 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
Audio-visual fine-tuning of audio-only ASR models
Dec 14, 2023
Audio-visual automatic speech recognition (AV-ASR) models are very effective at reducing word error rates on noisy speech, but require large amounts of transcribed AV training data. Recently, audio-visual self-supervised learning (SSL) approaches have been developed to reduce this dependence on transcribed AV data, but these methods are quite complex and computationally expensive. In this work, we propose replacing these expensive AV-SSL methods with a simple and fast \textit{audio-only} SSL method, and then performing AV supervised fine-tuning. We show that this approach is competitive with state-of-the-art (SOTA) AV-SSL methods on the LRS3-TED benchmark task (within 0.5% absolute WER), while being dramatically simpler and more efficient (12-30x faster to pre-train). Furthermore, we show we can extend this approach to convert a SOTA audio-only ASR model into an AV model. By doing so, we match SOTA AV-SSL results, even though no AV data was used during pre-training.
An Exploration of In-Context Learning for Speech Language Model
Oct 19, 2023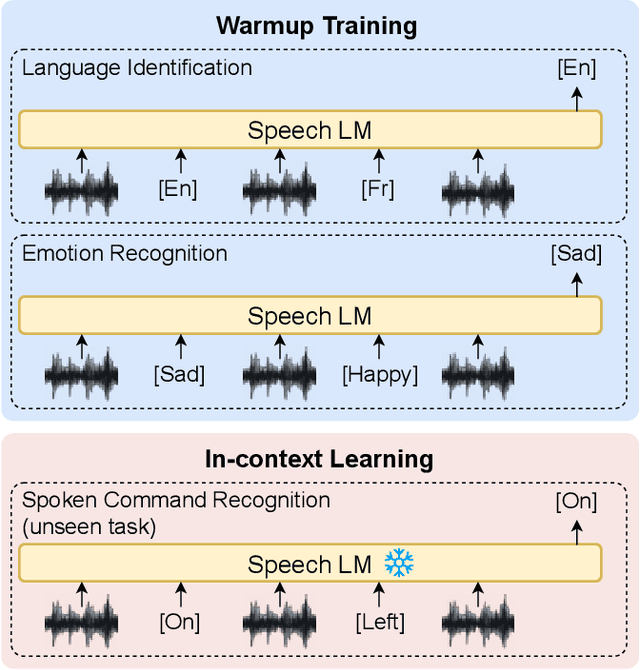
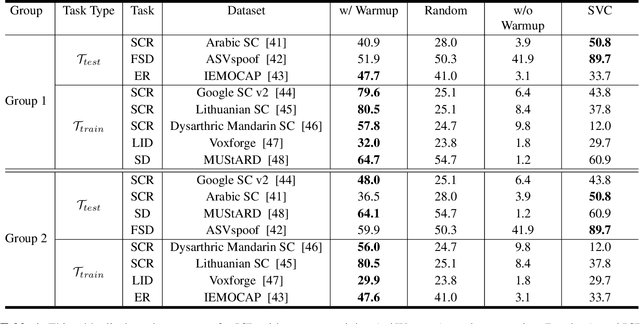
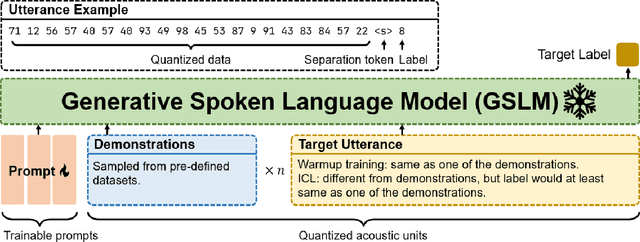
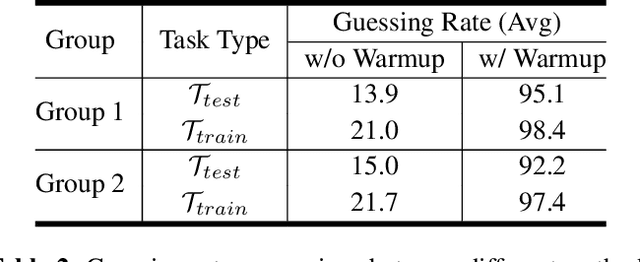
Ever since the development of GPT-3 in the natural language processing (NLP) field, in-context learning (ICL) has played an important role in utilizing large language models (LLMs). By presenting the LM utterance-label demonstrations at the input, the LM can accomplish few-shot learning without relying on gradient descent or requiring explicit modification of its parameters. This enables the LM to learn and adapt in a black-box manner. Despite the success of ICL in NLP, little work is exploring the possibility of ICL in speech processing. This study proposes the first exploration of ICL with a speech LM without text supervision. We first show that the current speech LM does not have the ICL capability. With the proposed warmup training, the speech LM can, therefore, perform ICL on unseen tasks. In this work, we verify the feasibility of ICL for speech LM on speech classification tasks.
AE-Flow: AutoEncoder Normalizing Flow
Dec 27, 2023Recently normalizing flows have been gaining traction in text-to-speech (TTS) and voice conversion (VC) due to their state-of-the-art (SOTA) performance. Normalizing flows are unsupervised generative models. In this paper, we introduce supervision to the training process of normalizing flows, without the need for parallel data. We call this training paradigm AutoEncoder Normalizing Flow (AE-Flow). It adds a reconstruction loss forcing the model to use information from the conditioning to reconstruct an audio sample. Our goal is to understand the impact of each component and find the right combination of the negative log-likelihood (NLL) and the reconstruction loss in training normalizing flows with coupling blocks. For that reason we will compare flow-based mapping model trained with: (i) NLL loss, (ii) NLL and reconstruction losses, as well as (iii) reconstruction loss only. Additionally, we compare our model with SOTA VC baseline. The models are evaluated in terms of naturalness, speaker similarity, intelligibility in many-to-many and many-to-any VC settings. The results show that the proposed training paradigm systematically improves speaker similarity and naturalness when compared to regular training methods of normalizing flows. Furthermore, we show that our method improves speaker similarity and intelligibility over the state-of-the-art.
TorchAudio 2.1: Advancing speech recognition, self-supervised learning, and audio processing components for PyTorch
Oct 27, 2023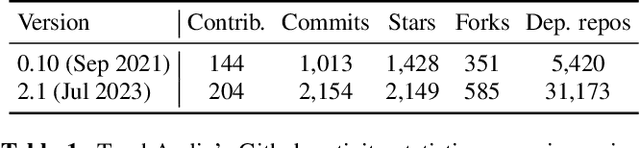


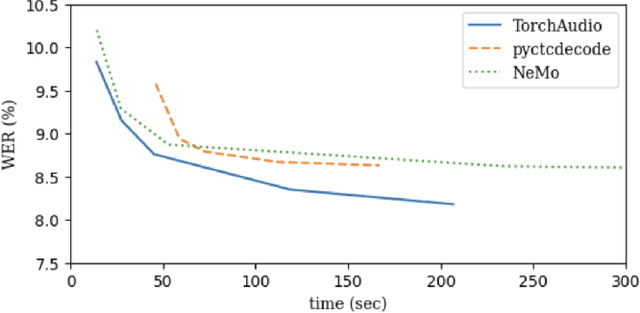
TorchAudio is an open-source audio and speech processing library built for PyTorch. It aims to accelerate the research and development of audio and speech technologies by providing well-designed, easy-to-use, and performant PyTorch components. Its contributors routinely engage with users to understand their needs and fulfill them by developing impactful features. Here, we survey TorchAudio's development principles and contents and highlight key features we include in its latest version (2.1): self-supervised learning pre-trained pipelines and training recipes, high-performance CTC decoders, speech recognition models and training recipes, advanced media I/O capabilities, and tools for performing forced alignment, multi-channel speech enhancement, and reference-less speech assessment. For a selection of these features, through empirical studies, we demonstrate their efficacy and show that they achieve competitive or state-of-the-art performance.
HCDIR: End-to-end Hate Context Detection, and Intensity Reduction model for online comments
Dec 20, 2023Warning: This paper contains examples of the language that some people may find offensive. Detecting and reducing hateful, abusive, offensive comments is a critical and challenging task on social media. Moreover, few studies aim to mitigate the intensity of hate speech. While studies have shown that context-level semantics are crucial for detecting hateful comments, most of this research focuses on English due to the ample datasets available. In contrast, low-resource languages, like Indian languages, remain under-researched because of limited datasets. Contrary to hate speech detection, hate intensity reduction remains unexplored in high-resource and low-resource languages. In this paper, we propose a novel end-to-end model, HCDIR, for Hate Context Detection, and Hate Intensity Reduction in social media posts. First, we fine-tuned several pre-trained language models to detect hateful comments to ascertain the best-performing hateful comments detection model. Then, we identified the contextual hateful words. Identification of such hateful words is justified through the state-of-the-art explainable learning model, i.e., Integrated Gradient (IG). Lastly, the Masked Language Modeling (MLM) model has been employed to capture domain-specific nuances to reduce hate intensity. We masked the 50\% hateful words of the comments identified as hateful and predicted the alternative words for these masked terms to generate convincing sentences. An optimal replacement for the original hate comments from the feasible sentences is preferred. Extensive experiments have been conducted on several recent datasets using automatic metric-based evaluation (BERTScore) and thorough human evaluation. To enhance the faithfulness in human evaluation, we arranged a group of three human annotators with varied expertise.
Long-form Simultaneous Speech Translation: Thesis Proposal
Oct 17, 2023Simultaneous speech translation (SST) aims to provide real-time translation of spoken language, even before the speaker finishes their sentence. Traditionally, SST has been addressed primarily by cascaded systems that decompose the task into subtasks, including speech recognition, segmentation, and machine translation. However, the advent of deep learning has sparked significant interest in end-to-end (E2E) systems. Nevertheless, a major limitation of most approaches to E2E SST reported in the current literature is that they assume that the source speech is pre-segmented into sentences, which is a significant obstacle for practical, real-world applications. This thesis proposal addresses end-to-end simultaneous speech translation, particularly in the long-form setting, i.e., without pre-segmentation. We present a survey of the latest advancements in E2E SST, assess the primary obstacles in SST and its relevance to long-form scenarios, and suggest approaches to tackle these challenges.
Toward Joint Language Modeling for Speech Units and Text
Oct 12, 2023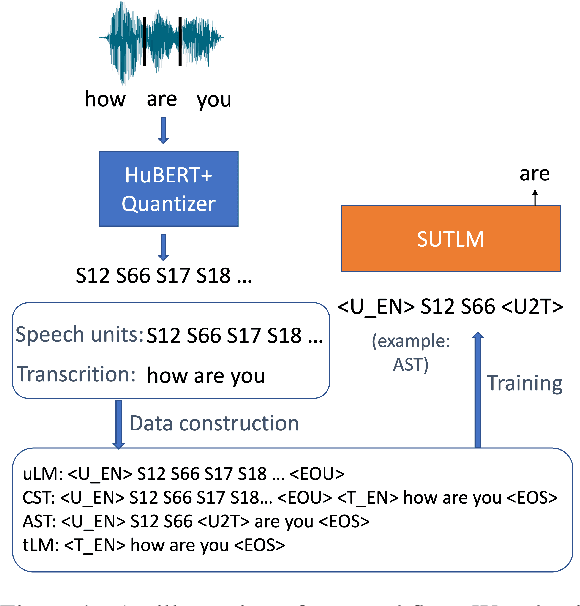


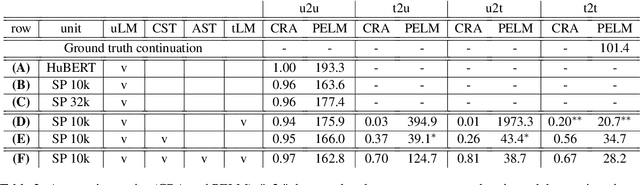
Speech and text are two major forms of human language. The research community has been focusing on mapping speech to text or vice versa for many years. However, in the field of language modeling, very little effort has been made to model them jointly. In light of this, we explore joint language modeling for speech units and text. Specifically, we compare different speech tokenizers to transform continuous speech signals into discrete units and use different methods to construct mixed speech-text data. We introduce automatic metrics to evaluate how well the joint LM mixes speech and text. We also fine-tune the LM on downstream spoken language understanding (SLU) tasks with different modalities (speech or text) and test its performance to assess the model's learning of shared representations. Our results show that by mixing speech units and text with our proposed mixing techniques, the joint LM improves over a speech-only baseline on SLU tasks and shows zero-shot cross-modal transferability.
Intuitive Multilingual Audio-Visual Speech Recognition with a Single-Trained Model
Oct 23, 2023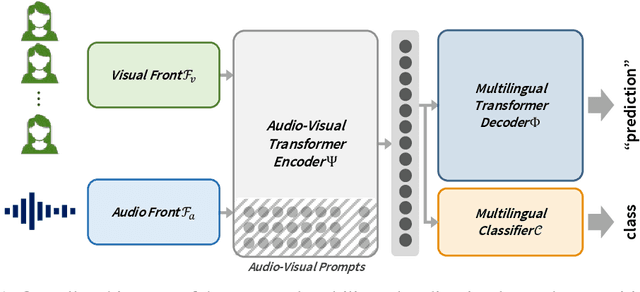
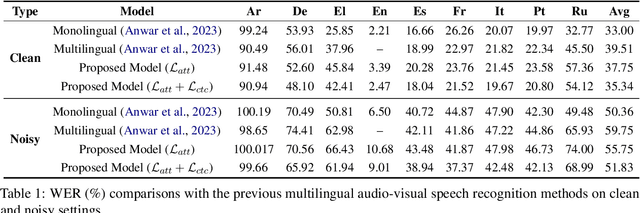
We present a novel approach to multilingual audio-visual speech recognition tasks by introducing a single model on a multilingual dataset. Motivated by a human cognitive system where humans can intuitively distinguish different languages without any conscious effort or guidance, we propose a model that can capture which language is given as an input speech by distinguishing the inherent similarities and differences between languages. To do so, we design a prompt fine-tuning technique into the largely pre-trained audio-visual representation model so that the network can recognize the language class as well as the speech with the corresponding language. Our work contributes to developing robust and efficient multilingual audio-visual speech recognition systems, reducing the need for language-specific models.
Joint Audio and Speech Understanding
Oct 02, 2023Humans are surrounded by audio signals that include both speech and non-speech sounds. The recognition and understanding of speech and non-speech audio events, along with a profound comprehension of the relationship between them, constitute fundamental cognitive capabilities. For the first time, we build a machine learning model, called LTU-AS, that has a conceptually similar universal audio perception and advanced reasoning ability. Specifically, by integrating Whisper as a perception module and LLaMA as a reasoning module, LTU-AS can simultaneously recognize and jointly understand spoken text, speech paralinguistics, and non-speech audio events - almost everything perceivable from audio signals.
Label-Synchronous Neural Transducer for Adaptable Online E2E Speech Recognition
Nov 19, 2023Although end-to-end (E2E) automatic speech recognition (ASR) has shown state-of-the-art recognition accuracy, it tends to be implicitly biased towards the training data distribution which can degrade generalisation. This paper proposes a label-synchronous neural transducer (LS-Transducer), which provides a natural approach to domain adaptation based on text-only data. The LS-Transducer extracts a label-level encoder representation before combining it with the prediction network output. Since blank tokens are no longer needed, the prediction network performs as a standard language model, which can be easily adapted using text-only data. An Auto-regressive Integrate-and-Fire (AIF) mechanism is proposed to generate the label-level encoder representation while retaining low latency operation that can be used for streaming. In addition, a streaming joint decoding method is designed to improve ASR accuracy while retaining synchronisation with AIF. Experiments show that compared to standard neural transducers, the proposed LS-Transducer gave a 12.9% relative WER reduction (WERR) for intra-domain LibriSpeech data, as well as 21.4% and 24.6% relative WERRs on cross-domain TED-LIUM 2 and AESRC2020 data with an adapted prediction network.