 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
SE Territory: Monaural Speech Enhancement Meets the Fixed Virtual Perceptual Space Mapping
Nov 03, 2023
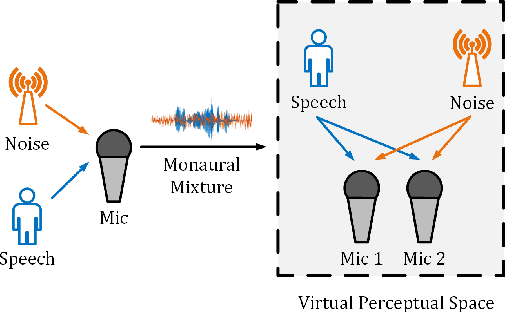
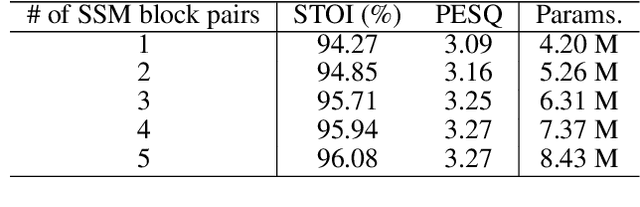
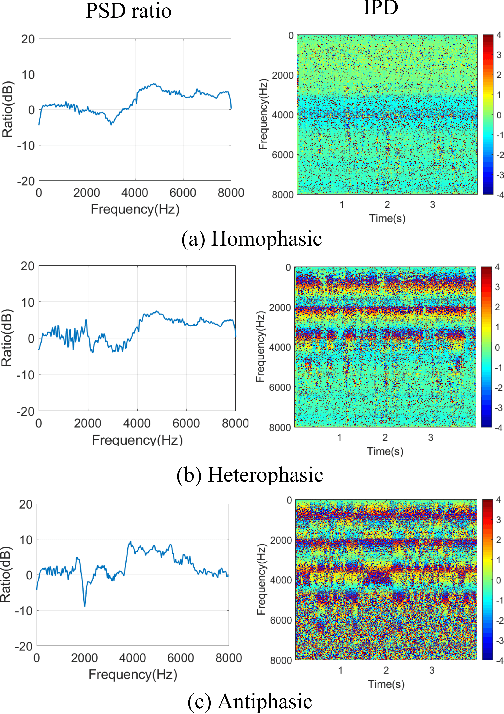

Monaural speech enhancement has achieved remarkable progress recently. However, its performance has been constrained by the limited spatial cues available at a single microphone. To overcome this limitation, we introduce a strategy to map monaural speech into a fixed simulation space for better differentiation between target speech and noise. Concretely, we propose SE-TerrNet, a novel monaural speech enhancement model featuring a virtual binaural speech mapping network via a two-stage multi-task learning framework. In the first stage, monaural noisy input is projected into a virtual space using supervised speech mapping blocks, creating binaural representations. These blocks synthesize binaural noisy speech from monaural input via an ideal binaural room impulse response. The synthesized output assigns speech and noise sources to fixed directions within the perceptual space. In the second stage, the obtained binaural features from the first stage are aggregated. This aggregation aims to decrease pattern discrepancies between the mapped binaural and original monaural features, achieved by implementing an intermediate fusion module. Furthermore, this stage incorporates the utilization of cross-attention to capture the injected virtual spatial information to improve the extraction of the target speech. Empirical studies highlight the effectiveness of virtual spatial cues in enhancing monaural speech enhancement. As a result, the proposed SE-TerrNet significantly surpasses the recent monaural speech enhancement methods in terms of both speech quality and intelligibility.
Joint Training or Not: An Exploration of Pre-trained Speech Models in Audio-Visual Speaker Diarization
Dec 07, 2023The scarcity of labeled audio-visual datasets is a constraint for training superior audio-visual speaker diarization systems. To improve the performance of audio-visual speaker diarization, we leverage pre-trained supervised and self-supervised speech models for audio-visual speaker diarization. Specifically, we adopt supervised~(ResNet and ECAPA-TDNN) and self-supervised pre-trained models~(WavLM and HuBERT) as the speaker and audio embedding extractors in an end-to-end audio-visual speaker diarization~(AVSD) system. Then we explore the effectiveness of different frameworks, including Transformer, Conformer, and cross-attention mechanism, in the audio-visual decoder. To mitigate the degradation of performance caused by separate training, we jointly train the audio encoder, speaker encoder, and audio-visual decoder in the AVSD system. Experiments on the MISP dataset demonstrate that the proposed method achieves superior performance and obtained third place in MISP Challenge 2022.
From Audio to Photoreal Embodiment: Synthesizing Humans in Conversations
Jan 03, 2024We present a framework for generating full-bodied photorealistic avatars that gesture according to the conversational dynamics of a dyadic interaction. Given speech audio, we output multiple possibilities of gestural motion for an individual, including face, body, and hands. The key behind our method is in combining the benefits of sample diversity from vector quantization with the high-frequency details obtained through diffusion to generate more dynamic, expressive motion. We visualize the generated motion using highly photorealistic avatars that can express crucial nuances in gestures (e.g. sneers and smirks). To facilitate this line of research, we introduce a first-of-its-kind multi-view conversational dataset that allows for photorealistic reconstruction. Experiments show our model generates appropriate and diverse gestures, outperforming both diffusion- and VQ-only methods. Furthermore, our perceptual evaluation highlights the importance of photorealism (vs. meshes) in accurately assessing subtle motion details in conversational gestures. Code and dataset available online.
Grounding-Prompter: Prompting LLM with Multimodal Information for Temporal Sentence Grounding in Long Videos
Dec 28, 2023Temporal Sentence Grounding (TSG), which aims to localize moments from videos based on the given natural language queries, has attracted widespread attention. Existing works are mainly designed for short videos, failing to handle TSG in long videos, which poses two challenges: i) complicated contexts in long videos require temporal reasoning over longer moment sequences, and ii) multiple modalities including textual speech with rich information require special designs for content understanding in long videos. To tackle these challenges, in this work we propose a Grounding-Prompter method, which is capable of conducting TSG in long videos through prompting LLM with multimodal information. In detail, we first transform the TSG task and its multimodal inputs including speech and visual, into compressed task textualization. Furthermore, to enhance temporal reasoning under complicated contexts, a Boundary-Perceptive Prompting strategy is proposed, which contains three folds: i) we design a novel Multiscale Denoising Chain-of-Thought (CoT) to combine global and local semantics with noise filtering step by step, ii) we set up validity principles capable of constraining LLM to generate reasonable predictions following specific formats, and iii) we introduce one-shot In-Context-Learning (ICL) to boost reasoning through imitation, enhancing LLM in TSG task understanding. Experiments demonstrate the state-of-the-art performance of our Grounding-Prompter method, revealing the benefits of prompting LLM with multimodal information for TSG in long videos.
A comparative analysis between Conformer-Transducer, Whisper, and wav2vec2 for improving the child speech recognition
Nov 07, 2023Automatic Speech Recognition (ASR) systems have progressed significantly in their performance on adult speech data; however, transcribing child speech remains challenging due to the acoustic differences in the characteristics of child and adult voices. This work aims to explore the potential of adapting state-of-the-art Conformer-transducer models to child speech to improve child speech recognition performance. Furthermore, the results are compared with those of self-supervised wav2vec2 models and semi-supervised multi-domain Whisper models that were previously finetuned on the same data. We demonstrate that finetuning Conformer-transducer models on child speech yields significant improvements in ASR performance on child speech, compared to the non-finetuned models. We also show Whisper and wav2vec2 adaptation on different child speech datasets. Our detailed comparative analysis shows that wav2vec2 provides the most consistent performance improvements among the three methods studied.
Whisper in Focus: Enhancing Stuttered Speech Classification with Encoder Layer Optimization
Nov 09, 2023In recent years, advancements in the field of speech processing have led to cutting-edge deep learning algorithms with immense potential for real-world applications. The automated identification of stuttered speech is one of such applications that the researchers are addressing by employing deep learning techniques. Recently, researchers have utilized Wav2vec2.0, a speech recognition model to classify disfluency types in stuttered speech. Although Wav2vec2.0 has shown commendable results, its ability to generalize across all disfluency types is limited. In addition, since its base model uses 12 encoder layers, it is considered a resource-intensive model. Our study unravels the capabilities of Whisper for the classification of disfluency types in stuttered speech. We have made notable contributions in three pivotal areas: enhancing the quality of SEP28-k benchmark dataset, exploration of Whisper for classification, and introducing an efficient encoder layer freezing strategy. The optimized Whisper model has achieved the average F1-score of 0.81, which proffers its abilities. This study also unwinds the significance of deeper encoder layers in the identification of disfluency types, as the results demonstrate their greater contribution compared to initial layers. This research represents substantial contributions, shifting the emphasis towards an efficient solution, thereby thriving towards prospective innovation.
GOAT-Bench: Safety Insights to Large Multimodal Models through Meme-Based Social Abuse
Jan 07, 2024The exponential growth of social media has profoundly transformed how information is created, disseminated, and absorbed, exceeding any precedent in the digital age. Regrettably, this explosion has also spawned a significant increase in the online abuse of memes. Evaluating the negative impact of memes is notably challenging, owing to their often subtle and implicit meanings, which are not directly conveyed through the overt text and imagery. In light of this, large multimodal models (LMMs) have emerged as a focal point of interest due to their remarkable capabilities in handling diverse multimodal tasks. In response to this development, our paper aims to thoroughly examine the capacity of various LMMs (e.g. GPT-4V) to discern and respond to the nuanced aspects of social abuse manifested in memes. We introduce the comprehensive meme benchmark, GOAT-Bench, comprising over 6K varied memes encapsulating themes such as implicit hate speech, sexism, and cyberbullying, etc. Utilizing GOAT-Bench, we delve into the ability of LMMs to accurately assess hatefulness, misogyny, offensiveness, sarcasm, and harmful content. Our extensive experiments across a range of LMMs reveal that current models still exhibit a deficiency in safety awareness, showing insensitivity to various forms of implicit abuse. We posit that this shortfall represents a critical impediment to the realization of safe artificial intelligence. The GOAT-Bench and accompanying resources are publicly accessible at https://goatlmm.github.io/, contributing to ongoing research in this vital field.
Selective HuBERT: Self-Supervised Pre-Training for Target Speaker in Clean and Mixture Speech
Nov 08, 2023Self-supervised pre-trained speech models were shown effective for various downstream speech processing tasks. Since they are mainly pre-trained to map input speech to pseudo-labels, the resulting representations are only effective for the type of pre-train data used, either clean or mixture speech. With the idea of selective auditory attention, we propose a novel pre-training solution called Selective-HuBERT, or SHuBERT, which learns the selective extraction of target speech representations from either clean or mixture speech. Specifically, SHuBERT is trained to predict pseudo labels of a target speaker, conditioned on an enrolled speech from the target speaker. By doing so, SHuBERT is expected to selectively attend to the target speaker in a complex acoustic environment, thus benefiting various downstream tasks. We further introduce a dual-path training strategy and use the cross-correlation constraint between the two branches to encourage the model to generate noise-invariant representation. Experiments on SUPERB benchmark and LibriMix dataset demonstrate the universality and noise-robustness of SHuBERT. Furthermore, we find that our high-quality representation can be easily integrated with conventional supervised learning methods to achieve significant performance, even under extremely low-resource labeled data.
Nonlinear functional regression by functional deep neural network with kernel embedding
Jan 05, 2024With the rapid development of deep learning in various fields of science and technology, such as speech recognition, image classification, and natural language processing, recently it is also widely applied in the functional data analysis (FDA) with some empirical success. However, due to the infinite dimensional input, we need a powerful dimension reduction method for functional learning tasks, especially for the nonlinear functional regression. In this paper, based on the idea of smooth kernel integral transformation, we propose a functional deep neural network with an efficient and fully data-dependent dimension reduction method. The architecture of our functional net consists of a kernel embedding step: an integral transformation with a data-dependent smooth kernel; a projection step: a dimension reduction by projection with eigenfunction basis based on the embedding kernel; and finally an expressive deep ReLU neural network for the prediction. The utilization of smooth kernel embedding enables our functional net to be discretization invariant, efficient, and robust to noisy observations, capable of utilizing information in both input functions and responses data, and have a low requirement on the number of discrete points for an unimpaired generalization performance. We conduct theoretical analysis including approximation error and generalization error analysis, and numerical simulations to verify these advantages of our functional net.
Fine-tuning convergence model in Bengali speech recognition
Nov 07, 2023Research on speech recognition has attracted considerable interest due to the difficult task of segmenting uninterrupted speech. Among various languages, Bengali features distinct rhythmic patterns and tones, making it particularly difficult to recognize and lacking an efficient commercial recognition method. In order to improve the automatic speech recognition model for Bengali, our team has chosen to utilize the wave2vec 2.0 pre-trained model, which has undergone convergence for fine-tuning. Regarding Word Error Rate (WER), the learning rate and dropout parameters were fine-tuned, and after the model training was stable, attempts were made to enlarge the training set ratio, which improved the model's performance. Consequently, there was a notable enhancement in the WER from 0.508 to 0.437 on the test set of the publicly listed official dataset. Afterwards, the training and validation sets were merged, creating a comprehensive dataset that was used as the training set, achieving a remarkable WER of 0.436.