 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUNet-Based Fusion and Exponential Moving Average Adaptation for Noise-Robust Speaker Recognition
Apr 28, 2026The joint training of speech enhancement and speaker embedding networks for speaker recognition is widely adopted under noisy acoustic environments. While effective, this paradigm often fails to leverage the generalization and robustness benefits inherent in large-scale speech enhancement pre-training. Moreover, maintaining the speaker information in the denoised speech is not an explicit objective of the speech enhancement process. To address these limitations, we proposed a scalable \textbf{U}Net-based \textbf{F}usion framework (UF-EMA) that considers the noisy and enhanced speech as a multi-channel input, thereby enabling the speaker encoder to exploit speaker information effectively. In addition, an \textbf{E}xponential \textbf{M}oving \textbf{A}verage strategy is applied to a speaker encoder pre-trained on clean speech to mitigate overfitting and facilitate a smooth transition from clean to noisy conditions. Experimental results on multiple noise-contaminated test sets showcase the superiority of the proposed approach.
The Voice Behind the Words: Quantifying Intersectional Bias in SpeechLLMs
Mar 15, 2026Speech Large Language Models (SpeechLLMs) process spoken input directly, retaining cues such as accent and perceived gender that were previously removed in cascaded pipelines. This introduces speaker identity dependent variation in responses. We present a large-scale intersectional evaluation of accent and gender bias in three SpeechLLMs using 2,880 controlled interactions across six English accents and two gender presentations, keeping linguistic content constant through voice cloning. Using pointwise LLM-judge ratings, pairwise comparisons, and Best-Worst Scaling with human validation, we detect consistent disparities. Eastern European-accented speech receives lower helpfulness scores, particularly for female-presenting voices. The bias is implicit: responses remain polite but differ in helpfulness. While LLM judges capture the directional trend of these biases, human evaluators exhibit significantly higher sensitivity, uncovering sharper intersectional disparities.
Rethinking Discrete Speech Representation Tokens for Accent Generation
Jan 27, 2026Discrete Speech Representation Tokens (DSRTs) have become a foundational component in speech generation. While prior work has extensively studied phonetic and speaker information in DSRTs, how accent information is encoded in DSRTs remains largely unexplored. In this paper, we present the first systematic investigation of accent information in DSRTs. We propose a unified evaluation framework that measures both accessibility of accent information via a novel Accent ABX task and recoverability via cross-accent Voice Conversion (VC) resynthesis. Using this framework, we analyse DSRTs derived from a variety of speech encoders. Our results reveal that accent information is substantially reduced when ASR supervision is used to fine-tune the encoder, but cannot be effectively disentangled from phonetic and speaker information through naive codebook size reduction. Based on these findings, we propose new content-only and content-accent DSRTs that significantly outperform existing designs in controllable accent generation. Our work highlights the importance of accent-aware evaluation and provides practical guidance for designing DSRTs for accent-controlled speech generation.
Learning Speech Representations with Variational Predictive Coding
Dec 31, 2025Despite being the best known objective for learning speech representations, the HuBERT objective has not been further developed and improved. We argue that it is the lack of an underlying principle that stalls the development, and, in this paper, we show that predictive coding under a variational view is the principle behind the HuBERT objective. Due to its generality, our formulation provides opportunities to improve parameterization and optimization, and we show two simple modifications that bring immediate improvements to the HuBERT objective. In addition, the predictive coding formulation has tight connections to various other objectives, such as APC, CPC, wav2vec, and BEST-RQ. Empirically, the improvement in pre-training brings significant improvements to four downstream tasks: phone classification, f0 tracking, speaker recognition, and automatic speech recognition, highlighting the importance of the predictive coding interpretation.
TTSDS2: Resources and Benchmark for Evaluating Human-Quality Text to Speech Systems
Jun 24, 2025
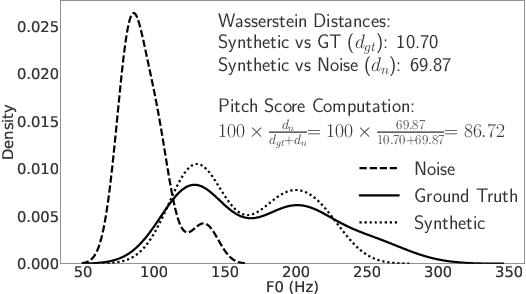
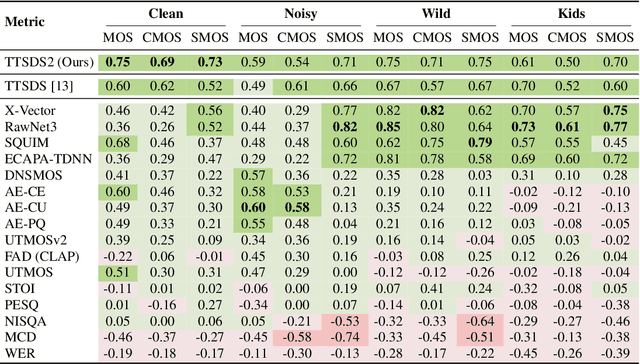
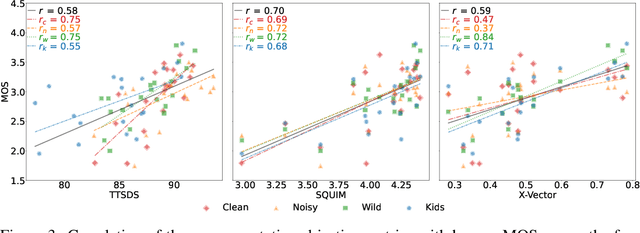
Evaluation of Text to Speech (TTS) systems is challenging and resource-intensive. Subjective metrics such as Mean Opinion Score (MOS) are not easily comparable between works. Objective metrics are frequently used, but rarely validated against subjective ones. Both kinds of metrics are challenged by recent TTS systems capable of producing synthetic speech indistinguishable from real speech. In this work, we introduce Text to Speech Distribution Score 2 (TTSDS2), a more robust and improved version of TTSDS. Across a range of domains and languages, it is the only one out of 16 compared metrics to correlate with a Spearman correlation above 0.50 for every domain and subjective score evaluated. We also release a range of resources for evaluating synthetic speech close to real speech: A dataset with over 11,000 subjective opinion score ratings; a pipeline for continually recreating a multilingual test dataset to avoid data leakage; and a continually updated benchmark for TTS in 14 languages.
A Practitioner's Guide to Building ASR Models for Low-Resource Languages: A Case Study on Scottish Gaelic
Jun 05, 2025An effective approach to the development of ASR systems for low-resource languages is to fine-tune an existing multilingual end-to-end model. When the original model has been trained on large quantities of data from many languages, fine-tuning can be effective with limited training data, even when the language in question was not present in the original training data. The fine-tuning approach has been encouraged by the availability of public-domain E2E models and is widely believed to lead to state-of-the-art results. This paper, however, challenges that belief. We show that an approach combining hybrid HMMs with self-supervised models can yield substantially better performance with limited training data. This combination allows better utilisation of all available speech and text data through continued self-supervised pre-training and semi-supervised training. We benchmark our approach on Scottish Gaelic, achieving WER reductions of 32% relative over our best fine-tuned Whisper model.
Language Bias in Self-Supervised Learning For Automatic Speech Recognition
Jan 31, 2025



Self-supervised learning (SSL) is used in deep learning to train on large datasets without the need for expensive labelling of the data. Recently, large Automatic Speech Recognition (ASR) models such as XLS-R have utilised SSL to train on over one hundred different languages simultaneously. However, deeper investigation shows that the bulk of the training data for XLS-R comes from a small number of languages. Biases learned through SSL have been shown to exist in multiple domains, but language bias in multilingual SSL ASR has not been thoroughly examined. In this paper, we utilise the Lottery Ticket Hypothesis (LTH) to identify language-specific subnetworks within XLS-R and test the performance of these subnetworks on a variety of different languages. We are able to show that when fine-tuning, XLS-R bypasses traditional linguistic knowledge and builds only on weights learned from the languages with the largest data contribution to the pretraining data.
Beyond Oversmoothing: Evaluating DDPM and MSE for Scalable Speech Synthesis in ASR
Oct 16, 2024


Synthetically generated speech has rapidly approached human levels of naturalness. However, the paradox remains that ASR systems, when trained on TTS output that is judged as natural by humans, continue to perform badly on real speech. In this work, we explore whether this phenomenon is due to the oversmoothing behaviour of models commonly used in TTS, with a particular focus on the behaviour of TTS-for-ASR as the amount of TTS training data is scaled up. We systematically compare Denoising Diffusion Probabilistic Models (DDPM) to Mean Squared Error (MSE) based models for TTS, when used for ASR model training. We test the scalability of the two approaches, varying both the number hours, and the number of different speakers. We find that for a given model size, DDPM can make better use of more data, and a more diverse set of speakers, than MSE models. We achieve the best reported ratio between real and synthetic speech WER to date (1.46), but also find that a large gap remains.
Semi-Supervised Cognitive State Classification from Speech with Multi-View Pseudo-Labeling
Sep 25, 2024



The lack of labeled data is a common challenge in speech classification tasks, particularly those requiring extensive subjective assessment, such as cognitive state classification. In this work, we propose a Semi-Supervised Learning (SSL) framework, introducing a novel multi-view pseudo-labeling method that leverages both acoustic and linguistic characteristics to select the most confident data for training the classification model. Acoustically, unlabeled data are compared to labeled data using the Frechet audio distance, calculated from embeddings generated by multiple audio encoders. Linguistically, large language models are prompted to revise automatic speech recognition transcriptions and predict labels based on our proposed task-specific knowledge. High-confidence data are identified when pseudo-labels from both sources align, while mismatches are treated as low-confidence data. A bimodal classifier is then trained to iteratively label the low-confidence data until a predefined criterion is met. We evaluate our SSL framework on emotion recognition and dementia detection tasks. Experimental results demonstrate that our method achieves competitive performance compared to fully supervised learning using only 30% of the labeled data and significantly outperforms two selected baselines.
Large Language Model Based Generative Error Correction: A Challenge and Baselines for Speech Recognition, Speaker Tagging, and Emotion Recognition
Sep 17, 2024



Given recent advances in generative AI technology, a key question is how large language models (LLMs) can enhance acoustic modeling tasks using text decoding results from a frozen, pretrained automatic speech recognition (ASR) model. To explore new capabilities in language modeling for speech processing, we introduce the generative speech transcription error correction (GenSEC) challenge. This challenge comprises three post-ASR language modeling tasks: (i) post-ASR transcription correction, (ii) speaker tagging, and (iii) emotion recognition. These tasks aim to emulate future LLM-based agents handling voice-based interfaces while remaining accessible to a broad audience by utilizing open pretrained language models or agent-based APIs. We also discuss insights from baseline evaluations, as well as lessons learned for designing future evaluations.