 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSAM Audio Judge: A Unified Multimodal Framework for Perceptual Evaluation of Audio Separation
Jan 27, 2026The performance evaluation remains a complex challenge in audio separation, and existing evaluation metrics are often misaligned with human perception, course-grained, relying on ground truth signals. On the other hand, subjective listening tests remain the gold standard for real-world evaluation, but they are expensive, time-consuming, and difficult to scale. This paper addresses the growing need for automated systems capable of evaluating audio separation without human intervention. The proposed evaluation metric, SAM Audio Judge (SAJ), is a multimodal fine-grained reference-free objective metric, which shows highly alignment with human perceptions. SAJ supports three audio domains (speech, music and general sound events) and three prompt inputs (text, visual and span), covering four different dimensions of evaluation (recall, percision, faithfulness, and overall). SAM Audio Judge also shows potential applications in data filtering, pseudo-labeling large datasets and reranking in audio separation models. We release our code and pre-trained models at: https://github.com/facebookresearch/sam-audio.
SAM Audio: Segment Anything in Audio
Dec 19, 2025



General audio source separation is a key capability for multimodal AI systems that can perceive and reason about sound. Despite substantial progress in recent years, existing separation models are either domain-specific, designed for fixed categories such as speech or music, or limited in controllability, supporting only a single prompting modality such as text. In this work, we present SAM Audio, a foundation model for general audio separation that unifies text, visual, and temporal span prompting within a single framework. Built on a diffusion transformer architecture, SAM Audio is trained with flow matching on large-scale audio data spanning speech, music, and general sounds, and can flexibly separate target sources described by language, visual masks, or temporal spans. The model achieves state-of-the-art performance across a diverse suite of benchmarks, including general sound, speech, music, and musical instrument separation in both in-the-wild and professionally produced audios, substantially outperforming prior general-purpose and specialized systems. Furthermore, we introduce a new real-world separation benchmark with human-labeled multimodal prompts and a reference-free evaluation model that correlates strongly with human judgment.
Meta Audiobox Aesthetics: Unified Automatic Quality Assessment for Speech, Music, and Sound
Feb 07, 2025



The quantification of audio aesthetics remains a complex challenge in audio processing, primarily due to its subjective nature, which is influenced by human perception and cultural context. Traditional methods often depend on human listeners for evaluation, leading to inconsistencies and high resource demands. This paper addresses the growing need for automated systems capable of predicting audio aesthetics without human intervention. Such systems are crucial for applications like data filtering, pseudo-labeling large datasets, and evaluating generative audio models, especially as these models become more sophisticated. In this work, we introduce a novel approach to audio aesthetic evaluation by proposing new annotation guidelines that decompose human listening perspectives into four distinct axes. We develop and train no-reference, per-item prediction models that offer a more nuanced assessment of audio quality. Our models are evaluated against human mean opinion scores (MOS) and existing methods, demonstrating comparable or superior performance. This research not only advances the field of audio aesthetics but also provides open-source models and datasets to facilitate future work and benchmarking. We release our code and pre-trained model at: https://github.com/facebookresearch/audiobox-aesthetics
Audiobox TTA-RAG: Improving Zero-Shot and Few-Shot Text-To-Audio with Retrieval-Augmented Generation
Nov 07, 2024Current leading Text-To-Audio (TTA) generation models suffer from degraded performance on zero-shot and few-shot settings. It is often challenging to generate high-quality audio for audio events that are unseen or uncommon in the training set. Inspired by the success of Retrieval-Augmented Generation (RAG) in Large Language Model (LLM)-based knowledge-intensive tasks, we extend the TTA process with additional conditioning contexts. We propose Audiobox TTA-RAG, a novel retrieval-augmented TTA approach based on Audiobox, a conditional flow-matching audio generation model. Unlike the vanilla Audiobox TTA solution which generates audio conditioned on text, we augmented the conditioning input with retrieved audio samples that provide additional acoustic information to generate the target audio. Our retrieval method does not require the external database to have labeled audio, offering more practical use cases. To evaluate our proposed method, we curated test sets in zero-shot and few-shot settings. Our empirical results show that the proposed model can effectively leverage the retrieved audio samples and significantly improve zero-shot and few-shot TTA performance, with large margins on multiple evaluation metrics, while maintaining the ability to generate semantically aligned audio for the in-domain setting. In addition, we investigate the effect of different retrieval methods and data sources.
MusicFlow: Cascaded Flow Matching for Text Guided Music Generation
Oct 27, 2024



We introduce MusicFlow, a cascaded text-to-music generation model based on flow matching. Based on self-supervised representations to bridge between text descriptions and music audios, we construct two flow matching networks to model the conditional distribution of semantic and acoustic features. Additionally, we leverage masked prediction as the training objective, enabling the model to generalize to other tasks such as music infilling and continuation in a zero-shot manner. Experiments on MusicCaps reveal that the music generated by MusicFlow exhibits superior quality and text coherence despite being over $2\sim5$ times smaller and requiring $5$ times fewer iterative steps. Simultaneously, the model can perform other music generation tasks and achieves competitive performance in music infilling and continuation. Our code and model will be publicly available.
Movie Gen: A Cast of Media Foundation Models
Oct 17, 2024



We present Movie Gen, a cast of foundation models that generates high-quality, 1080p HD videos with different aspect ratios and synchronized audio. We also show additional capabilities such as precise instruction-based video editing and generation of personalized videos based on a user's image. Our models set a new state-of-the-art on multiple tasks: text-to-video synthesis, video personalization, video editing, video-to-audio generation, and text-to-audio generation. Our largest video generation model is a 30B parameter transformer trained with a maximum context length of 73K video tokens, corresponding to a generated video of 16 seconds at 16 frames-per-second. We show multiple technical innovations and simplifications on the architecture, latent spaces, training objectives and recipes, data curation, evaluation protocols, parallelization techniques, and inference optimizations that allow us to reap the benefits of scaling pre-training data, model size, and training compute for training large scale media generation models. We hope this paper helps the research community to accelerate progress and innovation in media generation models. All videos from this paper are available at https://go.fb.me/MovieGenResearchVideos.
Learning Fine-Grained Controllability on Speech Generation via Efficient Fine-Tuning
Jun 10, 2024



As the scale of generative models continues to grow, efficient reuse and adaptation of pre-trained models have become crucial considerations. In this work, we propose Voicebox Adapter, a novel approach that integrates fine-grained conditions into a pre-trained Voicebox speech generation model using a cross-attention module. To ensure a smooth integration of newly added modules with pre-trained ones, we explore various efficient fine-tuning approaches. Our experiment shows that the LoRA with bias-tuning configuration yields the best performance, enhancing controllability without compromising speech quality. Across three fine-grained conditional generation tasks, we demonstrate the effectiveness and resource efficiency of Voicebox Adapter. Follow-up experiments further highlight the robustness of Voicebox Adapter across diverse data setups.
Audiobox: Unified Audio Generation with Natural Language Prompts
Dec 25, 2023



Audio is an essential part of our life, but creating it often requires expertise and is time-consuming. Research communities have made great progress over the past year advancing the performance of large scale audio generative models for a single modality (speech, sound, or music) through adopting more powerful generative models and scaling data. However, these models lack controllability in several aspects: speech generation models cannot synthesize novel styles based on text description and are limited on domain coverage such as outdoor environments; sound generation models only provide coarse-grained control based on descriptions like "a person speaking" and would only generate mumbling human voices. This paper presents Audiobox, a unified model based on flow-matching that is capable of generating various audio modalities. We design description-based and example-based prompting to enhance controllability and unify speech and sound generation paradigms. We allow transcript, vocal, and other audio styles to be controlled independently when generating speech. To improve model generalization with limited labels, we adapt a self-supervised infilling objective to pre-train on large quantities of unlabeled audio. Audiobox sets new benchmarks on speech and sound generation (0.745 similarity on Librispeech for zero-shot TTS; 0.77 FAD on AudioCaps for text-to-sound) and unlocks new methods for generating audio with novel vocal and acoustic styles. We further integrate Bespoke Solvers, which speeds up generation by over 25 times compared to the default ODE solver for flow-matching, without loss of performance on several tasks. Our demo is available at https://audiobox.metademolab.com/
Generative Pre-training for Speech with Flow Matching
Oct 25, 2023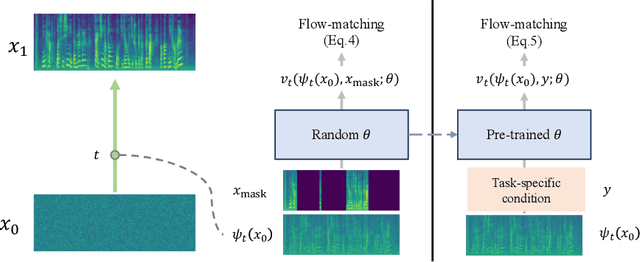
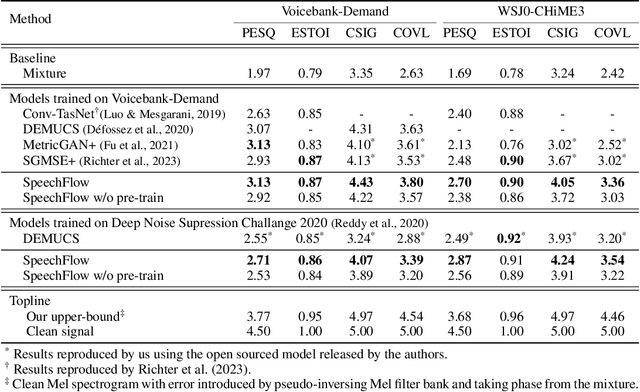
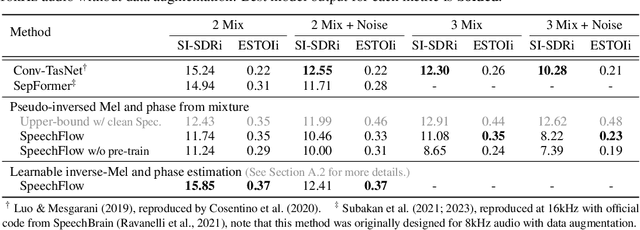
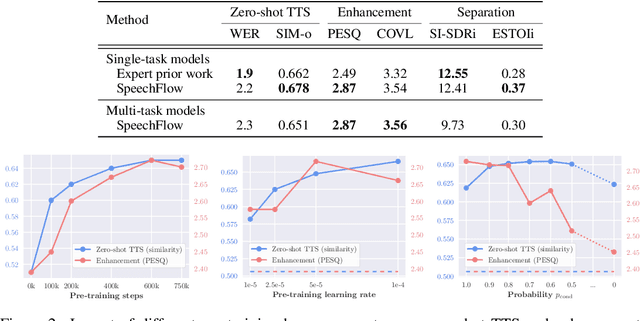
Generative models have gained more and more attention in recent years for their remarkable success in tasks that required estimating and sampling data distribution to generate high-fidelity synthetic data. In speech, text-to-speech synthesis and neural vocoder are good examples where generative models have shined. While generative models have been applied to different applications in speech, there exists no general-purpose generative model that models speech directly. In this work, we take a step toward this direction by showing a single pre-trained generative model can be adapted to different downstream tasks with strong performance. Specifically, we pre-trained a generative model, named SpeechFlow, on 60k hours of untranscribed speech with Flow Matching and masked conditions. Experiment results show the pre-trained generative model can be fine-tuned with task-specific data to match or surpass existing expert models on speech enhancement, separation, and synthesis. Our work suggested a foundational model for generation tasks in speech can be built with generative pre-training.
Dynamic ASR Pathways: An Adaptive Masking Approach Towards Efficient Pruning of A Multilingual ASR Model
Sep 22, 2023



Neural network pruning offers an effective method for compressing a multilingual automatic speech recognition (ASR) model with minimal performance loss. However, it entails several rounds of pruning and re-training needed to be run for each language. In this work, we propose the use of an adaptive masking approach in two scenarios for pruning a multilingual ASR model efficiently, each resulting in sparse monolingual models or a sparse multilingual model (named as Dynamic ASR Pathways). Our approach dynamically adapts the sub-network, avoiding premature decisions about a fixed sub-network structure. We show that our approach outperforms existing pruning methods when targeting sparse monolingual models. Further, we illustrate that Dynamic ASR Pathways jointly discovers and trains better sub-networks (pathways) of a single multilingual model by adapting from different sub-network initializations, thereby reducing the need for language-specific pruning.