 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePReMISE: Policy Rubrics as Measurement Specifications for LLM Judges
May 29, 2026LLM judges are increasingly used to evaluate open-ended responses, but their scores depend strongly on the rubrics that condition them. A vague rubric asking for a response to be ``helpful and factual'' can reward polished answers that invent facts or violate user intent. We treat reusable rubrics as measurement specifications: changing the rubric changes the response quality measurement induced by a fixed judge. We introduce PReMISE, a framework that, given pairwise human-preference data, (i) discovers a policy-level rubric set, and (ii) audits any rubric set under LLM-judge use along four axes: structural adequacy, reliability, preference fit, and adversarial robustness. Across rubric sources no raw source is simultaneously reliable, preference-predictive, and adversarially robust; and high inter-rater agreement does not imply low exploitability. PReMISE is the only rubric source to score non-trivially on applicability, specificity, and effective dimensionality simultaneously. We contribute two audit-targeted repair operations: preference-rank selection raises judge accuracy on paired responses from $65.0\%$ to $68.6\%$, competitive with the strongest rubric-discovery baselines and leading on two of three judges in our cross-judge sweep; reliability-constrained refinement reduces the rate at which exploit responses receive high scores from $46.4\%$ to $36.0\%$ with little change in inter-judge agreement ($α{=}.531\to.519$).
ARES: Adaptive Red-Teaming and End-to-End Repair of Policy-Reward System
Apr 20, 2026Reinforcement Learning from Human Feedback (RLHF) is central to aligning Large Language Models (LLMs), yet it introduces a critical vulnerability: an imperfect Reward Model (RM) can become a single point of failure when it fails to penalize unsafe behaviors. While existing red-teaming approaches primarily target policy-level weaknesses, they overlook what we term systemic weaknesses cases where both the core LLM and the RM fail in tandem. We present ARES, a framework that systematically discovers and mitigates such dual vulnerabilities. ARES employs a ``Safety Mentor'' that dynamically composes semantically coherent adversarial prompts by combining structured component types (topics, personas, tactics, goals) and generates corresponding malicious and safe responses. This dual-targeting approach exposes weaknesses in both the core LLM and the RM simultaneously. Using the vulnerabilities gained, ARES implements a two-stage repair process: first fine-tuning the RM to better detect harmful content, then leveraging the improved RM to optimize the core model. Experiments across multiple adversarial safety benchmarks demonstrate that ARES substantially enhances safety robustness while preserving model capabilities, establishing a new paradigm for comprehensive RLHF safety alignment.
Towards Safety Reasoning in LLMs: AI-agentic Deliberation for Policy-embedded CoT Data Creation
May 27, 2025Safety reasoning is a recent paradigm where LLMs reason over safety policies before generating responses, thereby mitigating limitations in existing safety measures such as over-refusal and jailbreak vulnerabilities. However, implementing this paradigm is challenging due to the resource-intensive process of creating high-quality policy-embedded chain-of-thought (CoT) datasets while ensuring reasoning remains accurate and free from hallucinations or policy conflicts. To tackle this, we propose AIDSAFE: Agentic Iterative Deliberation for Safety Reasoning, a novel data generation recipe that leverages multi-agent deliberation to iteratively expand reasoning on safety policies. A data refiner stage in AIDSAFE ensures high-quality outputs by eliminating repetitive, redundant, and deceptive thoughts. AIDSAFE-generated CoTs provide a strong foundation for supervised fine-tuning (SFT)-based safety training. Additionally, to address the need of preference data in alignment stages, such as DPO training, we introduce a supplemental recipe that uses belief augmentation to create distinct selected and rejected CoT samples. Our evaluations demonstrate that AIDSAFE-generated CoTs achieve superior policy adherence and reasoning quality. Consequently, we show that fine-tuning open-source LLMs on these CoTs can significantly improve safety generalization and jailbreak robustness while maintaining acceptable utility and over-refusal accuracy. AIDSAFE-generated CoT datasets can be found here: https://huggingface.co/datasets/AmazonScience/AIDSAFE
CyberBOT: Towards Reliable Cybersecurity Education via Ontology-Grounded Retrieval Augmented Generation
Apr 01, 2025


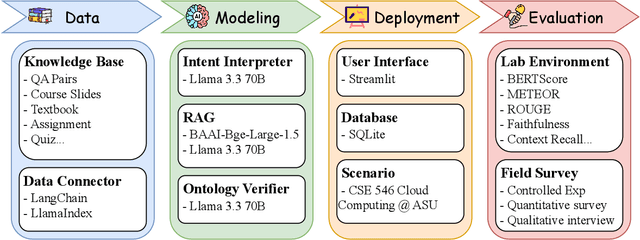
Advancements in large language models (LLMs) have enabled the development of intelligent educational tools that support inquiry-based learning across technical domains. In cybersecurity education, where accuracy and safety are paramount, systems must go beyond surface-level relevance to provide information that is both trustworthy and domain-appropriate. To address this challenge, we introduce CyberBOT, a question-answering chatbot that leverages a retrieval-augmented generation (RAG) pipeline to incorporate contextual information from course-specific materials and validate responses using a domain-specific cybersecurity ontology. The ontology serves as a structured reasoning layer that constrains and verifies LLM-generated answers, reducing the risk of misleading or unsafe guidance. CyberBOT has been deployed in a large graduate-level course at Arizona State University (ASU), where more than one hundred students actively engage with the system through a dedicated web-based platform. Computational evaluations in lab environments highlight the potential capacity of CyberBOT, and a forthcoming field study will evaluate its pedagogical impact. By integrating structured domain reasoning with modern generative capabilities, CyberBOT illustrates a promising direction for developing reliable and curriculum-aligned AI applications in specialized educational contexts.
RedditESS: A Mental Health Social Support Interaction Dataset -- Understanding Effective Social Support to Refine AI-Driven Support Tools
Mar 27, 2025Effective mental health support is crucial for alleviating psychological distress. While large language model (LLM)-based assistants have shown promise in mental health interventions, existing research often defines "effective" support primarily in terms of empathetic acknowledgments, overlooking other essential dimensions such as informational guidance, community validation, and tangible coping strategies. To address this limitation and better understand what constitutes effective support, we introduce RedditESS, a novel real-world dataset derived from Reddit posts, including supportive comments and original posters' follow-up responses. Grounded in established social science theories, we develop an ensemble labeling mechanism to annotate supportive comments as effective or not and perform qualitative assessments to ensure the reliability of the annotations. Additionally, we demonstrate the practical utility of RedditESS by using it to guide LLM alignment toward generating more context-sensitive and genuinely helpful supportive responses. By broadening the understanding of effective support, our study paves the way for advanced AI-driven mental health interventions.
Personalized Attacks of Social Engineering in Multi-turn Conversations -- LLM Agents for Simulation and Detection
Mar 18, 2025



The rapid advancement of conversational agents, particularly chatbots powered by Large Language Models (LLMs), poses a significant risk of social engineering (SE) attacks on social media platforms. SE detection in multi-turn, chat-based interactions is considerably more complex than single-instance detection due to the dynamic nature of these conversations. A critical factor in mitigating this threat is understanding the mechanisms through which SE attacks operate, specifically how attackers exploit vulnerabilities and how victims' personality traits contribute to their susceptibility. In this work, we propose an LLM-agentic framework, SE-VSim, to simulate SE attack mechanisms by generating multi-turn conversations. We model victim agents with varying personality traits to assess how psychological profiles influence susceptibility to manipulation. Using a dataset of over 1000 simulated conversations, we examine attack scenarios in which adversaries, posing as recruiters, funding agencies, and journalists, attempt to extract sensitive information. Based on this analysis, we present a proof of concept, SE-OmniGuard, to offer personalized protection to users by leveraging prior knowledge of the victims personality, evaluating attack strategies, and monitoring information exchanges in conversations to identify potential SE attempts.
Ontology-Aware RAG for Improved Question-Answering in Cybersecurity Education
Dec 10, 2024Integrating AI into education has the potential to transform the teaching of science and technology courses, particularly in the field of cybersecurity. AI-driven question-answering (QA) systems can actively manage uncertainty in cybersecurity problem-solving, offering interactive, inquiry-based learning experiences. Large language models (LLMs) have gained prominence in AI-driven QA systems, offering advanced language understanding and user engagement. However, they face challenges like hallucinations and limited domain-specific knowledge, which reduce their reliability in educational settings. To address these challenges, we propose CyberRAG, an ontology-aware retrieval-augmented generation (RAG) approach for developing a reliable and safe QA system in cybersecurity education. CyberRAG employs a two-step approach: first, it augments the domain-specific knowledge by retrieving validated cybersecurity documents from a knowledge base to enhance the relevance and accuracy of the response. Second, it mitigates hallucinations and misuse by integrating a knowledge graph ontology to validate the final answer. Experiments on publicly available cybersecurity datasets show that CyberRAG delivers accurate, reliable responses aligned with domain knowledge, demonstrating the potential of AI tools to enhance education.
LRQ-Fact: LLM-Generated Relevant Questions for Multimodal Fact-Checking
Oct 06, 2024



Human fact-checkers have specialized domain knowledge that allows them to formulate precise questions to verify information accuracy. However, this expert-driven approach is labor-intensive and is not scalable, especially when dealing with complex multimodal misinformation. In this paper, we propose a fully-automated framework, LRQ-Fact, for multimodal fact-checking. Firstly, the framework leverages Vision-Language Models (VLMs) and Large Language Models (LLMs) to generate comprehensive questions and answers for probing multimodal content. Next, a rule-based decision-maker module evaluates both the original content and the generated questions and answers to assess the overall veracity. Extensive experiments on two benchmarks show that LRQ-Fact improves detection accuracy for multimodal misinformation. Moreover, we evaluate its generalizability across different model backbones, offering valuable insights for further refinement.
Mindful-RAG: A Study of Points of Failure in Retrieval Augmented Generation
Jul 16, 2024

Large Language Models (LLMs) are proficient at generating coherent and contextually relevant text but face challenges when addressing knowledge-intensive queries in domain-specific and factual question-answering tasks. Retrieval-augmented generation (RAG) systems mitigate this by incorporating external knowledge sources, such as structured knowledge graphs (KGs). However, LLMs often struggle to produce accurate answers despite access to KG-extracted information containing necessary facts. Our study investigates this dilemma by analyzing error patterns in existing KG-based RAG methods and identifying eight critical failure points. We observed that these errors predominantly occur due to insufficient focus on discerning the question's intent and adequately gathering relevant context from the knowledge graph facts. Drawing on this analysis, we propose the Mindful-RAG approach, a framework designed for intent-based and contextually aligned knowledge retrieval. This method explicitly targets the identified failures and offers improvements in the correctness and relevance of responses provided by LLMs, representing a significant step forward from existing methods.
Defending Against Social Engineering Attacks in the Age of LLMs
Jun 18, 2024



The proliferation of Large Language Models (LLMs) poses challenges in detecting and mitigating digital deception, as these models can emulate human conversational patterns and facilitate chat-based social engineering (CSE) attacks. This study investigates the dual capabilities of LLMs as both facilitators and defenders against CSE threats. We develop a novel dataset, SEConvo, simulating CSE scenarios in academic and recruitment contexts, and designed to examine how LLMs can be exploited in these situations. Our findings reveal that, while off-the-shelf LLMs generate high-quality CSE content, their detection capabilities are suboptimal, leading to increased operational costs for defense. In response, we propose ConvoSentinel, a modular defense pipeline that improves detection at both the message and the conversation levels, offering enhanced adaptability and cost-effectiveness. The retrieval-augmented module in ConvoSentinel identifies malicious intent by comparing messages to a database of similar conversations, enhancing CSE detection at all stages. Our study highlights the need for advanced strategies to leverage LLMs in cybersecurity.