 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
Towards Selection of Text-to-speech Data to Augment ASR Training
May 30, 2023

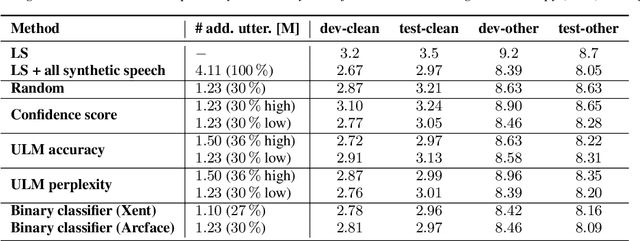
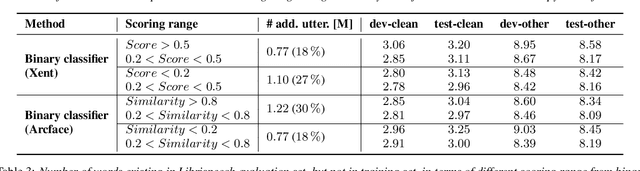

This paper presents a method for selecting appropriate synthetic speech samples from a given large text-to-speech (TTS) dataset as supplementary training data for an automatic speech recognition (ASR) model. We trained a neural network, which can be optimised using cross-entropy loss or Arcface loss, to measure the similarity of a synthetic data to real speech. We found that incorporating synthetic samples with considerable dissimilarity to real speech, owing in part to lexical differences, into ASR training is crucial for boosting recognition performance. Experimental results on Librispeech test sets indicate that, in order to maintain the same speech recognition accuracy as when using all TTS data, our proposed solution can reduce the size of the TTS data down below its $30\,\%$, which is superior to several baseline methods.
DeepFilterNet: Perceptually Motivated Real-Time Speech Enhancement
May 14, 2023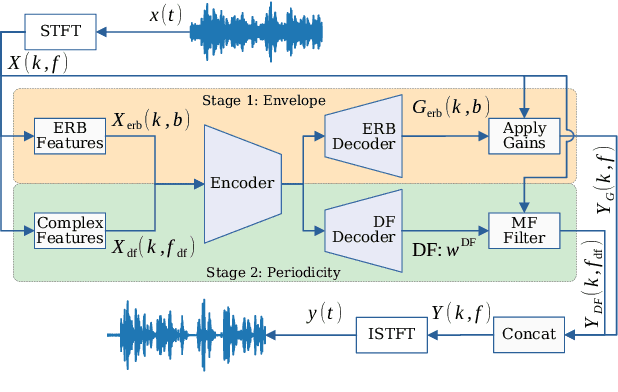
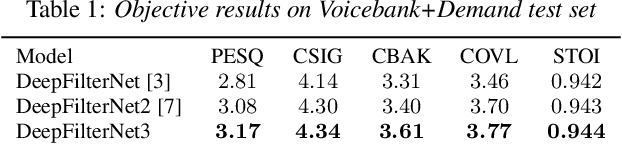
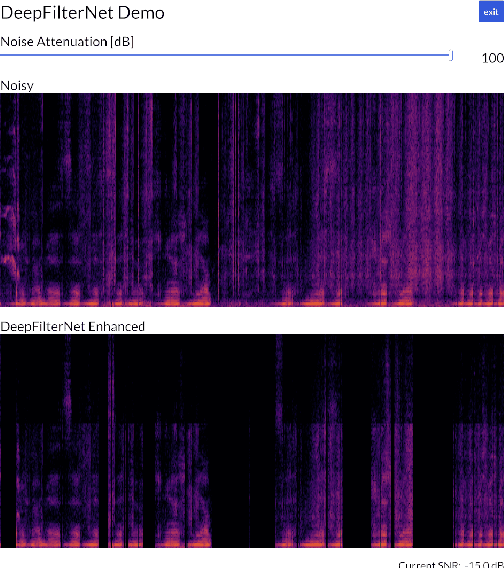
Multi-frame algorithms for single-channel speech enhancement are able to take advantage from short-time correlations within the speech signal. Deep Filtering (DF) was proposed to directly estimate a complex filter in frequency domain to take advantage of these correlations. In this work, we present a real-time speech enhancement demo using DeepFilterNet. DeepFilterNet's efficiency is enabled by exploiting domain knowledge of speech production and psychoacoustic perception. Our model is able to match state-of-the-art speech enhancement benchmarks while achieving a real-time-factor of 0.19 on a single threaded notebook CPU. The framework as well as pretrained weights have been published under an open source license.
Dynamic ASR Pathways: An Adaptive Masking Approach Towards Efficient Pruning of A Multilingual ASR Model
Sep 22, 2023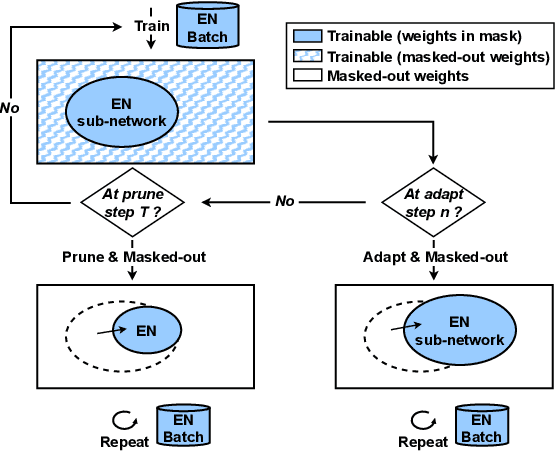
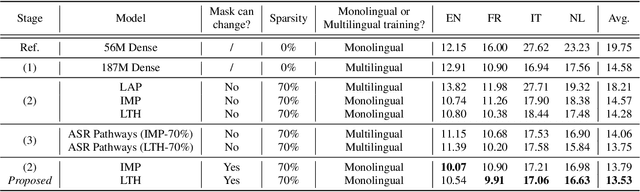
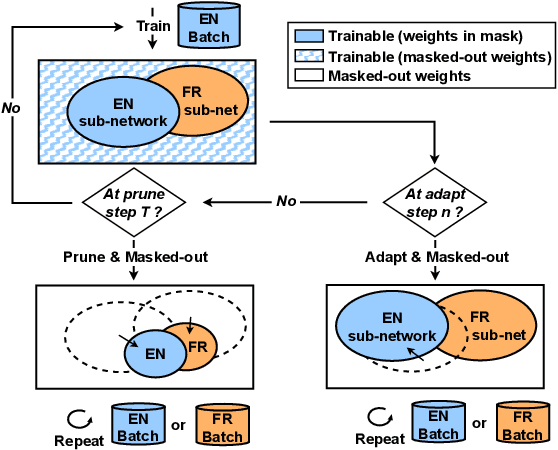
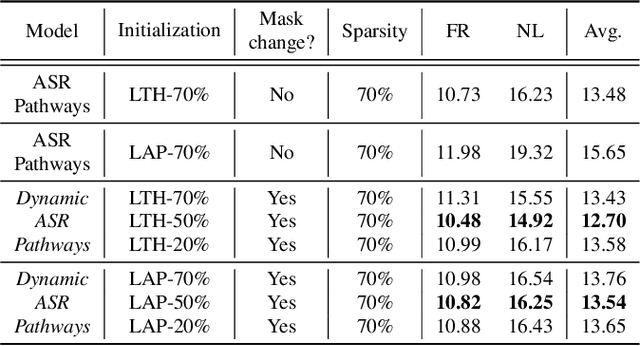
Neural network pruning offers an effective method for compressing a multilingual automatic speech recognition (ASR) model with minimal performance loss. However, it entails several rounds of pruning and re-training needed to be run for each language. In this work, we propose the use of an adaptive masking approach in two scenarios for pruning a multilingual ASR model efficiently, each resulting in sparse monolingual models or a sparse multilingual model (named as Dynamic ASR Pathways). Our approach dynamically adapts the sub-network, avoiding premature decisions about a fixed sub-network structure. We show that our approach outperforms existing pruning methods when targeting sparse monolingual models. Further, we illustrate that Dynamic ASR Pathways jointly discovers and trains better sub-networks (pathways) of a single multilingual model by adapting from different sub-network initializations, thereby reducing the need for language-specific pruning.
ML-SUPERB: Multilingual Speech Universal PERformance Benchmark
May 18, 2023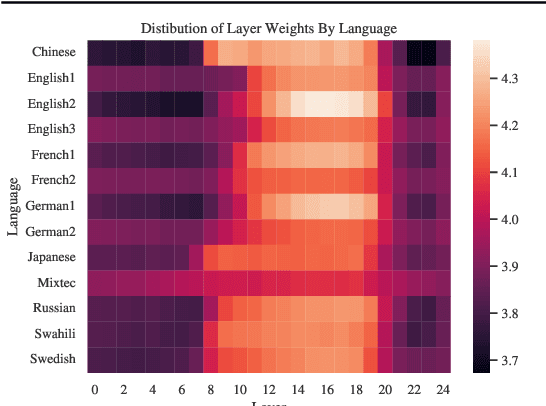
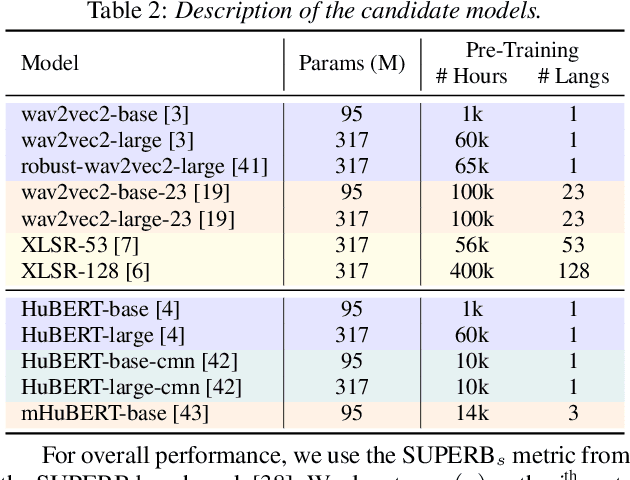
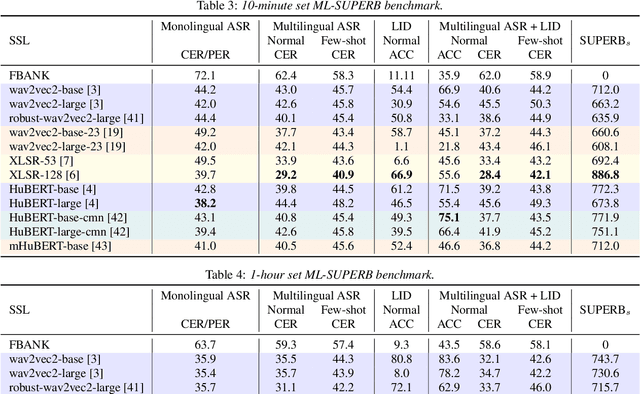
Speech processing Universal PERformance Benchmark (SUPERB) is a leaderboard to benchmark the performance of Self-Supervised Learning (SSL) models on various speech processing tasks. However, SUPERB largely considers English speech in its evaluation. This paper presents multilingual SUPERB (ML-SUPERB), covering 143 languages (ranging from high-resource to endangered), and considering both automatic speech recognition and language identification. Following the concept of SUPERB, ML-SUPERB utilizes frozen SSL features and employs a simple framework for multilingual tasks by learning a shallow downstream model. Similar to the SUPERB benchmark, we find speech SSL models can significantly improve performance compared to FBANK features. Furthermore, we find that multilingual models do not always perform better than their monolingual counterparts. We will release ML-SUPERB as a challenge with organized datasets and reproducible training scripts for future multilingual representation research.
ASR and Emotional Speech: A Word-Level Investigation of the Mutual Impact of Speech and Emotion Recognition
May 25, 2023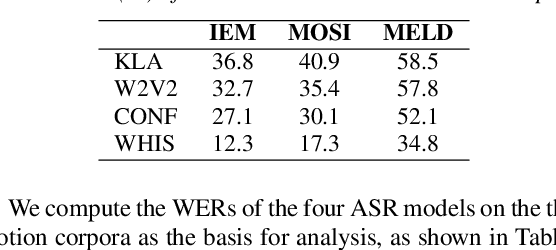
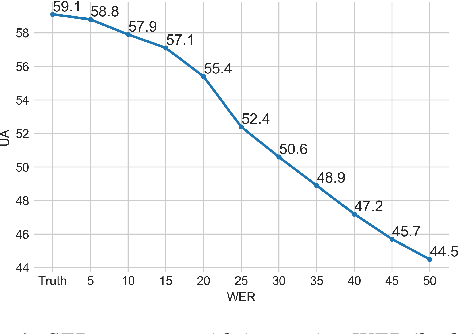
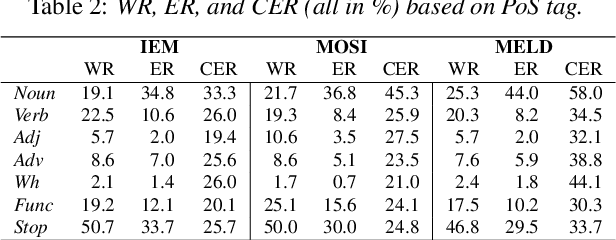
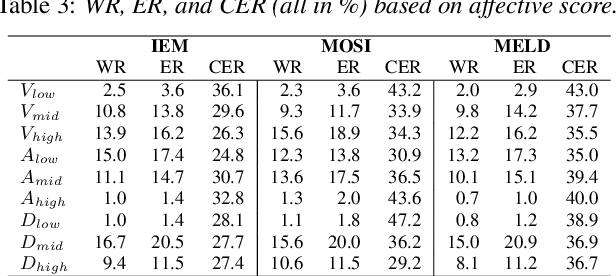
In Speech Emotion Recognition (SER), textual data is often used alongside audio signals to address their inherent variability. However, the reliance on human annotated text in most research hinders the development of practical SER systems. To overcome this challenge, we investigate how Automatic Speech Recognition (ASR) performs on emotional speech by analyzing the ASR performance on emotion corpora and examining the distribution of word errors and confidence scores in ASR transcripts to gain insight into how emotion affects ASR. We utilize four ASR systems, namely Kaldi ASR, wav2vec, Conformer, and Whisper, and three corpora: IEMOCAP, MOSI, and MELD to ensure generalizability. Additionally, we conduct text-based SER on ASR transcripts with increasing word error rates to investigate how ASR affects SER. The objective of this study is to uncover the relationship and mutual impact of ASR and SER, in order to facilitate ASR adaptation to emotional speech and the use of SER in real world.
Streaming Speech-to-Confusion Network Speech Recognition
Jun 02, 2023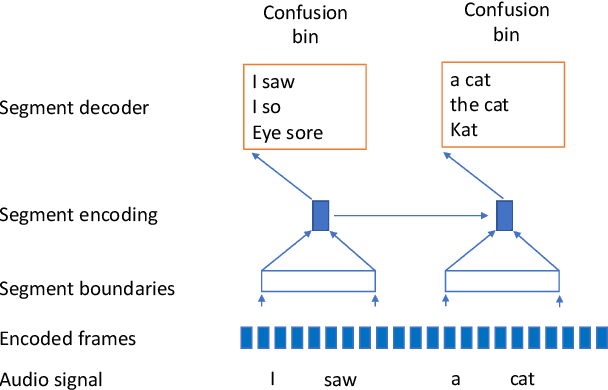
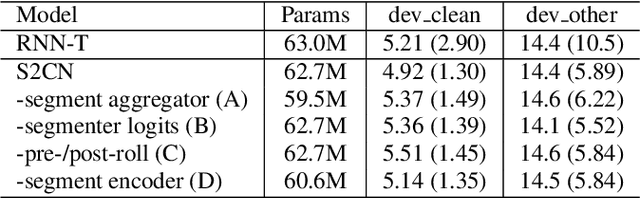
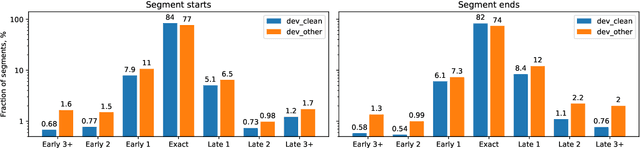
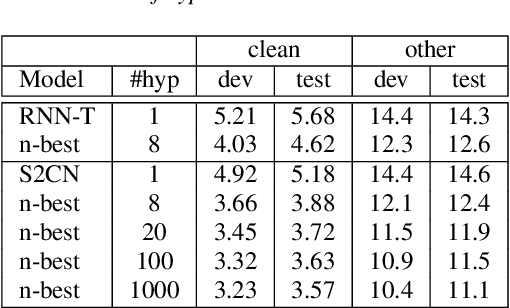
In interactive automatic speech recognition (ASR) systems, low-latency requirements limit the amount of search space that can be explored during decoding, particularly in end-to-end neural ASR. In this paper, we present a novel streaming ASR architecture that outputs a confusion network while maintaining limited latency, as needed for interactive applications. We show that 1-best results of our model are on par with a comparable RNN-T system, while the richer hypothesis set allows second-pass rescoring to achieve 10-20\% lower word error rate on the LibriSpeech task. We also show that our model outperforms a strong RNN-T baseline on a far-field voice assistant task.
SparseVSR: Lightweight and Noise Robust Visual Speech Recognition
Jul 10, 2023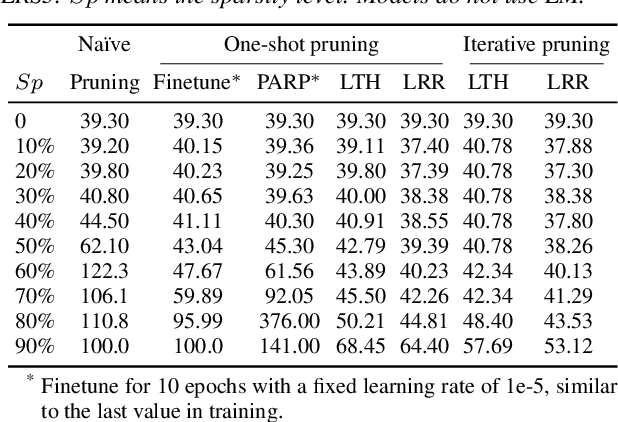
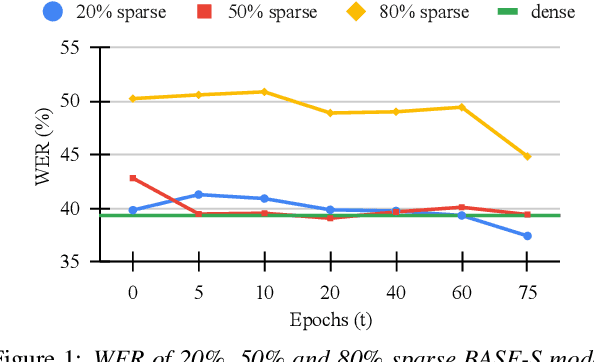
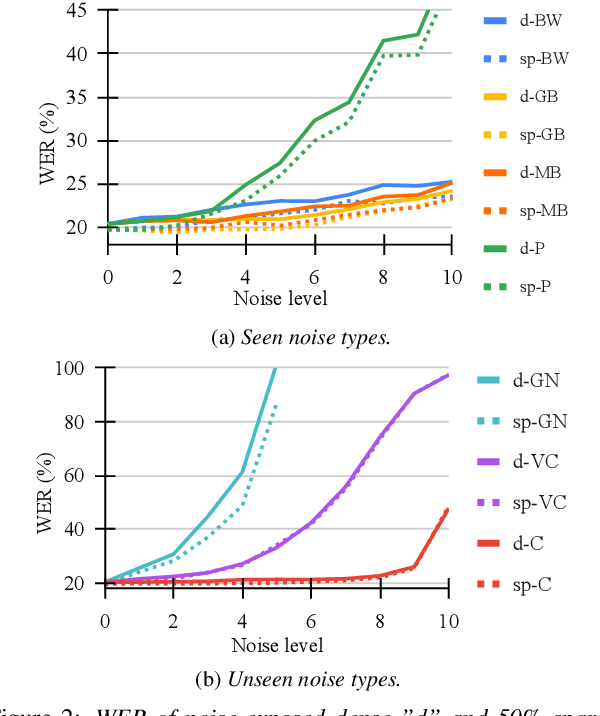
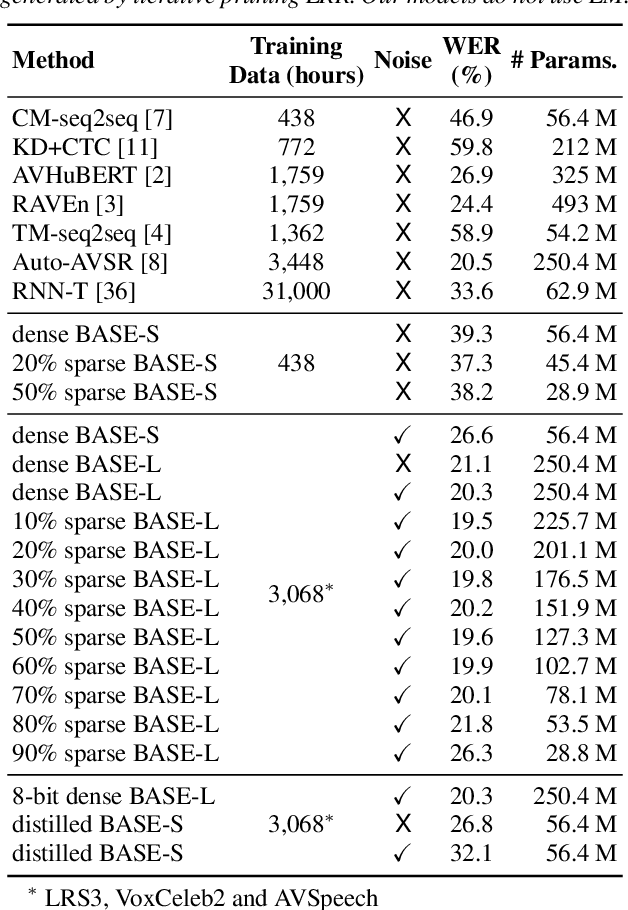
Recent advances in deep neural networks have achieved unprecedented success in visual speech recognition. However, there remains substantial disparity between current methods and their deployment in resource-constrained devices. In this work, we explore different magnitude-based pruning techniques to generate a lightweight model that achieves higher performance than its dense model equivalent, especially under the presence of visual noise. Our sparse models achieve state-of-the-art results at 10% sparsity on the LRS3 dataset and outperform the dense equivalent up to 70% sparsity. We evaluate our 50% sparse model on 7 different visual noise types and achieve an overall absolute improvement of more than 2% WER compared to the dense equivalent. Our results confirm that sparse networks are more resistant to noise than dense networks.
PEACE: Cross-Platform Hate Speech Detection- A Causality-guided Framework
Jun 15, 2023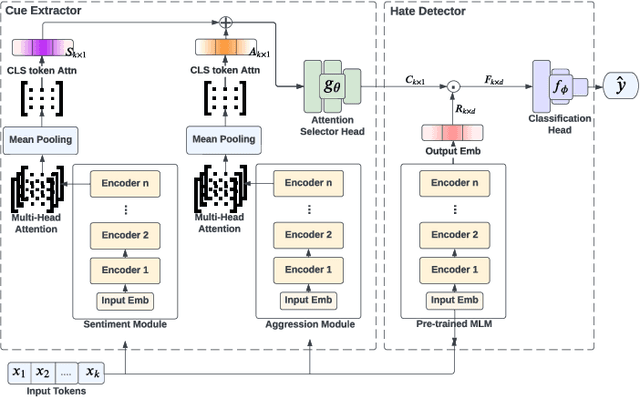
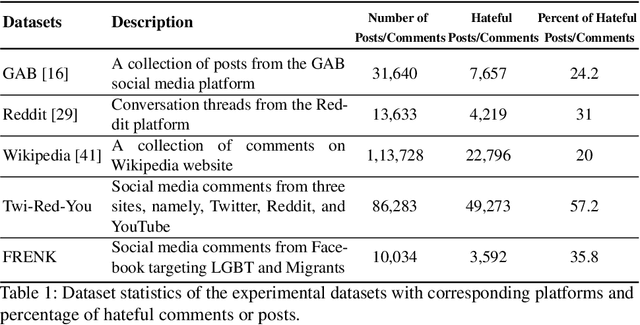
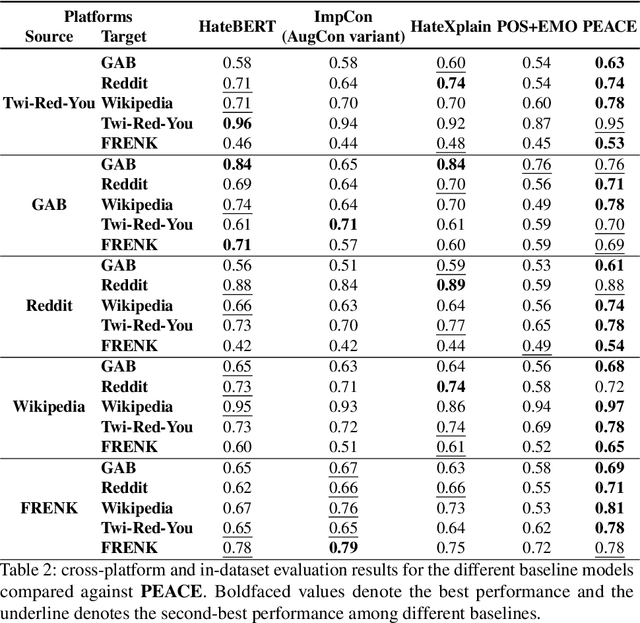
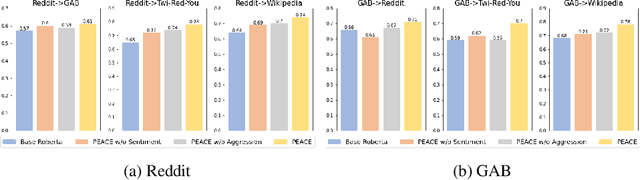
Hate speech detection refers to the task of detecting hateful content that aims at denigrating an individual or a group based on their religion, gender, sexual orientation, or other characteristics. Due to the different policies of the platforms, different groups of people express hate in different ways. Furthermore, due to the lack of labeled data in some platforms it becomes challenging to build hate speech detection models. To this end, we revisit if we can learn a generalizable hate speech detection model for the cross platform setting, where we train the model on the data from one (source) platform and generalize the model across multiple (target) platforms. Existing generalization models rely on linguistic cues or auxiliary information, making them biased towards certain tags or certain kinds of words (e.g., abusive words) on the source platform and thus not applicable to the target platforms. Inspired by social and psychological theories, we endeavor to explore if there exist inherent causal cues that can be leveraged to learn generalizable representations for detecting hate speech across these distribution shifts. To this end, we propose a causality-guided framework, PEACE, that identifies and leverages two intrinsic causal cues omnipresent in hateful content: the overall sentiment and the aggression in the text. We conduct extensive experiments across multiple platforms (representing the distribution shift) showing if causal cues can help cross-platform generalization.
UniCATS: A Unified Context-Aware Text-to-Speech Framework with Contextual VQ-Diffusion and Vocoding
Jun 13, 2023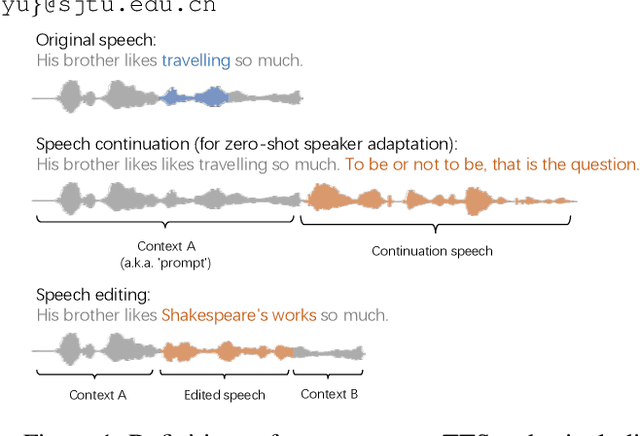

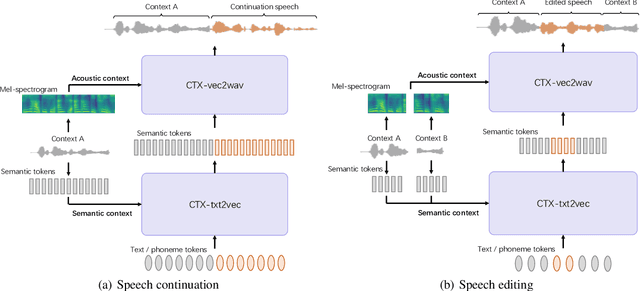

The utilization of discrete speech tokens, divided into semantic tokens and acoustic tokens, has been proven superior to traditional acoustic feature mel-spectrograms in terms of naturalness and robustness for text-to-speech (TTS) synthesis. Recent popular models, such as VALL-E and SPEAR-TTS, allow zero-shot speaker adaptation through auto-regressive (AR) continuation of acoustic tokens extracted from a short speech prompt. However, these AR models are restricted to generate speech only in a left-to-right direction, making them unsuitable for speech editing where both preceding and following contexts are provided. Furthermore, these models rely on acoustic tokens, which have audio quality limitations imposed by the performance of audio codec models. In this study, we propose a unified context-aware TTS framework called UniCATS, which is capable of both speech continuation and editing. UniCATS comprises two components, an acoustic model CTX-txt2vec and a vocoder CTX-vec2wav. CTX-txt2vec employs contextual VQ-diffusion to predict semantic tokens from the input text, enabling it to incorporate the semantic context and maintain seamless concatenation with the surrounding context. Following that, CTX-vec2wav utilizes contextual vocoding to convert these semantic tokens into waveforms, taking into consideration the acoustic context. Our experimental results demonstrate that CTX-vec2wav outperforms HifiGAN and AudioLM in terms of speech resynthesis from semantic tokens. Moreover, we show that UniCATS achieves state-of-the-art performance in both speech continuation and editing.
Enhancing Speech-to-Speech Translation with Multiple TTS Targets
Apr 10, 2023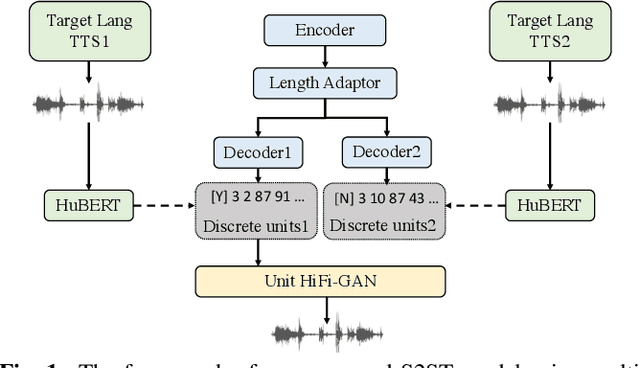
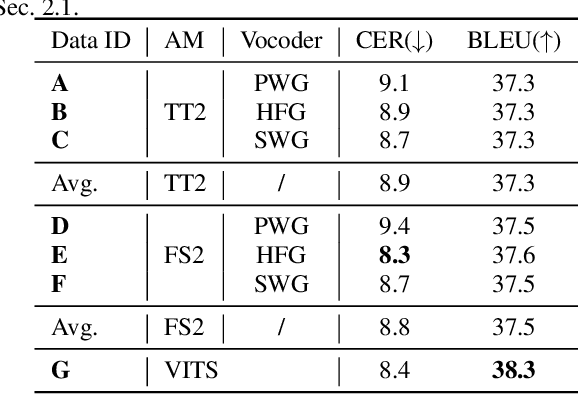
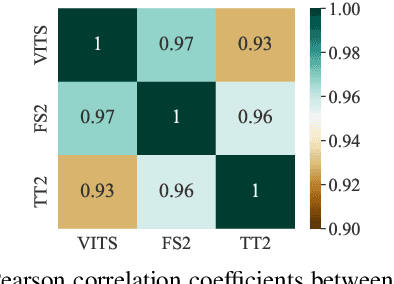
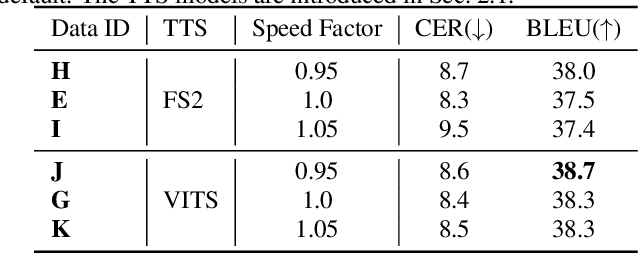
It has been known that direct speech-to-speech translation (S2ST) models usually suffer from the data scarcity issue because of the limited existing parallel materials for both source and target speech. Therefore to train a direct S2ST system, previous works usually utilize text-to-speech (TTS) systems to generate samples in the target language by augmenting the data from speech-to-text translation (S2TT). However, there is a limited investigation into how the synthesized target speech would affect the S2ST models. In this work, we analyze the effect of changing synthesized target speech for direct S2ST models. We find that simply combining the target speech from different TTS systems can potentially improve the S2ST performances. Following that, we also propose a multi-task framework that jointly optimizes the S2ST system with multiple targets from different TTS systems. Extensive experiments demonstrate that our proposed framework achieves consistent improvements (2.8 BLEU) over the baselines on the Fisher Spanish-English dataset.