 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLanguage Model Beats Diffusion -- Tokenizer is Key to Visual Generation
Oct 09, 2023While Large Language Models (LLMs) are the dominant models for generative tasks in language, they do not perform as well as diffusion models on image and video generation. To effectively use LLMs for visual generation, one crucial component is the visual tokenizer that maps pixel-space inputs to discrete tokens appropriate for LLM learning. In this paper, we introduce MAGVIT-v2, a video tokenizer designed to generate concise and expressive tokens for both videos and images using a common token vocabulary. Equipped with this new tokenizer, we show that LLMs outperform diffusion models on standard image and video generation benchmarks including ImageNet and Kinetics. In addition, we demonstrate that our tokenizer surpasses the previously top-performing video tokenizer on two more tasks: (1) video compression comparable to the next-generation video codec (VCC) according to human evaluations, and (2) learning effective representations for action recognition tasks.
RoboCat: A Self-Improving Foundation Agent for Robotic Manipulation
Jun 20, 2023



The ability to leverage heterogeneous robotic experience from different robots and tasks to quickly master novel skills and embodiments has the potential to transform robot learning. Inspired by recent advances in foundation models for vision and language, we propose a foundation agent for robotic manipulation. This agent, named RoboCat, is a visual goal-conditioned decision transformer capable of consuming multi-embodiment action-labelled visual experience. This data spans a large repertoire of motor control skills from simulated and real robotic arms with varying sets of observations and actions. With RoboCat, we demonstrate the ability to generalise to new tasks and robots, both zero-shot as well as through adaptation using only 100--1000 examples for the target task. We also show how a trained model itself can be used to generate data for subsequent training iterations, thus providing a basic building block for an autonomous improvement loop. We investigate the agent's capabilities, with large-scale evaluations both in simulation and on three different real robot embodiments. We find that as we grow and diversify its training data, RoboCat not only shows signs of cross-task transfer, but also becomes more efficient at adapting to new tasks.
Siamese Masked Autoencoders
May 23, 2023Establishing correspondence between images or scenes is a significant challenge in computer vision, especially given occlusions, viewpoint changes, and varying object appearances. In this paper, we present Siamese Masked Autoencoders (SiamMAE), a simple extension of Masked Autoencoders (MAE) for learning visual correspondence from videos. SiamMAE operates on pairs of randomly sampled video frames and asymmetrically masks them. These frames are processed independently by an encoder network, and a decoder composed of a sequence of cross-attention layers is tasked with predicting the missing patches in the future frame. By masking a large fraction ($95\%$) of patches in the future frame while leaving the past frame unchanged, SiamMAE encourages the network to focus on object motion and learn object-centric representations. Despite its conceptual simplicity, features learned via SiamMAE outperform state-of-the-art self-supervised methods on video object segmentation, pose keypoint propagation, and semantic part propagation tasks. SiamMAE achieves competitive results without relying on data augmentation, handcrafted tracking-based pretext tasks, or other techniques to prevent representational collapse.
GreenMO: Virtualized User-proportionate MIMO
Nov 29, 2022



With the turn of new decade, wireless communications face a major challenge on connecting many more new users and devices, at the same time being energy efficient and minimizing its carbon footprint. However, the current approaches to address the growing number of users and spectrum demands, like traditional fully digital architectures for Massive MIMO, demand exorbitant energy consumption. The reason is that traditionally MIMO requires a separate RF chain per antenna, so the power consumption scales with number of antennas, instead of number of users, hence becomes energy inefficient. Instead, GreenMO creates a new massive MIMO architecture which is able to use many more antennas while keeping power consumption to user-proportionate numbers. To achieve this GreenMO introduces for the first time, the concept of virtualization of the RF chain hardware. Instead of laying the RF chains physically to each antenna, GreenMO creates these RF chains virtually in digital domain. This also enables GreenMO to be the first flexible massive MIMO architecture. Since GreenMO's virtual RF chains are created on the fly digitally, it can tune the number of these virtual chains according to the user load, hence always flexibly consume user-proportionate power. Thus, GreenMO paves the way for green and flexible massive MIMO. We prototype GreenMO on a PCB with eight antennas and evaluate it with a WARPv3 SDR platform in an office environment. The results demonstrate that GreenMO is 3x more power-efficient than traditional Massive MIMO and 4x more spectrum-efficient than traditional OFDMA systems, while multiplexing 4 users, and can save upto 40% power in modern 5G NR base stations.
VIMA: General Robot Manipulation with Multimodal Prompts
Oct 06, 2022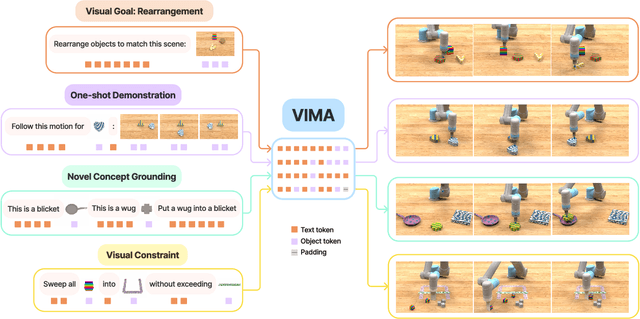
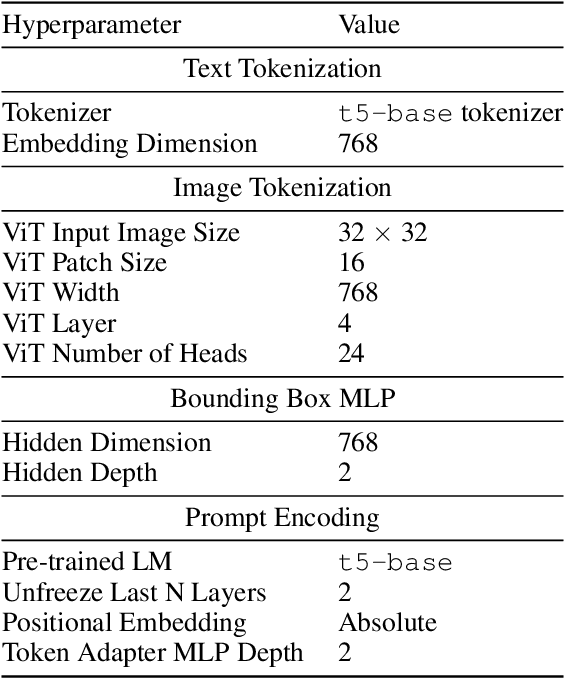
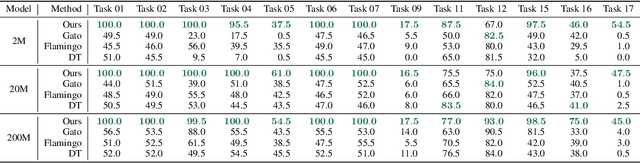
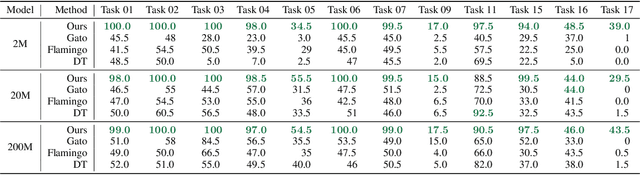
Prompt-based learning has emerged as a successful paradigm in natural language processing, where a single general-purpose language model can be instructed to perform any task specified by input prompts. Yet task specification in robotics comes in various forms, such as imitating one-shot demonstrations, following language instructions, and reaching visual goals. They are often considered different tasks and tackled by specialized models. This work shows that we can express a wide spectrum of robot manipulation tasks with multimodal prompts, interleaving textual and visual tokens. We design a transformer-based generalist robot agent, VIMA, that processes these prompts and outputs motor actions autoregressively. To train and evaluate VIMA, we develop a new simulation benchmark with thousands of procedurally-generated tabletop tasks with multimodal prompts, 600K+ expert trajectories for imitation learning, and four levels of evaluation protocol for systematic generalization. VIMA achieves strong scalability in both model capacity and data size. It outperforms prior SOTA methods in the hardest zero-shot generalization setting by up to $2.9\times$ task success rate given the same training data. With $10\times$ less training data, VIMA still performs $2.7\times$ better than the top competing approach. We open-source all code, pretrained models, dataset, and simulation benchmark at https://vimalabs.github.io
WiForceSticker: Batteryless, Thin Sticker-like Flexible Force Sensor
Sep 19, 2022
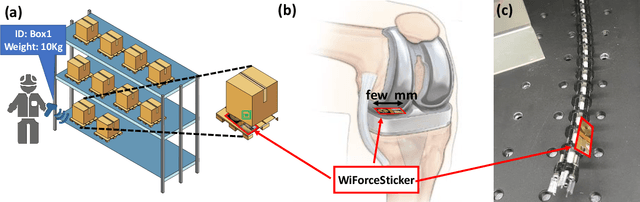
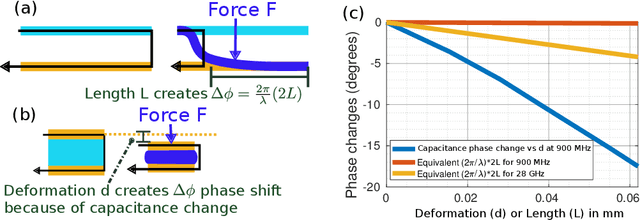

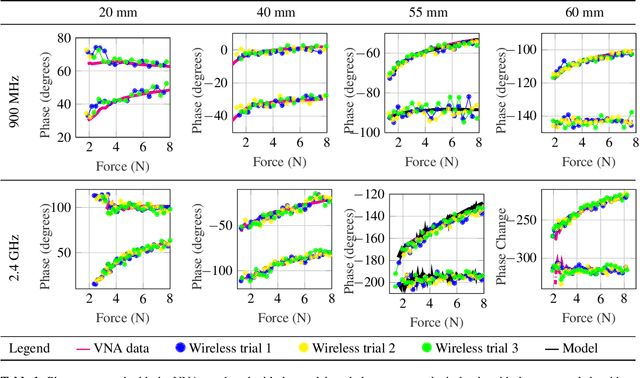
Any two objects in contact with each other exert a force that could be simply due to gravity or mechanical contact, such as a robotic arm gripping an object or even the contact between two bones at our knee joints. The ability to naturally measure and monitor these contact forces allows a plethora of applications from warehouse management (detect faulty packages based on weights) to robotics (making a robotic arms' grip as sensitive as human skin) and healthcare (knee-implants). It is challenging to design a ubiquitous force sensor that can be used naturally for all these applications. First, the sensor should be small enough to fit in narrow spaces. Next, we don't want to lay cumbersome cables to read the force values from the sensors. Finally, we need to have a battery-free design to meet the in-vivo applications. We develop WiForceSticker, a wireless, battery-free, sticker-like force sensor that can be ubiquitously deployed on any surface, such as all warehouse packages, robotic arms, and knee joints. WiForceSticker first designs a tiny $4$~mm~$\times$~$2$~mm~$\times$~$0.4$~mm capacitative sensor design equipped with a $10$~mm~$\times$~$10$~mm antenna designed on a flexible PCB substrate. Secondly, it introduces a new mechanism to transduce the force information on ambient RF radiations that can be read by a remotely located reader wirelessly without requiring any battery or active components at the force sensor, by interfacing the sensors with COTS RFID systems. The sensor can detect forces in the range of $0$-$6$~N with sensing accuracy of $<0.5$~N across multiple testing environments and evaluated with over $10,000$ varying force level presses on the sensor. We also showcase two application case studies with our designed sensors, weighing warehouse packages and sensing forces applied by bone joints.
MaskViT: Masked Visual Pre-Training for Video Prediction
Jun 23, 2022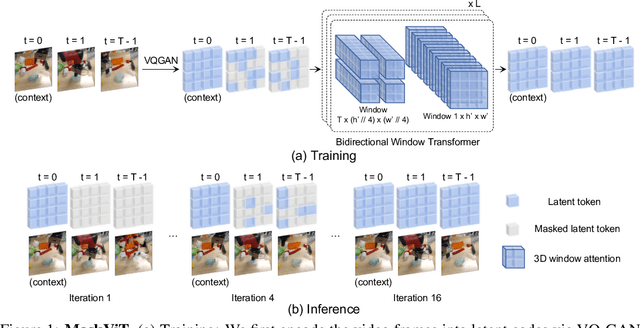
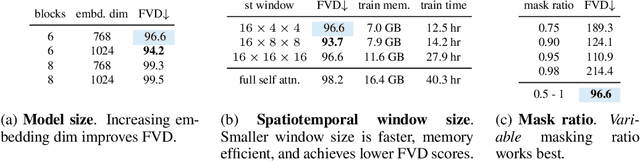

The ability to predict future visual observations conditioned on past observations and motor commands can enable embodied agents to plan solutions to a variety of tasks in complex environments. This work shows that we can create good video prediction models by pre-training transformers via masked visual modeling. Our approach, named MaskViT, is based on two simple design decisions. First, for memory and training efficiency, we use two types of window attention: spatial and spatiotemporal. Second, during training, we mask a variable percentage of tokens instead of a fixed mask ratio. For inference, MaskViT generates all tokens via iterative refinement where we incrementally decrease the masking ratio following a mask scheduling function. On several datasets we demonstrate that MaskViT outperforms prior works in video prediction, is parameter efficient, and can generate high-resolution videos (256x256). Further, we demonstrate the benefits of inference speedup (up to 512x) due to iterative decoding by using MaskViT for planning on a real robot. Our work suggests that we can endow embodied agents with powerful predictive models by leveraging the general framework of masked visual modeling with minimal domain knowledge.
MetaMorph: Learning Universal Controllers with Transformers
Mar 22, 2022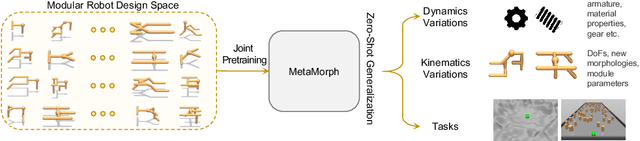
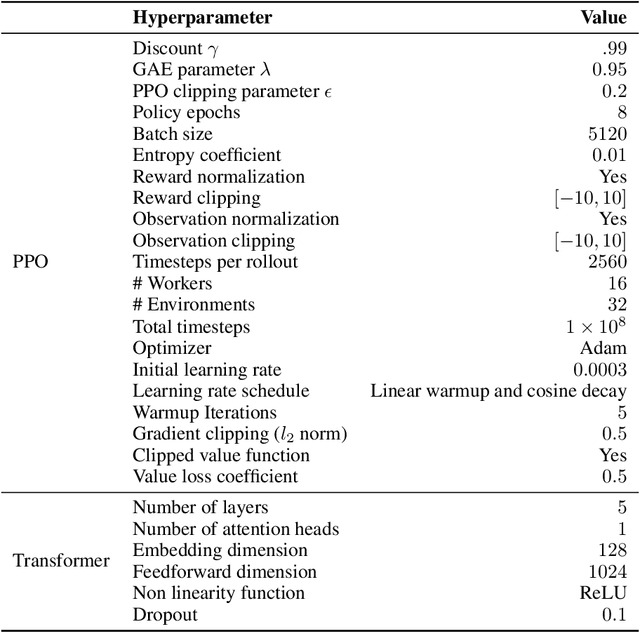
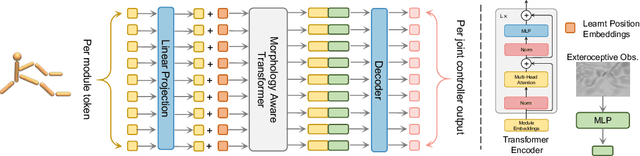
Multiple domains like vision, natural language, and audio are witnessing tremendous progress by leveraging Transformers for large scale pre-training followed by task specific fine tuning. In contrast, in robotics we primarily train a single robot for a single task. However, modular robot systems now allow for the flexible combination of general-purpose building blocks into task optimized morphologies. However, given the exponentially large number of possible robot morphologies, training a controller for each new design is impractical. In this work, we propose MetaMorph, a Transformer based approach to learn a universal controller over a modular robot design space. MetaMorph is based on the insight that robot morphology is just another modality on which we can condition the output of a Transformer. Through extensive experiments we demonstrate that large scale pre-training on a variety of robot morphologies results in policies with combinatorial generalization capabilities, including zero shot generalization to unseen robot morphologies. We further demonstrate that our pre-trained policy can be used for sample-efficient transfer to completely new robot morphologies and tasks.
Embodied Intelligence via Learning and Evolution
Feb 03, 2021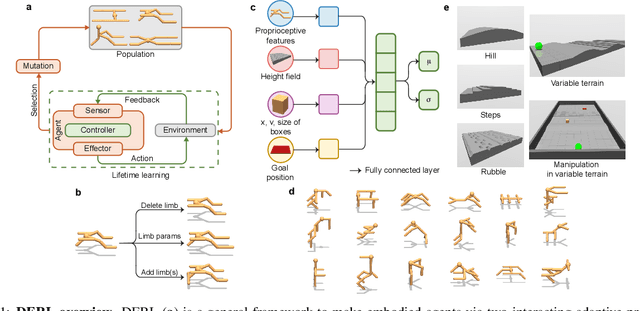

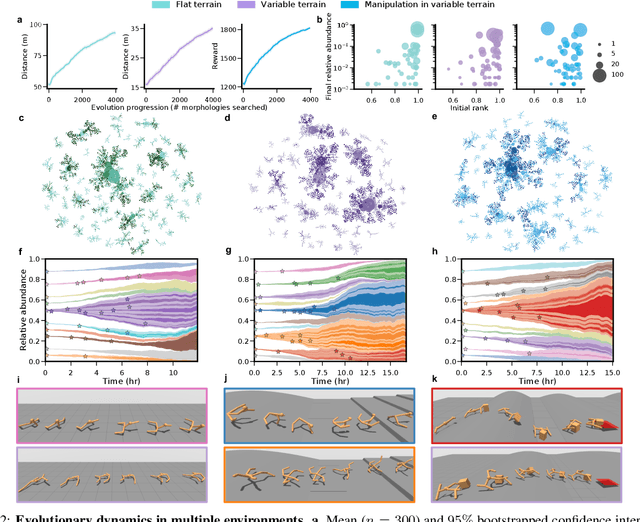
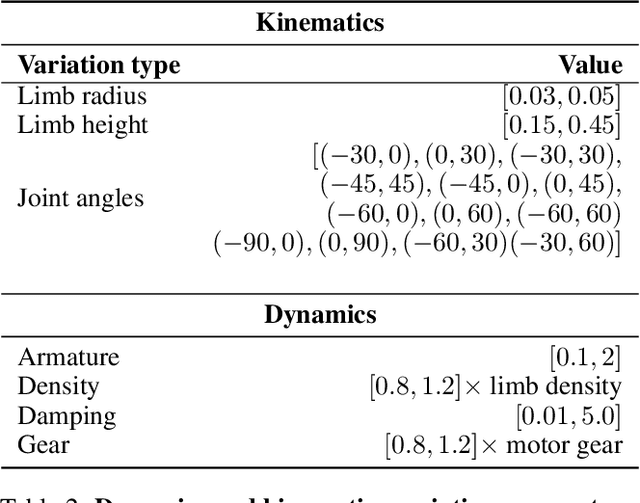
The intertwined processes of learning and evolution in complex environmental niches have resulted in a remarkable diversity of morphological forms. Moreover, many aspects of animal intelligence are deeply embodied in these evolved morphologies. However, the principles governing relations between environmental complexity, evolved morphology, and the learnability of intelligent control, remain elusive, partially due to the substantial challenge of performing large-scale in silico experiments on evolution and learning. We introduce Deep Evolutionary Reinforcement Learning (DERL): a novel computational framework which can evolve diverse agent morphologies to learn challenging locomotion and manipulation tasks in complex environments using only low level egocentric sensory information. Leveraging DERL we demonstrate several relations between environmental complexity, morphological intelligence and the learnability of control. First, environmental complexity fosters the evolution of morphological intelligence as quantified by the ability of a morphology to facilitate the learning of novel tasks. Second, evolution rapidly selects morphologies that learn faster, thereby enabling behaviors learned late in the lifetime of early ancestors to be expressed early in the lifetime of their descendants. In agents that learn and evolve in complex environments, this result constitutes the first demonstration of a long-conjectured morphological Baldwin effect. Third, our experiments suggest a mechanistic basis for both the Baldwin effect and the emergence of morphological intelligence through the evolution of morphologies that are more physically stable and energy efficient, and can therefore facilitate learning and control.
Wi-Chlorian: Wireless sensing and localization of contact forces on a space continuum
Dec 31, 2020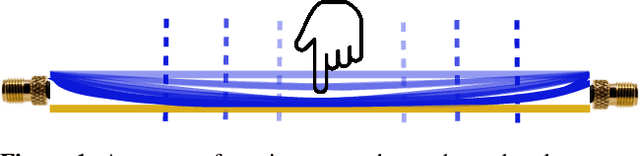
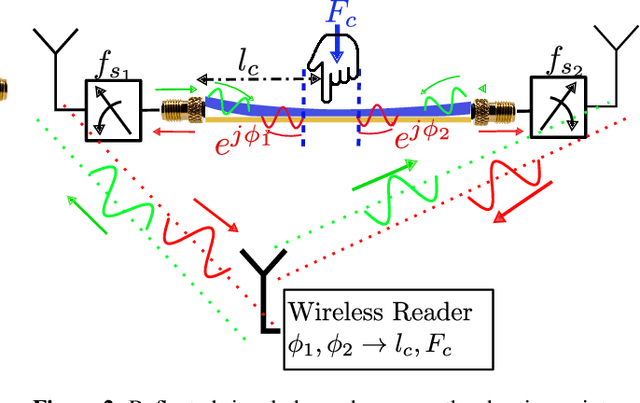
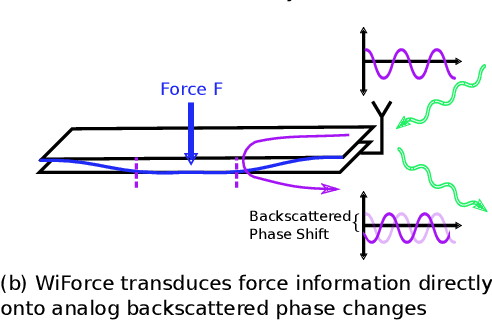
Contact force is a natural way for humans to interact with the physical world around us. However, most of our interactions with the digital world are largely based on a simple binary sense of touch (contact or no contact). Similarly, when interacting with robots to perform complex tasks, such as surgery, we need to acquire the rich force information and contact location, to aid in the task. To address these issues, we present the design and fabrication of Wi-Chlorian, which is a 'wireless' sensors that can be attached to an object or robot, like a sticker. Wi-Chlorian's sensor transduces force magnitude and location into phase changes of an incident RF signal, which is reflected back to enable measurement of force and contact location. Wi-Chlorian's sensor is designed to support wide-band frequencies all the way up to 3GHz.We evaluate the force sensing wirelessly in different environments, including in-body like, and achieve force ac-curacy of 0.3N and contact location accuracy of 0.6mm.