 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRevival with Voice: Multi-modal Controllable Text-to-Speech Synthesis
May 25, 2025This paper explores multi-modal controllable Text-to-Speech Synthesis (TTS) where the voice can be generated from face image, and the characteristics of output speech (e.g., pace, noise level, distance, tone, place) can be controllable with natural text description. Specifically, we aim to mitigate the following three challenges in face-driven TTS systems. 1) To overcome the limited audio quality of audio-visual speech corpora, we propose a training method that additionally utilizes high-quality audio-only speech corpora. 2) To generate voices not only from real human faces but also from artistic portraits, we propose augmenting the input face image with stylization. 3) To consider one-to-many possibilities in face-to-voice mapping and ensure consistent voice generation at the same time, we propose to first employ sampling-based decoding and then use prompting with generated speech samples. Experimental results validate the proposed model's effectiveness in face-driven voice synthesis.
Contextual Speech Extraction: Leveraging Textual History as an Implicit Cue for Target Speech Extraction
Mar 11, 2025



In this paper, we investigate a novel approach for Target Speech Extraction (TSE), which relies solely on textual context to extract the target speech. We refer to this task as Contextual Speech Extraction (CSE). Unlike traditional TSE methods that rely on pre-recorded enrollment utterances, video of the target speaker's face, spatial information, or other explicit cues to identify the target stream, our proposed method requires only a few turns of previous dialogue (or monologue) history. This approach is naturally feasible in mobile messaging environments where voice recordings are typically preceded by textual dialogue that can be leveraged implicitly. We present three CSE models and analyze their performances on three datasets. Through our experiments, we demonstrate that even when the model relies purely on dialogue history, it can achieve over 90 % accuracy in identifying the correct target stream with only two previous dialogue turns. Furthermore, we show that by leveraging both textual context and enrollment utterances as cues during training, we further enhance our model's flexibility and effectiveness, allowing us to use either cue during inference, or combine both for improved performance. Samples and code available on https://miraodasilva.github.io/cse-project-page .
Efficient Audiovisual Speech Processing via MUTUD: Multimodal Training and Unimodal Deployment
Jan 30, 2025



Building reliable speech systems often requires combining multiple modalities, like audio and visual cues. While such multimodal solutions frequently lead to improvements in performance and may even be critical in certain cases, they come with several constraints such as increased sensory requirements, computational cost, and modality synchronization, to mention a few. These challenges constrain the direct uses of these multimodal solutions in real-world applications. In this work, we develop approaches where the learning happens with all available modalities but the deployment or inference is done with just one or reduced modalities. To do so, we propose a Multimodal Training and Unimodal Deployment (MUTUD) framework which includes a Temporally Aligned Modality feature Estimation (TAME) module that can estimate information from missing modality using modalities present during inference. This innovative approach facilitates the integration of information across different modalities, enhancing the overall inference process by leveraging the strengths of each modality to compensate for the absence of certain modalities during inference. We apply MUTUD to various audiovisual speech tasks and show that it can reduce the performance gap between the multimodal and corresponding unimodal models to a considerable extent. MUTUD can achieve this while reducing the model size and compute compared to multimodal models, in some cases by almost 80%.
Unified Speech Recognition: A Single Model for Auditory, Visual, and Audiovisual Inputs
Nov 04, 2024



Research in auditory, visual, and audiovisual speech recognition (ASR, VSR, and AVSR, respectively) has traditionally been conducted independently. Even recent self-supervised studies addressing two or all three tasks simultaneously tend to yield separate models, leading to disjoint inference pipelines with increased memory requirements and redundancies. This paper proposes unified training strategies for these systems. We demonstrate that training a single model for all three tasks enhances VSR and AVSR performance, overcoming typical optimisation challenges when training from scratch. Moreover, we introduce a greedy pseudo-labelling approach to more effectively leverage unlabelled samples, addressing shortcomings in related self-supervised methods. Finally, we develop a self-supervised pre-training method within our framework, proving its effectiveness alongside our semi-supervised approach. Despite using a single model for all tasks, our unified approach achieves state-of-the-art performance compared to recent methods on LRS3 and LRS2 for ASR, VSR, and AVSR, as well as on the newly released WildVSR dataset. Code and models are available at https://github.com/ahaliassos/usr.
RT-LA-VocE: Real-Time Low-SNR Audio-Visual Speech Enhancement
Jul 10, 2024



In this paper, we aim to generate clean speech frame by frame from a live video stream and a noisy audio stream without relying on future inputs. To this end, we propose RT-LA-VocE, which completely re-designs every component of LA-VocE, a state-of-the-art non-causal audio-visual speech enhancement model, to perform causal real-time inference with a 40ms input frame. We do so by devising new visual and audio encoders that rely solely on past frames, replacing the Transformer encoder with the Emformer, and designing a new causal neural vocoder C-HiFi-GAN. On the popular AVSpeech dataset, we show that our algorithm achieves state-of-the-art results in all real-time scenarios. More importantly, each component is carefully tuned to minimize the algorithm latency to the theoretical minimum (40ms) while maintaining a low end-to-end processing latency of 28.15ms per frame, enabling real-time frame-by-frame enhancement with minimal delay.
MSRS: Training Multimodal Speech Recognition Models from Scratch with Sparse Mask Optimization
Jun 25, 2024



Pre-trained models have been a foundational approach in speech recognition, albeit with associated additional costs. In this study, we propose a regularization technique that facilitates the training of visual and audio-visual speech recognition models (VSR and AVSR) from scratch. This approach, abbreviated as \textbf{MSRS} (Multimodal Speech Recognition from Scratch), introduces a sparse regularization that rapidly learns sparse structures within the dense model at the very beginning of training, which receives healthier gradient flow than the dense equivalent. Once the sparse mask stabilizes, our method allows transitioning to a dense model or keeping a sparse model by updating non-zero values. MSRS achieves competitive results in VSR and AVSR with 21.1% and 0.9% WER on the LRS3 benchmark, while reducing training time by at least 2x. We explore other sparse approaches and show that only MSRS enables training from scratch by implicitly masking the weights affected by vanishing gradients.
SparseVSR: Lightweight and Noise Robust Visual Speech Recognition
Jul 10, 2023



Recent advances in deep neural networks have achieved unprecedented success in visual speech recognition. However, there remains substantial disparity between current methods and their deployment in resource-constrained devices. In this work, we explore different magnitude-based pruning techniques to generate a lightweight model that achieves higher performance than its dense model equivalent, especially under the presence of visual noise. Our sparse models achieve state-of-the-art results at 10% sparsity on the LRS3 dataset and outperform the dense equivalent up to 70% sparsity. We evaluate our 50% sparse model on 7 different visual noise types and achieve an overall absolute improvement of more than 2% WER compared to the dense equivalent. Our results confirm that sparse networks are more resistant to noise than dense networks.
SynthVSR: Scaling Up Visual Speech Recognition With Synthetic Supervision
Apr 03, 2023



Recently reported state-of-the-art results in visual speech recognition (VSR) often rely on increasingly large amounts of video data, while the publicly available transcribed video datasets are limited in size. In this paper, for the first time, we study the potential of leveraging synthetic visual data for VSR. Our method, termed SynthVSR, substantially improves the performance of VSR systems with synthetic lip movements. The key idea behind SynthVSR is to leverage a speech-driven lip animation model that generates lip movements conditioned on the input speech. The speech-driven lip animation model is trained on an unlabeled audio-visual dataset and could be further optimized towards a pre-trained VSR model when labeled videos are available. As plenty of transcribed acoustic data and face images are available, we are able to generate large-scale synthetic data using the proposed lip animation model for semi-supervised VSR training. We evaluate the performance of our approach on the largest public VSR benchmark - Lip Reading Sentences 3 (LRS3). SynthVSR achieves a WER of 43.3% with only 30 hours of real labeled data, outperforming off-the-shelf approaches using thousands of hours of video. The WER is further reduced to 27.9% when using all 438 hours of labeled data from LRS3, which is on par with the state-of-the-art self-supervised AV-HuBERT method. Furthermore, when combined with large-scale pseudo-labeled audio-visual data SynthVSR yields a new state-of-the-art VSR WER of 16.9% using publicly available data only, surpassing the recent state-of-the-art approaches trained with 29 times more non-public machine-transcribed video data (90,000 hours). Finally, we perform extensive ablation studies to understand the effect of each component in our proposed method.
Auto-AVSR: Audio-Visual Speech Recognition with Automatic Labels
Mar 25, 2023



Audio-visual speech recognition has received a lot of attention due to its robustness against acoustic noise. Recently, the performance of automatic, visual, and audio-visual speech recognition (ASR, VSR, and AV-ASR, respectively) has been substantially improved, mainly due to the use of larger models and training sets. However, accurate labelling of datasets is time-consuming and expensive. Hence, in this work, we investigate the use of automatically-generated transcriptions of unlabelled datasets to increase the training set size. For this purpose, we use publicly-available pre-trained ASR models to automatically transcribe unlabelled datasets such as AVSpeech and VoxCeleb2. Then, we train ASR, VSR and AV-ASR models on the augmented training set, which consists of the LRS2 and LRS3 datasets as well as the additional automatically-transcribed data. We demonstrate that increasing the size of the training set, a recent trend in the literature, leads to reduced WER despite using noisy transcriptions. The proposed model achieves new state-of-the-art performance on AV-ASR on LRS2 and LRS3. In particular, it achieves a WER of 0.9% on LRS3, a relative improvement of 30% over the current state-of-the-art approach, and outperforms methods that have been trained on non-publicly available datasets with 26 times more training data.
Audio-Visual Synchronisation in the wild
Dec 08, 2021

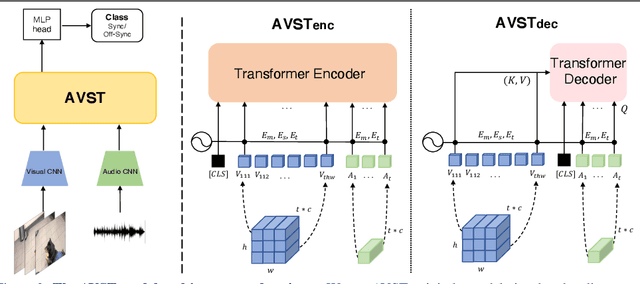
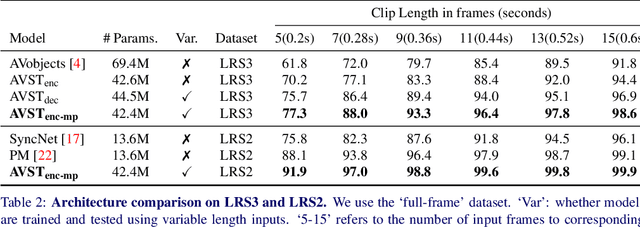
In this paper, we consider the problem of audio-visual synchronisation applied to videos `in-the-wild' (ie of general classes beyond speech). As a new task, we identify and curate a test set with high audio-visual correlation, namely VGG-Sound Sync. We compare a number of transformer-based architectural variants specifically designed to model audio and visual signals of arbitrary length, while significantly reducing memory requirements during training. We further conduct an in-depth analysis on the curated dataset and define an evaluation metric for open domain audio-visual synchronisation. We apply our method on standard lip reading speech benchmarks, LRS2 and LRS3, with ablations on various aspects. Finally, we set the first benchmark for general audio-visual synchronisation with over 160 diverse classes in the new VGG-Sound Sync video dataset. In all cases, our proposed model outperforms the previous state-of-the-art by a significant margin.