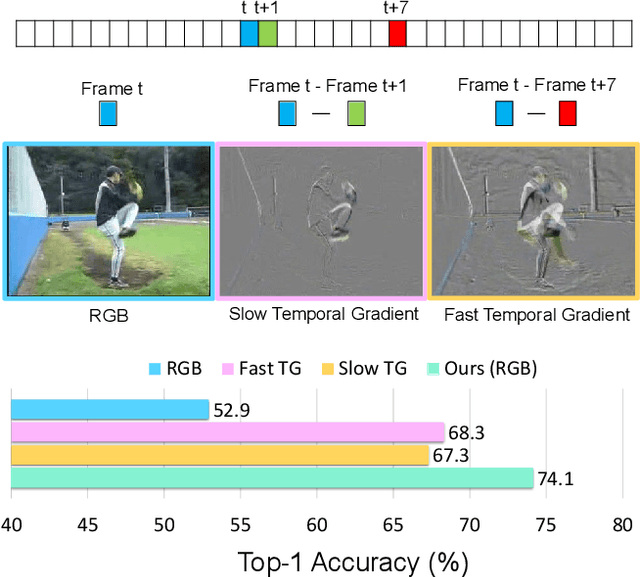
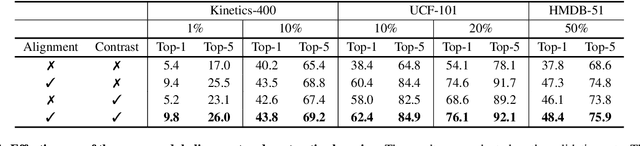
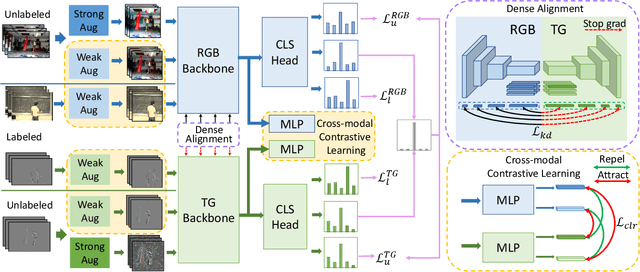
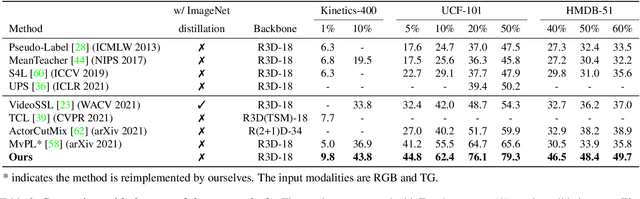
Semi-supervised video action recognition tends to enable deep neural networks to achieve remarkable performance even with very limited labeled data. However, existing methods are mainly transferred from current image-based methods (e.g., FixMatch). Without specifically utilizing the temporal dynamics and inherent multimodal attributes, their results could be suboptimal. To better leverage the encoded temporal information in videos, we introduce temporal gradient as an additional modality for more attentive feature extraction in this paper. To be specific, our method explicitly distills the fine-grained motion representations from temporal gradient (TG) and imposes consistency across different modalities (i.e., RGB and TG). The performance of semi-supervised action recognition is significantly improved without additional computation or parameters during inference. Our method achieves the state-of-the-art performance on three video action recognition benchmarks (i.e., Kinetics-400, UCF-101, and HMDB-51) under several typical semi-supervised settings (i.e., different ratios of labeled data).
MT-TransUNet: Mediating Multi-Task Tokens in Transformers for Skin Lesion Segmentation and Classification
Dec 03, 2021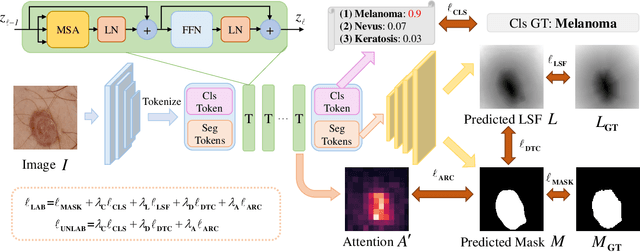
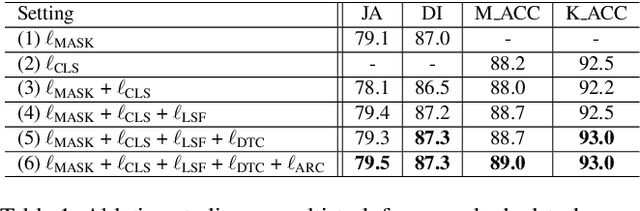
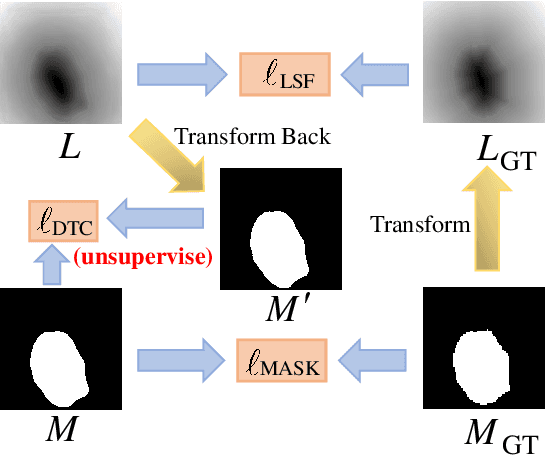
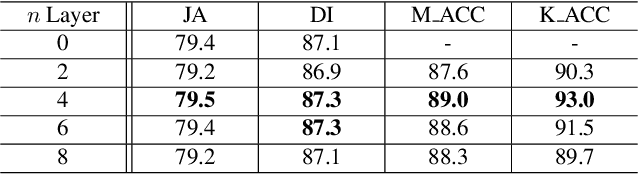
Recent advances in automated skin cancer diagnosis have yielded performance on par with board-certified dermatologists. However, these approaches formulated skin cancer diagnosis as a simple classification task, dismissing the potential benefit from lesion segmentation. We argue that an accurate lesion segmentation can supplement the classification task with additive lesion information, such as asymmetry, border, intensity, and physical size; in turn, a faithful lesion classification can support the segmentation task with discriminant lesion features. To this end, this paper proposes a new multi-task framework, named MT-TransUNet, which is capable of segmenting and classifying skin lesions collaboratively by mediating multi-task tokens in Transformers. Furthermore, we have introduced dual-task and attended region consistency losses to take advantage of those images without pixel-level annotation, ensuring the model's robustness when it encounters the same image with an account of augmentation. Our MT-TransUNet exceeds the previous state of the art for lesion segmentation and classification tasks in ISIC-2017 and PH2; more importantly, it preserves compelling computational efficiency regarding model parameters (48M~vs.~130M) and inference speed (0.17s~vs.~2.02s per image). Code will be available at https://github.com/JingyeChen/MT-TransUNet.