 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFull-Rank No More: Low-Rank Weight Training for Modern Speech Recognition Models
Oct 10, 2024



This paper investigates the under-explored area of low-rank weight training for large-scale Conformer-based speech recognition models from scratch. Our study demonstrates the viability of this training paradigm for such models, yielding several notable findings. Firstly, we discover that applying a low-rank structure exclusively to the attention modules can unexpectedly enhance performance, even with a significant rank reduction of 12%. In contrast, feed-forward layers present greater challenges, as they begin to exhibit performance degradation with a moderate 50% rank reduction. Furthermore, we find that both initialization and layer-wise rank assignment play critical roles in successful low-rank training. Specifically, employing SVD initialization and linear layer-wise rank mapping significantly boosts the efficacy of low-rank weight training. Building on these insights, we introduce the Low-Rank Speech Model from Scratch (LR-SMS), an approach that achieves performance parity with full-rank training while delivering substantial reductions in parameters count (by at least 2x), and training time speedups (by 1.3x for ASR and 1.15x for AVSR).
Dynamic Data Pruning for Automatic Speech Recognition
Jun 26, 2024



The recent success of Automatic Speech Recognition (ASR) is largely attributed to the ever-growing amount of training data. However, this trend has made model training prohibitively costly and imposed computational demands. While data pruning has been proposed to mitigate this issue by identifying a small subset of relevant data, its application in ASR has been barely explored, and existing works often entail significant overhead to achieve meaningful results. To fill this gap, this paper presents the first investigation of dynamic data pruning for ASR, finding that we can reach the full-data performance by dynamically selecting 70% of data. Furthermore, we introduce Dynamic Data Pruning for ASR (DDP-ASR), which offers several fine-grained pruning granularities specifically tailored for speech-related datasets, going beyond the conventional pruning of entire time sequences. Our intensive experiments show that DDP-ASR can save up to 1.6x training time with negligible performance loss.
MSRS: Training Multimodal Speech Recognition Models from Scratch with Sparse Mask Optimization
Jun 25, 2024



Pre-trained models have been a foundational approach in speech recognition, albeit with associated additional costs. In this study, we propose a regularization technique that facilitates the training of visual and audio-visual speech recognition models (VSR and AVSR) from scratch. This approach, abbreviated as \textbf{MSRS} (Multimodal Speech Recognition from Scratch), introduces a sparse regularization that rapidly learns sparse structures within the dense model at the very beginning of training, which receives healthier gradient flow than the dense equivalent. Once the sparse mask stabilizes, our method allows transitioning to a dense model or keeping a sparse model by updating non-zero values. MSRS achieves competitive results in VSR and AVSR with 21.1% and 0.9% WER on the LRS3 benchmark, while reducing training time by at least 2x. We explore other sparse approaches and show that only MSRS enables training from scratch by implicitly masking the weights affected by vanishing gradients.
SparseVSR: Lightweight and Noise Robust Visual Speech Recognition
Jul 10, 2023



Recent advances in deep neural networks have achieved unprecedented success in visual speech recognition. However, there remains substantial disparity between current methods and their deployment in resource-constrained devices. In this work, we explore different magnitude-based pruning techniques to generate a lightweight model that achieves higher performance than its dense model equivalent, especially under the presence of visual noise. Our sparse models achieve state-of-the-art results at 10% sparsity on the LRS3 dataset and outperform the dense equivalent up to 70% sparsity. We evaluate our 50% sparse model on 7 different visual noise types and achieve an overall absolute improvement of more than 2% WER compared to the dense equivalent. Our results confirm that sparse networks are more resistant to noise than dense networks.
Auto-AVSR: Audio-Visual Speech Recognition with Automatic Labels
Mar 25, 2023



Audio-visual speech recognition has received a lot of attention due to its robustness against acoustic noise. Recently, the performance of automatic, visual, and audio-visual speech recognition (ASR, VSR, and AV-ASR, respectively) has been substantially improved, mainly due to the use of larger models and training sets. However, accurate labelling of datasets is time-consuming and expensive. Hence, in this work, we investigate the use of automatically-generated transcriptions of unlabelled datasets to increase the training set size. For this purpose, we use publicly-available pre-trained ASR models to automatically transcribe unlabelled datasets such as AVSpeech and VoxCeleb2. Then, we train ASR, VSR and AV-ASR models on the augmented training set, which consists of the LRS2 and LRS3 datasets as well as the additional automatically-transcribed data. We demonstrate that increasing the size of the training set, a recent trend in the literature, leads to reduced WER despite using noisy transcriptions. The proposed model achieves new state-of-the-art performance on AV-ASR on LRS2 and LRS3. In particular, it achieves a WER of 0.9% on LRS3, a relative improvement of 30% over the current state-of-the-art approach, and outperforms methods that have been trained on non-publicly available datasets with 26 times more training data.
Automatic Viseme Vocabulary Construction to Enhance Continuous Lip-reading
Apr 26, 2017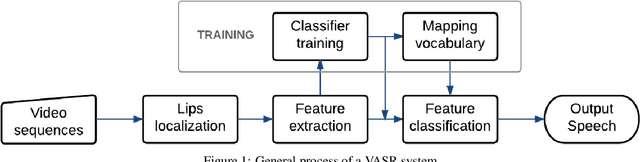



Speech is the most common communication method between humans and involves the perception of both auditory and visual channels. Automatic speech recognition focuses on interpreting the audio signals, but it has been demonstrated that video can provide information that is complementary to the audio. Thus, the study of automatic lip-reading is important and is still an open problem. One of the key challenges is the definition of the visual elementary units (the visemes) and their vocabulary. Many researchers have analyzed the importance of the phoneme to viseme mapping and have proposed viseme vocabularies with lengths between 11 and 15 visemes. These viseme vocabularies have usually been manually defined by their linguistic properties and in some cases using decision trees or clustering techniques. In this work, we focus on the automatic construction of an optimal viseme vocabulary based on the association of phonemes with similar appearance. To this end, we construct an automatic system that uses local appearance descriptors to extract the main characteristics of the mouth region and HMMs to model the statistic relations of both viseme and phoneme sequences. To compare the performance of the system different descriptors (PCA, DCT and SIFT) are analyzed. We test our system in a Spanish corpus of continuous speech. Our results indicate that we are able to recognize approximately 58% of the visemes, 47% of the phonemes and 23% of the words in a continuous speech scenario and that the optimal viseme vocabulary for Spanish is composed by 20 visemes.
Towards Estimating the Upper Bound of Visual-Speech Recognition: The Visual Lip-Reading Feasibility Database
Apr 26, 2017
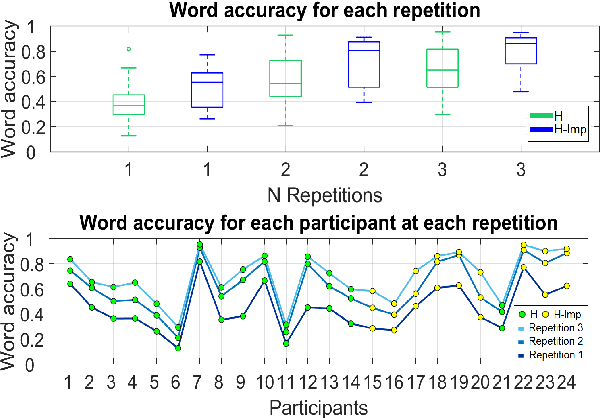
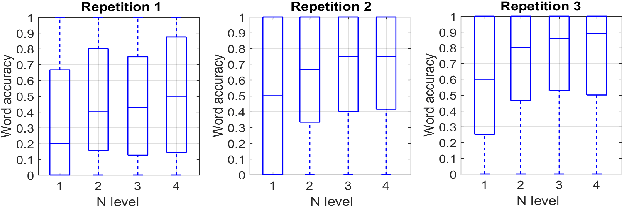
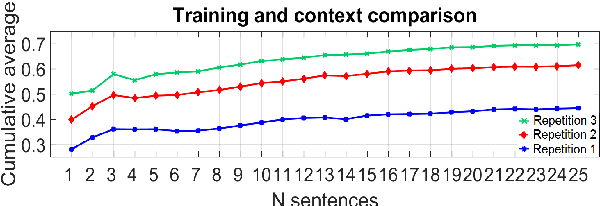
Speech is the most used communication method between humans and it involves the perception of auditory and visual channels. Automatic speech recognition focuses on interpreting the audio signals, although the video can provide information that is complementary to the audio. Exploiting the visual information, however, has proven challenging. On one hand, researchers have reported that the mapping between phonemes and visemes (visual units) is one-to-many because there are phonemes which are visually similar and indistinguishable between them. On the other hand, it is known that some people are very good lip-readers (e.g: deaf people). We study the limit of visual only speech recognition in controlled conditions. With this goal, we designed a new database in which the speakers are aware of being read and aim to facilitate lip-reading. In the literature, there are discrepancies on whether hearing-impaired people are better lip-readers than normal-hearing people. Then, we analyze if there are differences between the lip-reading abilities of 9 hearing-impaired and 15 normal-hearing people. Finally, human abilities are compared with the performance of a visual automatic speech recognition system. In our tests, hearing-impaired participants outperformed the normal-hearing participants but without reaching statistical significance. Human observers were able to decode 44% of the spoken message. In contrast, the visual only automatic system achieved 20% of word recognition rate. However, if we repeat the comparison in terms of phonemes both obtained very similar recognition rates, just above 50%. This suggests that the gap between human lip-reading and automatic speech-reading might be more related to the use of context than to the ability to interpret mouth appearance.